
[ad_1]
This text is the ultimate within the three half collection to discover the efficiency debugging ecosystem of PyTorch/XLA on Google Cloud TPU VM. Within the first half, we launched the important thing idea to cause concerning the coaching efficiency utilizing PyTorch/XLA profiler and ended with an attention-grabbing efficiency bottleneck we encountered within the Multi-Head-Consideration (MHA) implementation in PyTorch 1.eight. Within the second half, we started with one other implementation of MHA launched in PyTorch 1.9 which solved the efficiency bottleneck and recognized an instance of Dynamic Graph throughout analysis utilizing the profiler and studied a doable trade-off between CompileTime penalty with ‘device-to-host’ transfers.
On this half, we shift gears to server-side profiling. Recall from consumer and server terminology launched within the first half, the server facet performance refers to all of the computations that occur at TPU Runtime (aka XRT server) and past (on TPU gadget). Typically, the target of such an evaluation is to peek into efficiency of a sure op, or a sure part of your mannequin on TPUs. PyTorch/XLA facilitates this with person annotations which could be inserted within the supply code and could be visualized as a hint utilizing Tensorboard.
Setting setup
We proceed to make use of the mmf (multimodal framework) instance used within the first two components. If you’re beginning with this half, please check with the Setting Setup part of part-1 to create a TPU VM and proceed from the TensorBoard Setup described on this publish. We recap the instructions right here for straightforward entry
Creation of TPU VM occasion (if not already created):
Right here is the command to SSH into the occasion as soon as the occasion is created.
TensorBoard setup
Discover the ssh flag argument for ssh tunneled port forwarding. This lets you connect with the appliance server listening to port 9009 through localhost:9009 by yourself browser. To setup TensorBoard model appropriately and keep away from battle with different native model, please uninstall the prevailing TensorBoard model first:
Within the present context the appliance server is the TensorBoard occasion listening to port 9009:
It will begin the TensorBoard server accessible through localhost:9009 in your browser. Discover that no profiling knowledge is collected but. Comply with the directions from the person information to open the PROFILE view localhost:9009.
Coaching setup
We anchor to the PyTorch / XLA 1.9 setting for this case research.
Replace different (make python3 default):
Configure setting variables:
MMF coaching setting
The MMF (Multimodal Coaching Framework) library developed by Meta Analysis is constructed to assist researchers simply experiment with the fashions for multi-modal (textual content/picture/audio) studying issues. As described within the roadmap we are going to use the UniTransformer mannequin for this case research. We’ll start by cloning and putting in the mmf library (particular hash chosen for reproducibility functions).
Earlier than we set up the mmf library in developer mode, please make the next modifications within the requirement.txt (such that the prevailing PyTorch setting shouldn’t be overridden when mmf is put in):
Apply the next patch for validate_batch_sizes technique (Particular to the commit chosen for this text):
Set up the mmf library in developer mode:
Hint API
The PyTorch/XLA profiler offers two major APIs (StepTrace, Hint) that can assist you analyze the totally different segments of your code by way of annotations which may later be visualized utilizing TensorBoard. To make use of StepTrace or Hint, first a profiler server must be began.
Beginning profiler server
Within the following code snippet, we modified the principle technique (mmf_cli/run.py) to introduce the start_server (<port_number>) name. Discover that the server object returned by this technique will solely persist if captured in a variable. Subsequently server = xp.start_server(3294) will begin a profiler server that persists all through the coaching. Nevertheless if we solely referred to as begin server xp.start_server(3294) with none project, the server object doesn’t persist and also you will be unable to work together with the server (afterward we are going to request the server through TensorBoard to seize the profile for a given time frame.)
Make an observation of the port quantity used because the argument to start_server name (on this case 3294). We’ll use this when speaking with the profiler server within the later sections.
Insert traces annotations
As soon as the mmf library is put in within the developer mode, we are able to make adjustments to the supply code as proven beneath to observe this case research.
Within the following code snippet we illustrate StepTrace and Hint annotations. The previous introduces a named context (referred to as Training_Step) inside which we introduce a couple of extra nested named contexts to seize ahead, backward and replace instances by way of the latter annotations.
