[ad_1]

|
At AWS re:Invent 2021, we launched three new serverless choices for our information analytics providers – Amazon EMR Serverless, Amazon Redshift Serverless, and Amazon MSK Serverless – that make it simpler to research information at any scale with out having to configure, scale, or handle the underlying infrastructure.
In the present day we announce the overall availability of Amazon EMR Serverless, a serverless deployment possibility for purchasers to run large information analytics purposes utilizing open-source frameworks like Apache Spark and Hive with out configuring, managing, and scaling clusters or servers.

With EMR Serverless, you may run analytics workloads at any scale with automated scaling that resizes sources in seconds to satisfy altering information volumes and processing necessities. EMR Serverless routinely scales sources up and down to supply simply the correct amount of capability to your software, and also you solely pay for what you utilize.
Throughout the preview, we heard from clients that EMR Serverless is cost-effective as a result of they don’t incur price from having to overprovision sources to take care of demand spikes. They don’t have to fret about right-sizing situations or making use of OS updates, and may deal with getting merchandise to market quicker.
Amazon EMR supplies varied deployment choices to run purposes to suit various wants corresponding to EMR clusters on Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Kubernetes Service (Amazon EKS) clusters, AWS Outposts, or EMR Serverless.
- EMR on Amazon EC2 clusters is appropriate for purchasers that want most management and adaptability over run their software. With EMR clusters, clients can select the EC2 occasion sort to boost the efficiency of sure purposes, customise the Amazon Machine Picture (AMI), select EC2 occasion configuration, customise, and lengthen open-source frameworks and set up extra customized software program on cluster situations.
- EMR on Amazon EKS is appropriate for purchasers that need to standardize on EKS to handle clusters throughout purposes or use totally different variations of an open-source framework on the identical cluster.
- EMR on AWS Outposts is for purchasers who need to run EMR nearer to their information heart inside an Outpost.
- EMR Serverless is appropriate for purchasers that need to keep away from managing and working clusters, and easily need to run purposes utilizing open-source frameworks.
