
[ad_1]

|
Final yr at re:Invent, we launched the preview of Amazon Redshift Serverless, a serverless possibility of Amazon Redshift that allows you to analyze information at any scale with out having to handle information warehouse infrastructure. You simply must load and question your information, and also you pay just for what you utilize. This enables extra firms to construct a contemporary information technique, particularly to be used circumstances the place analytics workloads will not be working 24-7 and the info warehouse shouldn’t be energetic on a regular basis. It’s also relevant to firms the place using information expands inside the group and customers in new departments need to run analytics with out having to take possession of information warehouse infrastructure.
Right now, I’m completely happy to share that Amazon Redshift Serverless is usually obtainable and that we added many new capabilities. We’re additionally lowering Amazon Redshift Serverless compute prices in comparison with the preview.
Now you can create a number of serverless endpoints per AWS account and Area utilizing namespaces and workgroups:
- A namespace is a set of database objects and customers, corresponding to database title and password, permissions, and encryption configuration. That is the place your information is managed and the place you possibly can see how a lot storage is used.
- A workgroup is a set of compute sources, together with community and safety settings. Every workgroup has a serverless endpoint to which you’ll join your purposes. When configuring a workgroup, you possibly can arrange personal or publicly accessible endpoints.
Every namespace can have just one workgroup related to it. Conversely, every workgroup might be related to just one namespace. You may have a namespace with none workgroup related to it, for instance, to make use of it just for sharing information with different namespaces in the identical or one other AWS account or Area.
In your workgroup configuration, now you can use question monitoring guidelines to assist hold your prices underneath management. Additionally, the way in which Amazon Redshift Serverless routinely scales information warehouse capability is extra clever to ship quick efficiency for demanding and unpredictable workloads.
Let’s see how this works with a fast demo. Then, I’ll present you what you are able to do with namespaces and workgroups.
Utilizing Amazon Redshift Serverless
Within the Amazon Redshift console, I choose Redshift serverless within the navigation pane. To get began, I select Use default settings to configure a namespace and a workgroup with the most typical choices. For instance, I’ll be capable to join utilizing my default VPC and default safety group.

With the default settings, the one possibility left to configure is Permissions. Right here, I can specify how Amazon Redshift can work together with different companies corresponding to S3, Amazon CloudWatch Logs, Amazon SageMaker, and AWS Glue. To load information later, I give Amazon Redshift entry to an S3 bucket. I select Handle IAM roles after which Create IAM function.
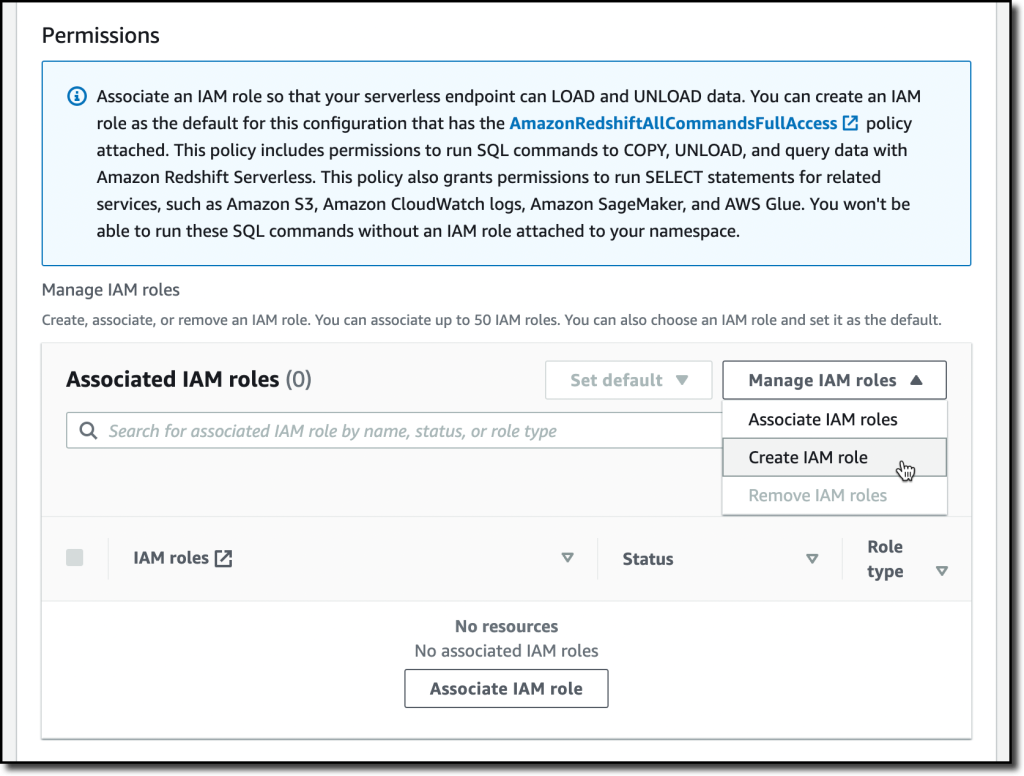
When creating the IAM function, I choose the choice to offer entry to particular S3 buckets and choose an S3 bucket in the identical AWS Area. Then, I select Create IAM function as default to finish the creation of the function and to routinely use it because the default function for the namespace.