Notice that xp refers to import torch_xla.debug.profiler as xp as illustrated in earlier code snippet.
As soon as the coaching begins we are able to seize these annotations onto the hint by both the xp.hint technique or TensorBoard Profiler’s Seize Profile characteristic. On this case research we are going to use the TensorBoard characteristic for interactive and iterative profile seize. In improvement take a look at settings xp.hint can be utilized to seize the profile knowledge right into a TensorBoard logdir, nonetheless be cautioned that hint knowledge can shortly develop and subsequently hint name ought to solely be energetic for an affordable time interval.
Begin TensorBoard
Recall the TensorBoard setup directions shared within the earlier part (TensorBoard Setup). You began the TensorBoard server at port 9009. And whenever you ssh into the TPU VM occasion we forwarded port 9009 of our localhost to 9009 of the TPU VM. When you open localhost:9009 in your browser, you will note the next UI:
Notice: If you don’t see Profile choices within the drop-down menu, please verify the TensorBoard model and be sure that the profiler plugin was put in as instructed within the setup part.
Begin coaching
Begin the coaching utilizing the identical script that you simply used earlier with one modification. We modify the distributed world dimension to eight (for all-reduce visualization within the hint).
As soon as the coaching is underway you need to start to see the next log snippet:
Seize profile
Type TensorBoard UI which you began earlier, Click on ‘Seize Profile’ and specify the localhost:3294 (the identical port quantity you specified within the start_server name):
As soon as the seize is full you need to see an outline web page just like the next (if a couple of coaching step is captured within the hint, else the overview web page could also be clean, because it requires at the least one coaching step accomplished to supply any enter pipeline suggestions.
On this case-study, we are going to give attention to the hint view for particulars about different views. (For reminiscence profiler, pod viewer, and so forth. please check with the TensorBoard profiler documentation.) A few of these functionalities are usually not totally supported by TPU VM on the time of writing this text.
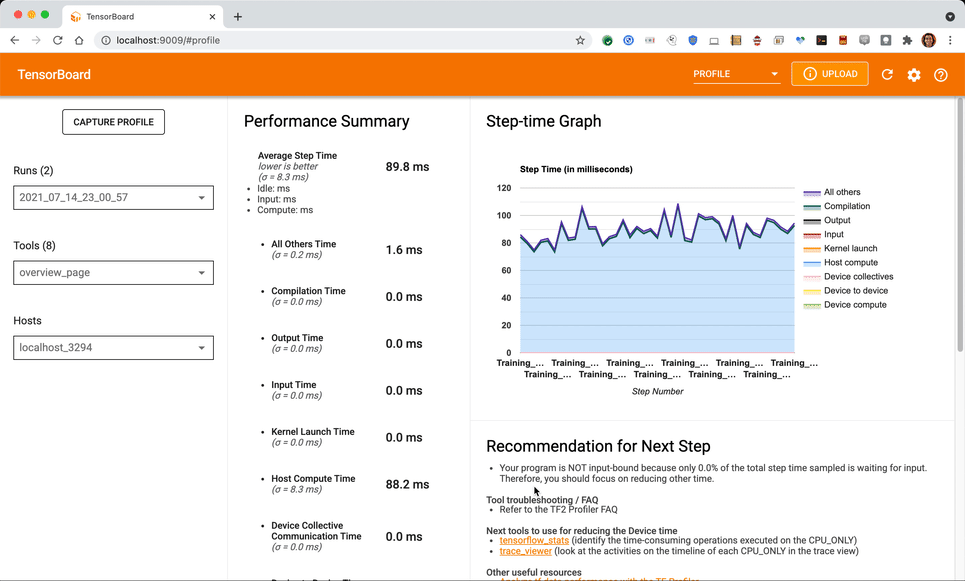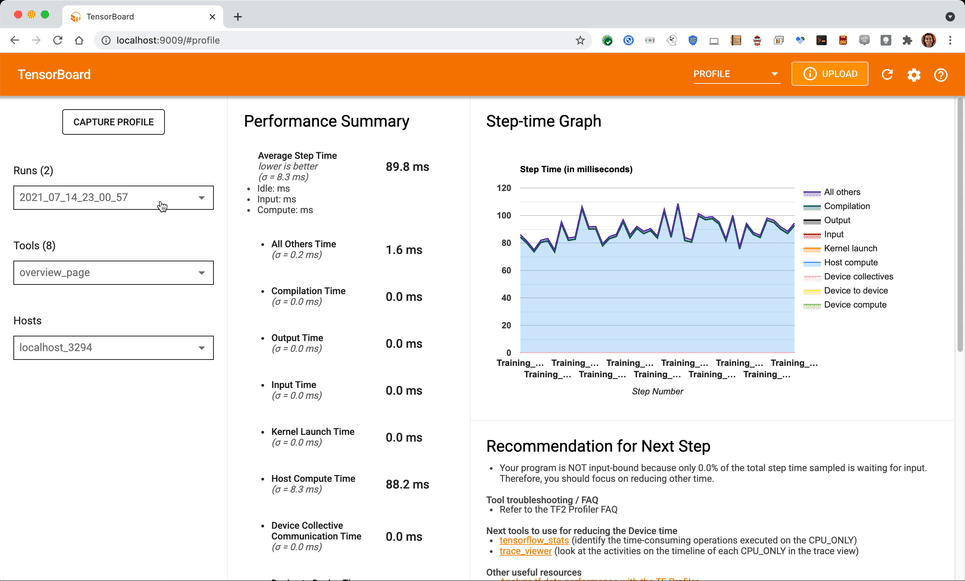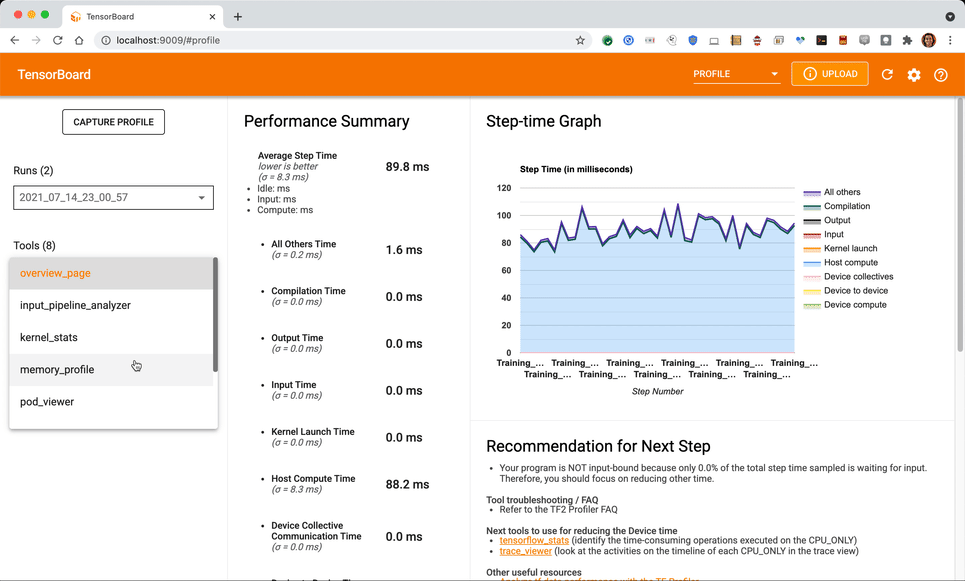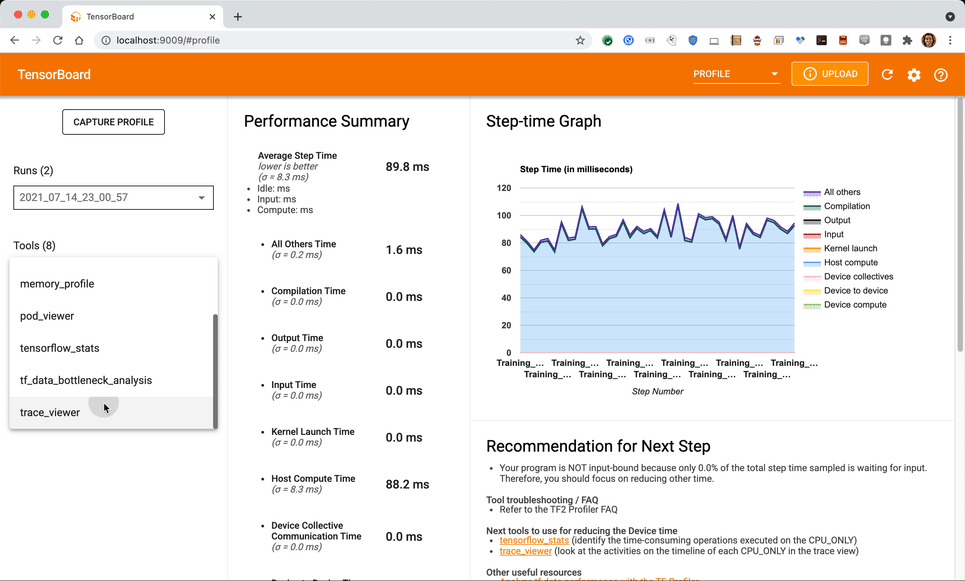
Navigate to the annotations within the Hint Viewer