Additionally, once you construct an software utilizing an EMR launch (for instance, a Spark job utilizing EMR launch 6.four), you may select to run it on an EMR cluster, EMR on EKS, or EMR Serverless with out having to rewrite the applying. This lets you construct purposes for a given framework model and retain the flexibleness to alter the deployment mannequin primarily based on future operational wants.
Getting Began with Amazon EMR Serverless
To get began with EMR Serverless, you should utilize Amazon EMR Studio, a free EMR characteristic which supplies an finish to finish growth and debugging expertise. With EMR Studio, you may create EMR Serverless purposes (Spark or Hive), select the model of open-source software program to your software, submit jobs, verify the standing of operating jobs, and invoke Spark UI or Tez UI for job diagnostics.
When you choose the Get began button within the EMR Serverless Console, you may create and arrange EMR Studio with preconfigured EMR Serverless purposes.
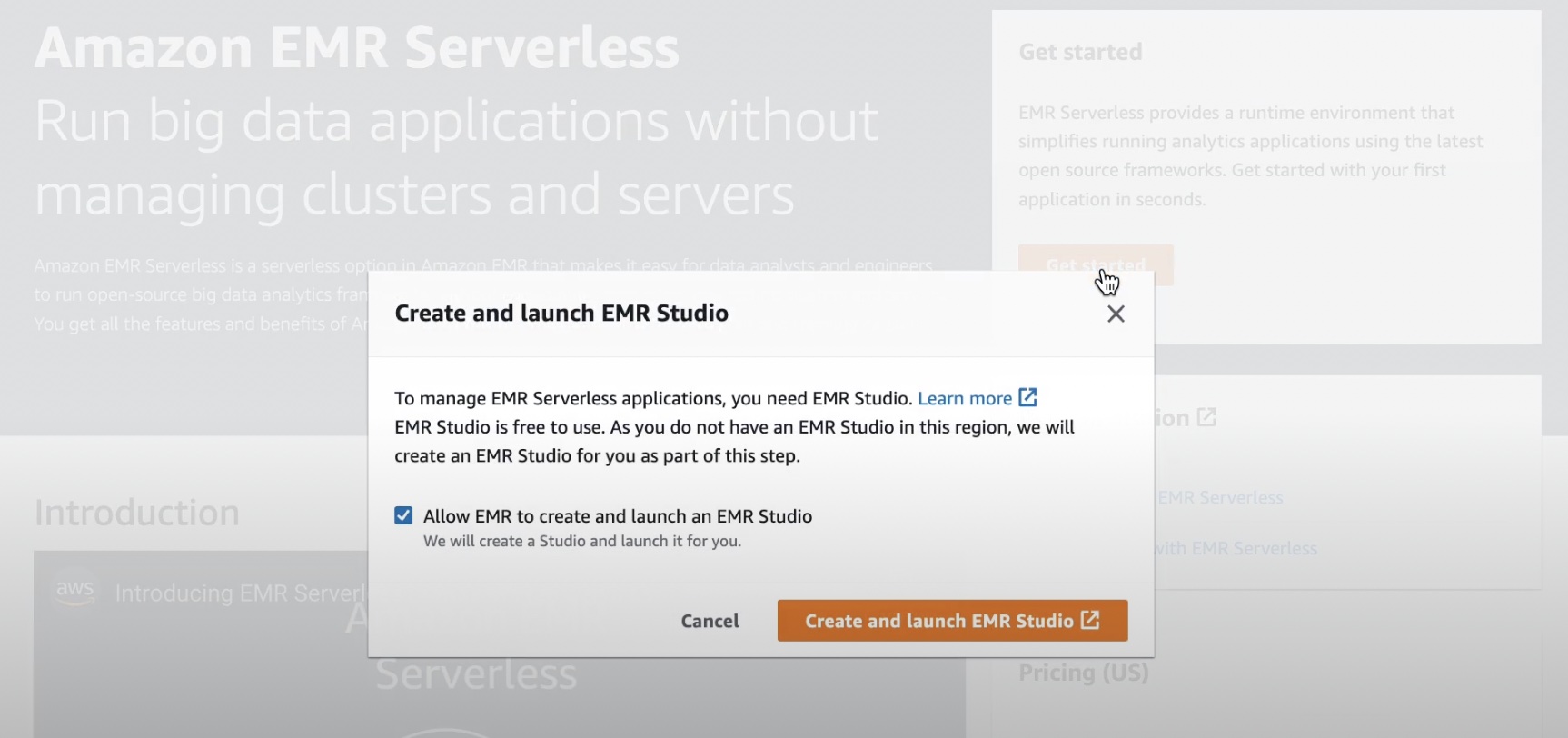
In EMR Studio, once you select Functions within the Serverless menu, you may create a number of EMR Serverless purposes and select the open supply framework and model to your use case. If you would like separate logical environments for take a look at and manufacturing or for various line-of-business use circumstances, you may create separate purposes for every logical atmosphere.
An EMR Serverless software is a mix of (a) the EMR launch model for the open-source framework model you need to use and (b) the particular runtime that you really want your software to make use of, corresponding to Apache Spark or Apache Hive.
If you select Create software, you may set your software Title, Sort of both Spark or Hive, and supported Release model. You may as well choose the choice of default or customized settings for pre-initialized capability, software limits, and Amazon Digital Personal Cloud (Amazon VPC) connectivity choices. Every EMR Serverless software is remoted from different purposes and runs inside a safe VPC.
Use the default possibility if you need jobs to begin instantly. However fees apply for every employee when the applying is began. To be taught extra about pre-initialized capability, see Configuring and managing pre-initialized capability.