I select Save configuration and after a couple of minutes the database is prepared to be used. Within the Serverless dashboard, I select Question information to open the Redshift question editor v2. There, I observe the directions within the Amazon Redshift Database Developer information to load a pattern database. If you wish to do a fast take a look at, a number of pattern databases (together with the one I’m utilizing right here) are already obtainable within the sample_data_dev database. Be aware additionally that loading information into Amazon Redshift shouldn’t be required for working queries. I can use information from an S3 information lake in my queries by creating an exterior schema and an exterior desk.
The pattern database consists of seven tables and tracks gross sales exercise for a fictional “TICKIT” web site, the place customers purchase and promote tickets for sporting occasions, exhibits, and concert events.
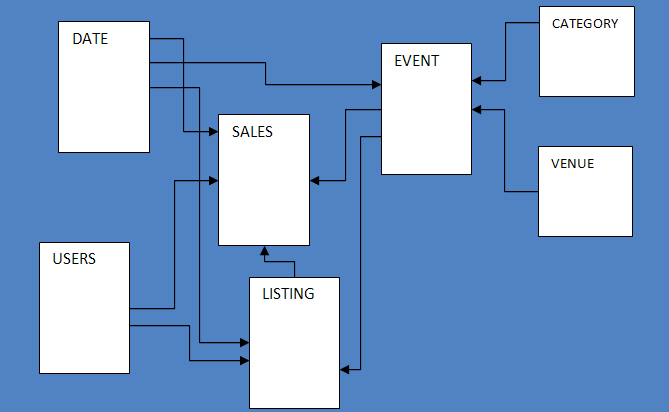
To configure the database schema, I run a number of SQL instructions to create the customers, venue, class, date, occasion, itemizing, and gross sales tables.
Then, I obtain the tickitdb.zip file that comprises the pattern information for the database tables. I unzip and cargo the information to a tickit folder in the identical S3 bucket I used when configuring the IAM function.
Now, I can use the COPY command to load the info from the S3 bucket into my database. For instance, to load information into the customers desk:
copy customers from 's3://MYBUCKET/tickit/allusers_pipe.txt' iam_role default;
The file containing the info for the gross sales desk makes use of tab-separated values:
copy gross sales from 's3://MYBUCKET/tickit/sales_tab.txt' iam_role default delimiter 't' timeformat 'MM/DD/YYYY HH:MI:SS';After I load information in all tables, I begin working some queries. For instance, the next question joins 5 tables to search out the highest 5 sellers for occasions primarily based in California (observe that the pattern information is for the yr 2008):
choose sellerid, username, (firstname ||' '|| lastname) as sellername, venuestate, sum(qtysold)
from gross sales, date, customers, occasion, venue
the place gross sales.sellerid = customers.userid
and gross sales.dateid = date.dateid
and gross sales.eventid = occasion.eventid
and occasion.venueid = venue.venueid
and yr = 2008
and venuestate="CA"
group by sellerid, username, sellername, venuestate
order by 5 desc
restrict 5;
Now that my database is prepared, let’s see what I can do by configuring Amazon Redshift Serverless namespaces and workgroups.
Utilizing and Configuring Namespaces
Namespaces are collections of database information and their safety configurations. Within the navigation pane of the Amazon Redshift console, I select Namespace configuration. Within the checklist, I select the default namespace that I simply created.
Within the Knowledge backup tab, I can create or restore a snapshot or restore information from one of many restoration factors which are routinely created each 30 minutes and saved for 24 hours. That may be helpful to get better information in case of unintended writes or deletes.