Within the Hint Viewer, Traces collected from all of the gadget i.e. TPU processes and all of the host i.e. CPU processes are displayed. You should utilize the search bar and scroll down to seek out the annotations you could have launched within the supply code:
Understanding Hint
The next image exhibits the annotations that we created within the code snippet instance:
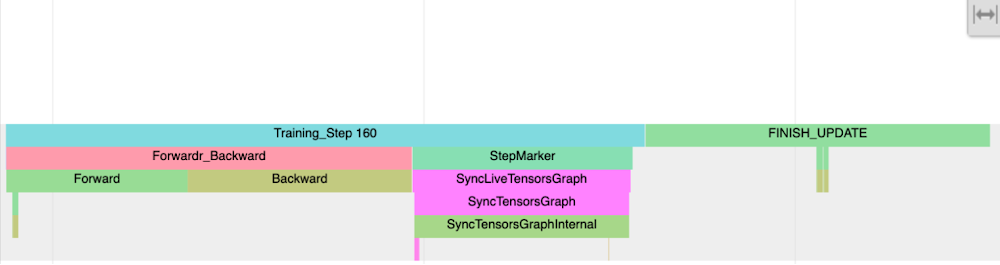
Discover the Coaching Step hint and sub-traces ahead and backward go. These annotations on the CPU course of hint Point out the time spent within the ahead backward go (IR graph) traversal. In case ahead or backward passes power early execution (unlowered op or worth fetch) you’ll discover ahead or backward traces damaged and interspersed a number of instances with StepMarker. StepMarker is an in-built annotation which corresponds to implicit or express mark_step() name.
Discover additionally the FINISH_UPDATE hint. Within the mmf code, this corresponds to cut back gradients and replace operations. We discover one other host course of which which is beginning TPUExecute operate name:
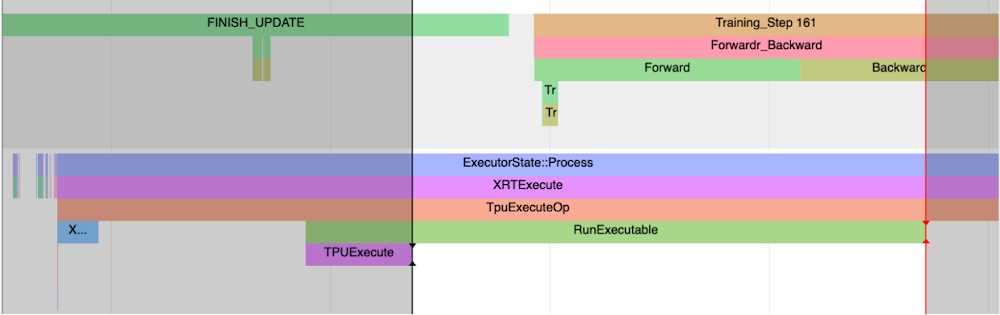
If we create a window from the TPUExecute to the tip of the RunExecutable hint we count on to see graph execution and all-reduce traces on the gadget (scroll again as much as the highest).