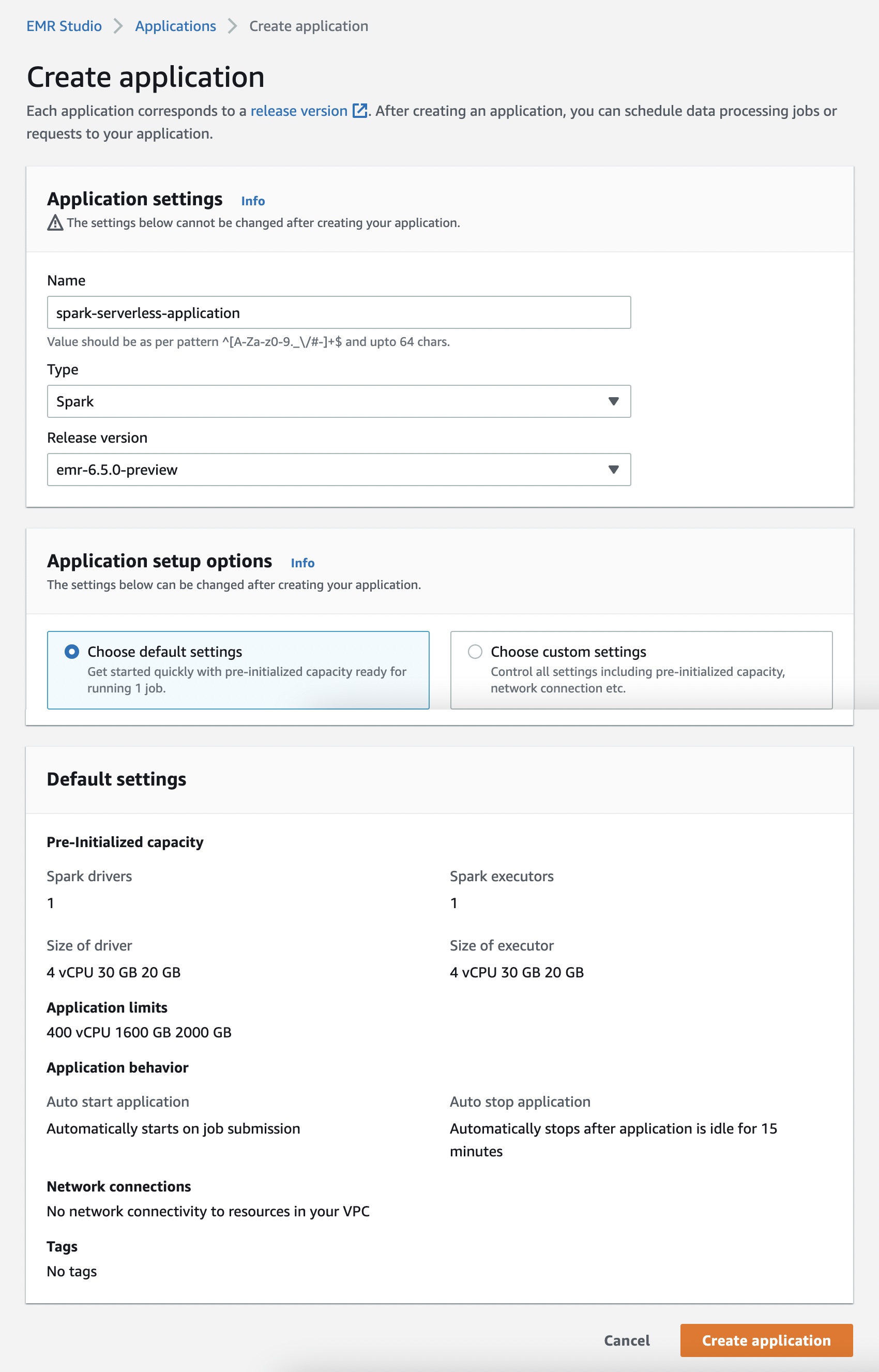
When you choose Begin software, your software is setup to begin with pre-initialized capability of 1 Spark driver and 1 Spark executor. Your software is by default configured to begin when jobs are submitted and cease when the applying is idle for greater than 15 minutes.
You may customise these settings and setup totally different software limits by choosing Select customized settings.