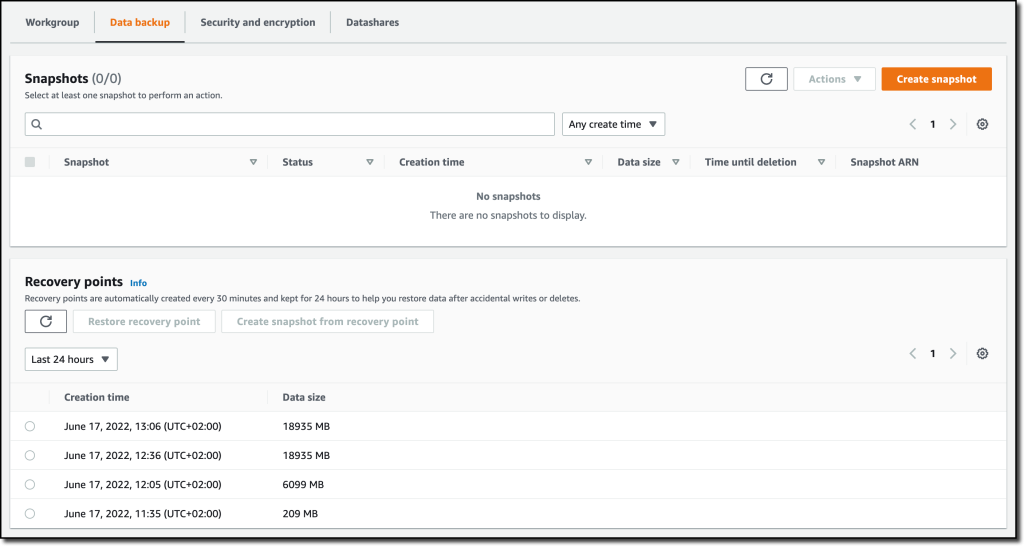
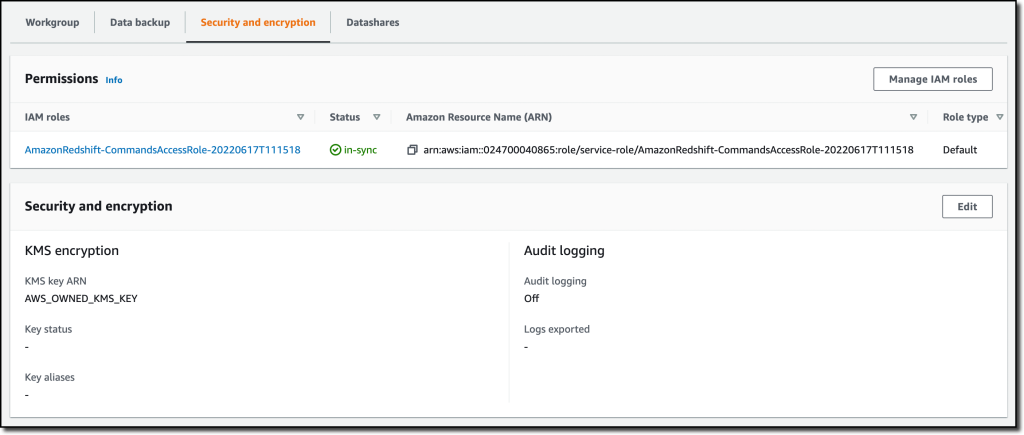
Within the Safety and encryption tab, I can replace permissions and encryption settings, together with the AWS Key Administration Service (AWS KMS) key used to encrypt and decrypt my sources. On this tab, I may also allow audit logging and export the person, connection, and person exercise logs to CloudWatch Logs.
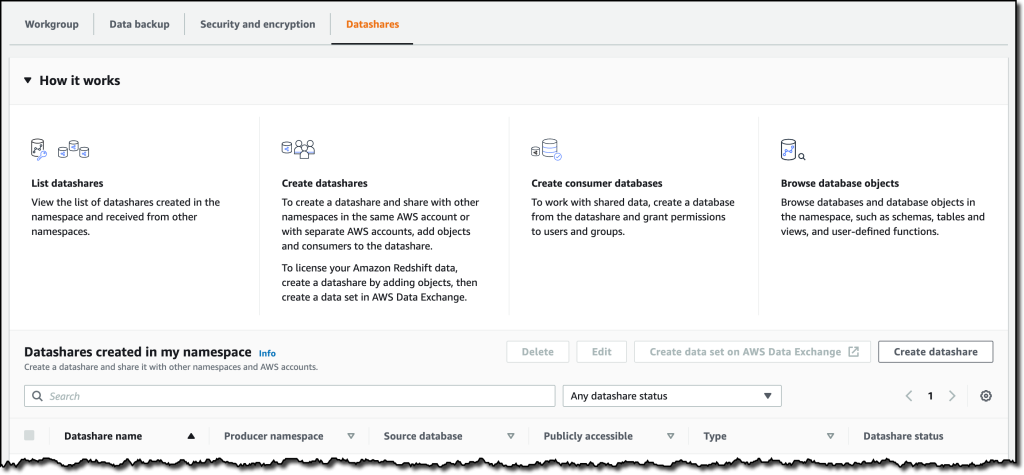
Within the Datashares tab, I can create a datashare to share information with different namespaces and AWS accounts in the identical or totally different Areas. On this tab, I may also create a database from a share I obtain from different namespaces or AWS accounts, and I can see the subscriptions for datashares managed by AWS Knowledge Trade.