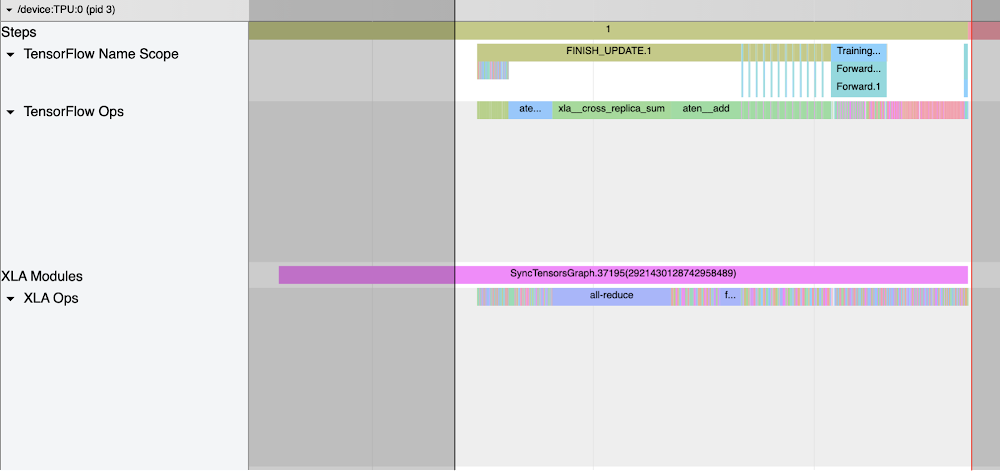
Discover the all_reduce xla_op and corresponding all scale back cross reproduction sum showing in tensorflow op. Tensorflow Identify Scope and Tensorflow Ops present up within the hint when XLA_HLO_DEBUG is enabled (ref code snippet in Begin Coaching part). It exhibits the annotation propagated to the HLO (Excessive Degree Operations) graph.
Discover additionally the gaps on the gadget hint. The responsibility cycle (i.e. the fraction of annotated hint per cycle) is the fraction of time spent on graph execution on the gadget. To research the gaps it’s typically a superb observe to pick out the hole length utilizing the hint viewer window software after which study the CPU traces to know what different operations are being executed in that interval. For instance, within the following hint we choose the 72.143ms interval the place no gadget hint is noticed:
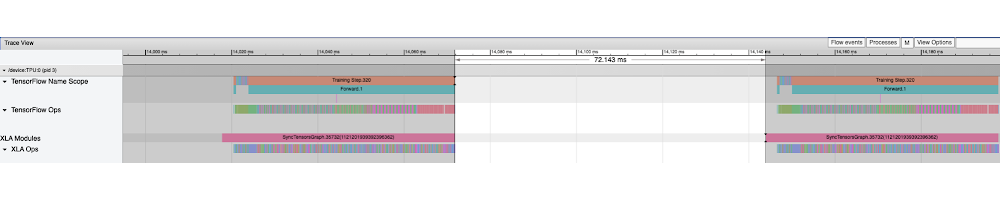
Analyzing the identical interval throughout cpu traces (zoomed in view), we discover three principal time chunks:
1. Overlapping with the IR era (backward go) of the following step, adopted by StepMarker (mark_step()) name. MarkStep alerts to PyTorch/XLA that the IR graph traversed to this point is to be executed now. If it’s a brand new graph, it is going to be compiled and optimized first (you’ll discover longer StepMarker hint and in addition separate course of traces annotated “xxyy” ):
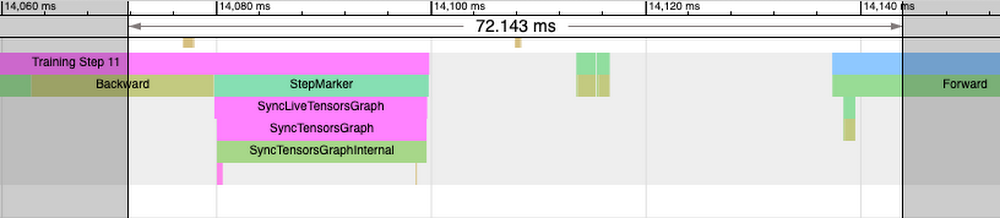
2. Graph/Knowledge is Transferred to the Server (i.e switch from host to TPU gadget):

Within the case of TPU VM transfer-to-server is anticipated to be a reasonable operation.