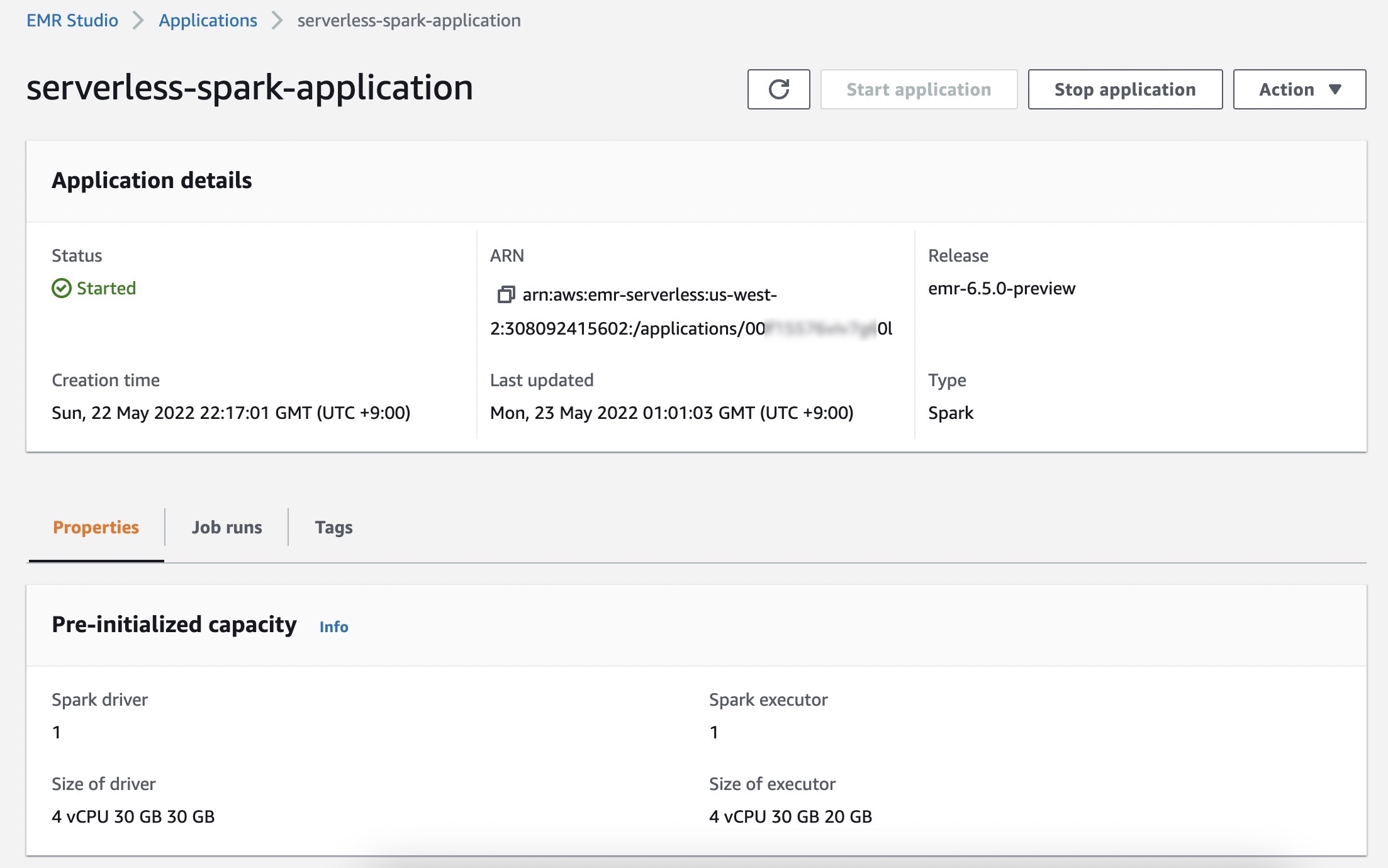
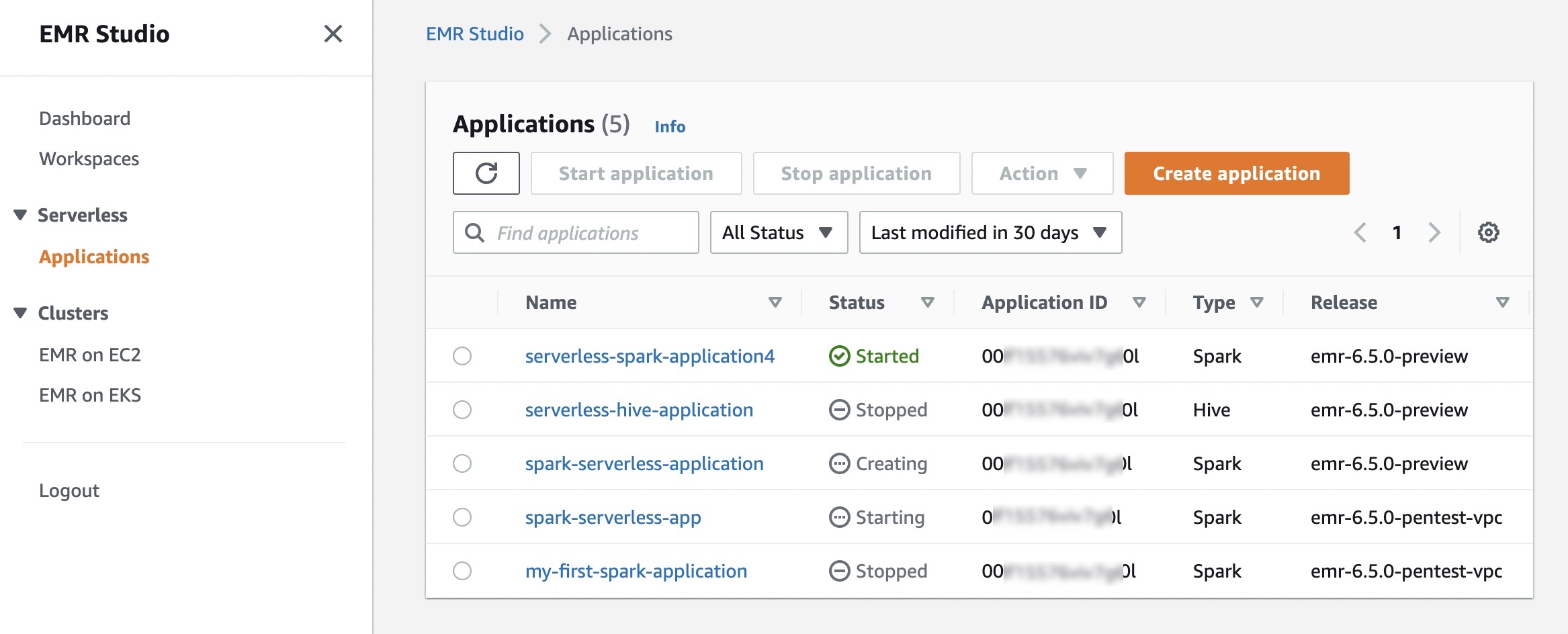
Within the Job runs menu, you may see a listing of run jobs to your software.
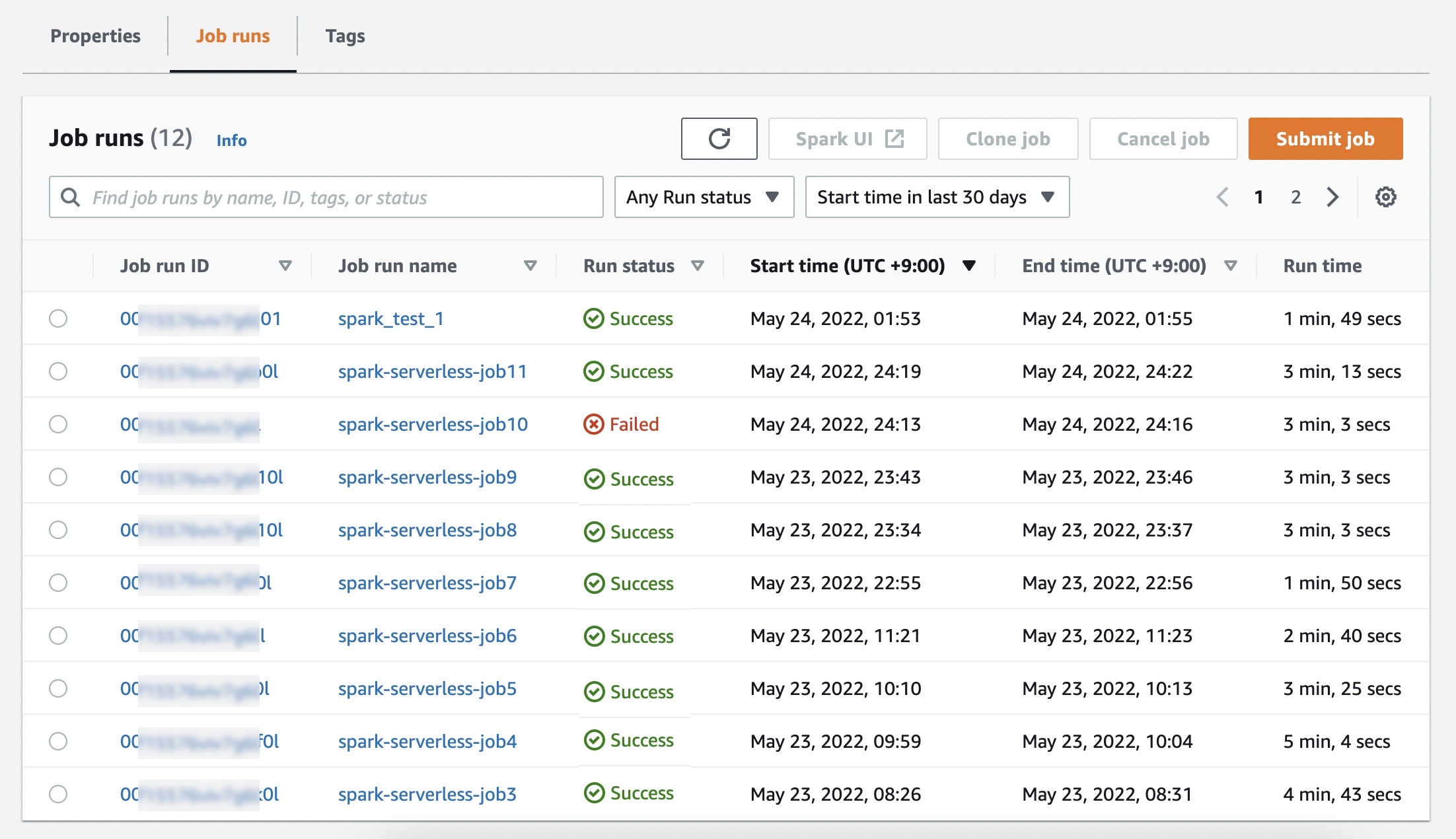
Select Submit job and arrange job particulars such because the identify, AWS Id and Entry Administration (IAM) position utilized by the job, script location, and arguments of the JAR or Python script within the Amazon Easy Storage Service (Amazon S3) bucket that you just need to run.
If you would like logs to your Spark or Hive jobs to be submitted to your S3 bucket, you’ll need to setup the S3 bucket in the identical Area the place you’re operating EMR Serverless jobs.
Optionally, you may set extra configuration properties you can specify for every job, corresponding to Spark properties, job configurations to override the default configurations for purposes (corresponding to utilizing the AWS Glue Information Catalog as its metastore), storing logs to Amazon S3, and retaining logs for 30 days.
The next is an instance of operating a Python script utilizing the StartJobRun API.
$ aws emr-serverless start-job-run
--application-id <application_id>
--execution-role-arn <iam_role_arn>
--job-driver ''
--configuration-overrides '
"monitoringConfiguration":
"s3MonitoringConfiguration":
'You may verify on job ends in your S3 bucket. For particulars, you should utilize Spark UI for Spark Software, and Hive/Tez UI within the Job runs menu to know how the job ran or to debug it if it failed.