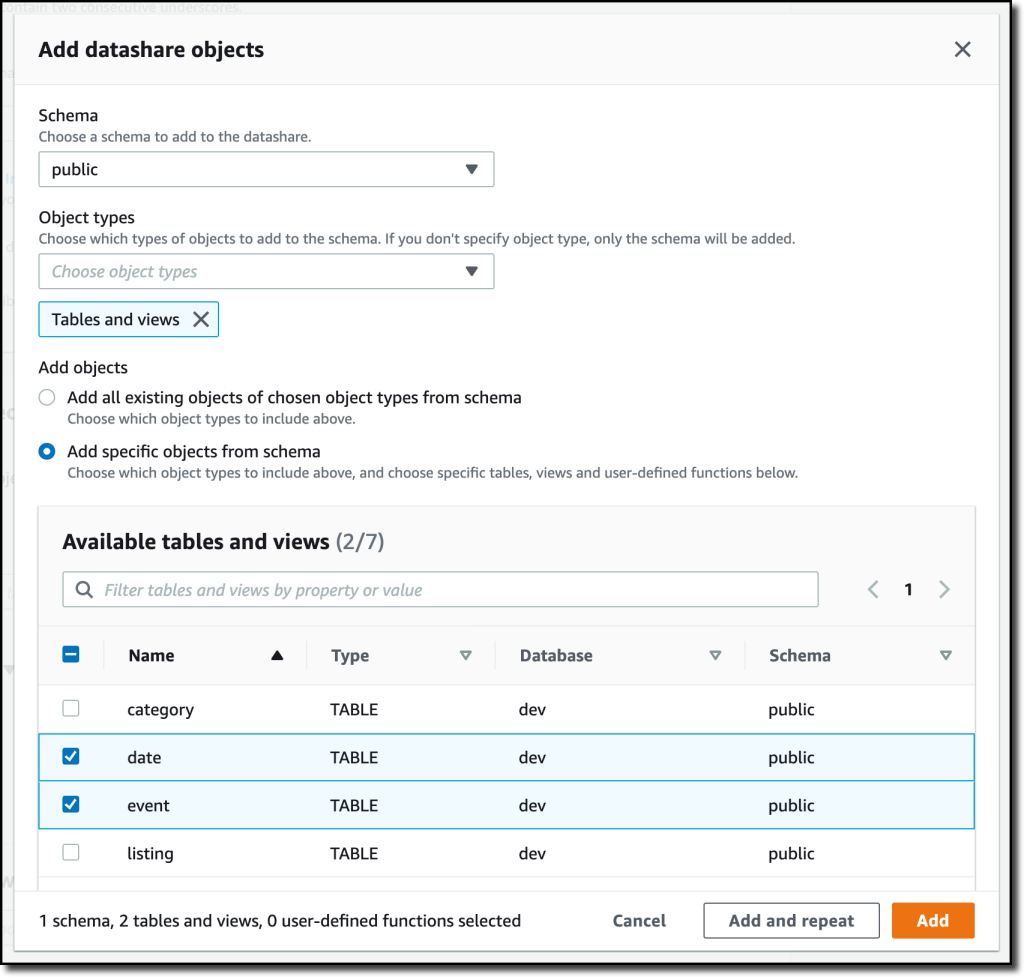
Once I create a datashare, I can choose which objects to incorporate. For instance, right here I need to share solely the date and occasion tables as a result of they don’t comprise delicate information.
Utilizing and Configuring Workgroups
Workgroups are collections of compute sources and their community and safety settings. They supply the serverless endpoint for the namespace they’re configured for. Within the navigation pane of the Amazon Redshift console, I select Workgroup configuration. Within the checklist, I select the default namespace that I simply created.
Within the Knowledge entry tab, I can replace the community and safety settings (for instance, change the VPC, the subnets, or the safety group) or make the endpoint publicly accessible. On this tab, I may also allow Enhanced VPC routing to route community site visitors between my serverless database and the info repositories I exploit (for instance, the S3 buckets used to load or unload information) by a VPC as a substitute of the web. To entry serverless endpoints which are in one other VPC or subnet, I can create a VPC endpoint managed by Amazon Redshift.
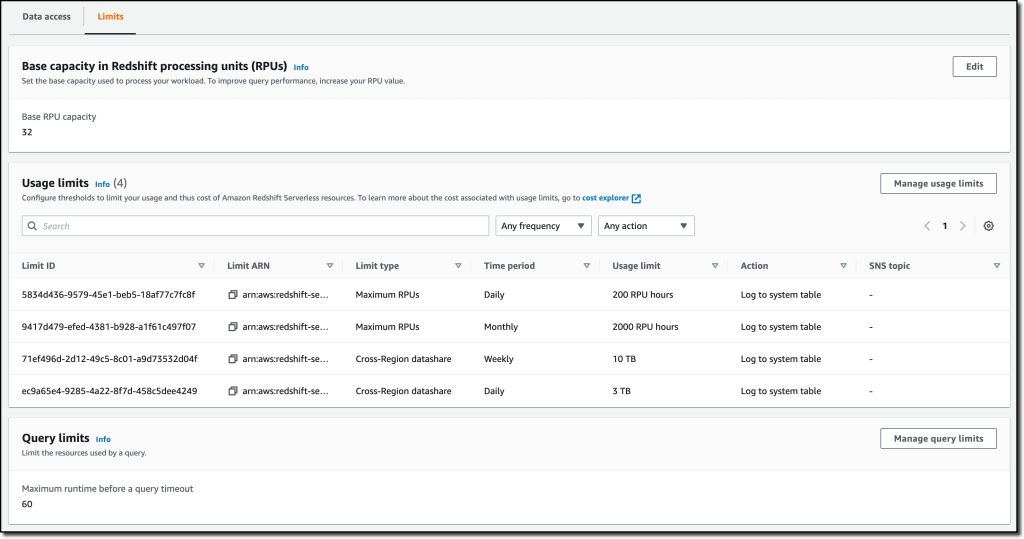
Within the Limits tab, I can configure the bottom capability (expressed in Redshift processing models, or RPUs) used to course of my queries. Amazon Redshift Serverless scales the capability to cope with the next variety of customers. Right here I even have the choice to extend the bottom capability to hurry up my queries or lower it to scale back prices.
On this tab, I may also set Utilization limits to configure day by day, weekly, and month-to-month thresholds to maintain my prices predictable. For instance, I configured a day by day restrict of 200 RPU-hours, and a month-to-month restrict of two,000 RPU-hours for my compute sources. To regulate the data-transfer prices for cross-Area datashares, I configured a day by day restrict of three TB and a weekly restrict of 10 TB. Lastly, to restrict the sources utilized by every question, I exploit Question limits to trip queries working for greater than 60 seconds.
Availability and Pricing
Amazon Redshift Serverless is mostly obtainable at the moment within the US East (Ohio), US East (N. Virginia), US West (Oregon), Europe (Frankfurt), Europe (Eire), Europe (London), Europe (Stockholm), and Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), and Asia Pacific (Tokyo) AWS Areas.
You may hook up with a workgroup endpoint utilizing your favourite shopper instruments by way of JDBC/ODBC or with the Amazon Redshift question editor v2, a web-based SQL shopper software obtainable on the Amazon Redshift console. When utilizing net services-based purposes (corresponding to AWS Lambda capabilities or Amazon SageMaker notebooks), you possibly can entry your database and carry out queries utilizing the built-in Amazon Redshift Knowledge API.
With Amazon Redshift Serverless, you pay just for the compute capability your database consumes when energetic. The compute capability scales up or down routinely primarily based in your workload and shuts down during times of inactivity to save lots of time and prices. Your information is saved in managed storage, and also you pay a GB-month charge.
To present you improved worth efficiency and the pliability to make use of Amazon Redshift Serverless for an excellent broader set of use circumstances, we’re reducing the worth from $zero.5 to $zero.375 per RPU-hour for the US East (N. Virginia) Area. Equally, we’re reducing the worth in different Areas by a median of 25 % from the preview worth. For extra data, see the Amazon Redshift pricing web page.
That will help you get observe with your personal use circumstances, we’re additionally offering $300 in AWS credit for 90 days to strive Amazon Redshift Serverless. These credit are used to cowl your prices for compute, storage, and snapshot utilization of Amazon Redshift Serverless solely.
Get insights out of your information in seconds with Amazon Redshift Serverless.
— Danilo
[ad_2]
Source link