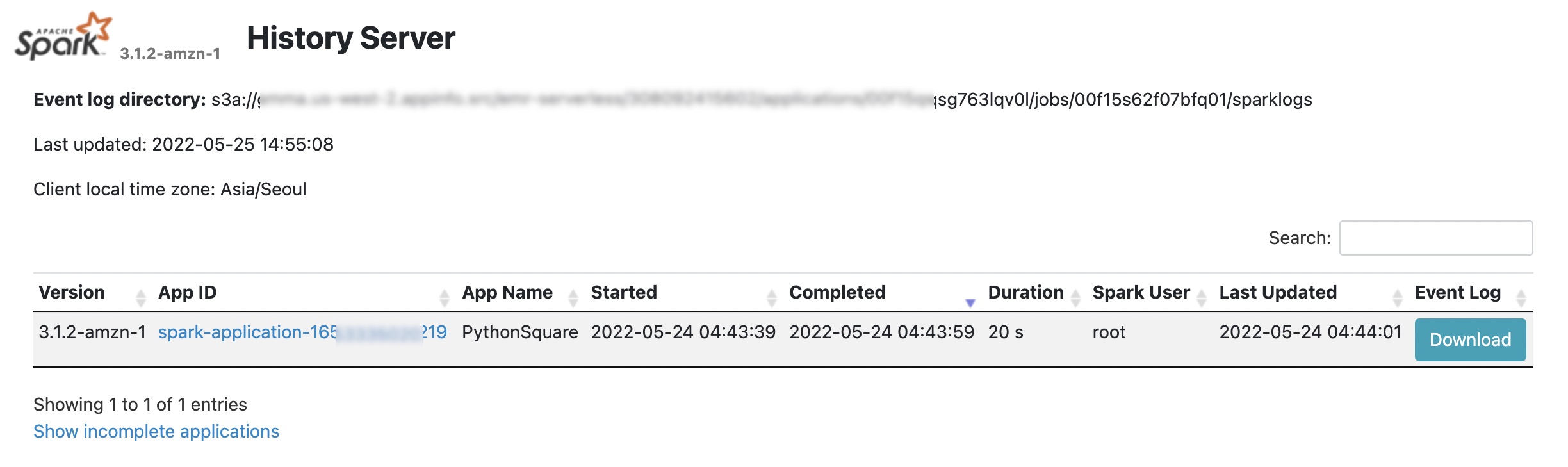
For extra debugging, EMR Serverless will push occasion logs to the sparklogs folder in your S3 log vacation spot for Spark purposes. Within the case of Hive purposes, EMR Serverless will repeatedly add the Hive driver and Tez duties logs to the HIVE_DRIVER or TEZ_TASK folders of your S3 log vacation spot. To be taught extra, see Logging within the AWS documentation.
Issues to Know
With EMR Serverless, you will get all the advantages of operating Amazon EMR. I need to quote some issues to find out about EMR Serverless from an AWS Huge Information Weblog publish of preview bulletins:
- Computerized and fine-grained scaling – EMR Serverless routinely scales up staff at every stage of processing your job and scales them down once they’re not required. You’re charged for mixture vCPU, reminiscence, and storage sources used from the time a employee begins operating till it stops, rounded as much as the closest second with a 1-minute minimal. For instance, your job might require 10 staff for the primary 10 minutes of processing the job and 50 staff for the following 5 minutes. With fine-grained automated scaling, you solely incur price for 10 staff for 10 minutes and 50 staff for five minutes. Because of this, you don’t need to pay for underutilized sources.
- Resilience to Availability Zone failures – EMR Serverless is a Regional service. If you submit jobs to an EMR Serverless software, it might probably run in any Availability Zone within the Area. In case an Availability Zone is impaired, a job submitted to your EMR Serverless software is routinely run in a unique (wholesome) Availability Zone. When utilizing sources in a non-public VPC, EMR Serverless recommends that you just specify the personal VPC configuration for a number of Availability Zones in order that EMR Serverless can routinely choose a wholesome Availability Zone.
- Allow shared purposes – If you submit jobs to an EMR Serverless software, you may specify the IAM position that should be utilized by the job to entry AWS sources corresponding to S3 objects. Because of this, totally different IAM principals can run jobs on a single EMR Serverless software, and every job can solely entry the AWS sources that the IAM principal is allowed to entry. This allows you to arrange eventualities the place a single software with a pre-initialized pool of staff is made accessible to a number of tenants whereby every tenant can submit jobs utilizing a unique IAM position however use the frequent pool of pre-initialized staff to right away course of requests.
Now Obtainable
Amazon EMR Serverless is offered in US East (N. Virginia), US West (Oregon), Europe (Eire), and Asia Pacific (Tokyo) Areas. With EMR Serverless, there are not any upfront prices, and also you pay just for the sources you utilize. You pay for the quantity of vCPU, reminiscence, and storage sources consumed by your purposes. For pricing particulars, see the EMR Serverless pricing web page.
To be taught extra, go to the Amazon EMR Serverless Consumer Information and pattern codes with Apache Spark and Apache Hive. Please ship suggestions to AWS re:Publish for Amazon EMR Serverless or via your common AWS help contacts.
Be taught all the small print about Amazon EMR Serverless and get began at present.
– Channy
[ad_2]
Source link