Three. XRTExecute is initiated which hundreds this system (graph) from cache if discovered or hundreds the enter graph and ultimately triggers TPU execution. (Particulars of XRTExecute, allocation, load program, signature and so forth is outdoors the scope of this case-study).
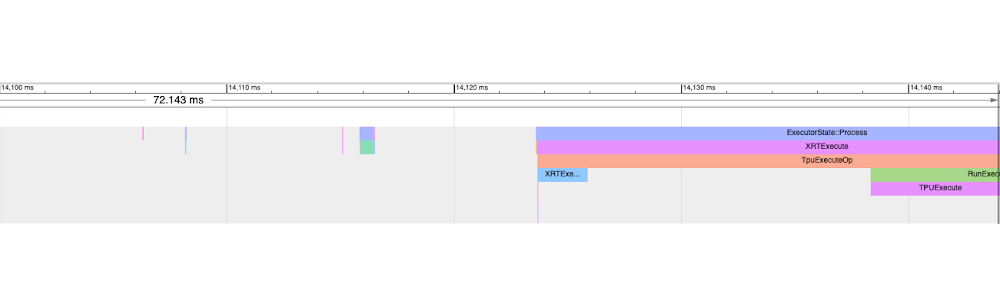
Discover additionally that the IR era for the next step has already begun whereas the present step is executed on TPU.
In abstract, the gaps in gadget hint are good areas to research. Aside from the three chunks or eventualities above, it may also be as a consequence of in-efficient knowledge pipeline. With the intention to examine it’s also possible to add annotations to data-loading components of the code after which examine it within the hint wrt to gadget execution. For a superb pipeline knowledge loading and transfer-to-server ought to overlap with gadget execution. If this isn’t the case, the gadget will likely be idle for a while ready for knowledge and this may be enter pipeline bottleneck.
Annotation propagation
Since PyTorch/XLA coaching includes IR graph translated into HLO graph which is then compiled and optimized additional by the runtime and people optimization don’t protect the preliminary graph construction, these annotations when propagated to HLO graphs and past (enabled by XLA_HLO_DEBUG=1) don’t seem in the identical order. For instance think about the next hint (zooming into the hint proven above):

This window doesn’t correspond to a number of ahead and backward traces within the host course of (you discover gaps within the hint when neither ahead or prepare step tags seem), nonetheless we discover Training_Step, Ahead and FINISH_UPDATE traces are interspersed right here. And it’s because the graph to which preliminary annotation is propagated has undergone a number of optimization passes.
Conclusion
Annotation propagation into the host and gadget traces utilizing the profiler API offers a strong mechanism to investigate the efficiency of your coaching. On this case research we didn’t deduce any optimizations to cut back coaching time from this evaluation however solely launched it for instructional functions. These optimizations can enhance effectivity, TPU utilization, responsibility cycle, coaching ingestion throughput and such.
Subsequent steps
As an train, we advocate the readers to repeat the evaluation carried out on this research with log_interval set to 1. This train will intensify device-to-host switch prices and the consequences of a number of the adjustments mentioned to optimize the coaching efficiency.
This concludes the part-Three of our three half collection on efficiency debugging. We reviewed the fundamental efficiency ideas and command line debug in part-1. In Half-1 we investigated a transformer based mostly mannequin coaching which was gradual as a consequence of too frequent gadget to host transfers. Half-1 ended with an train for the reader(s) to enhance the coaching efficiency. In Half-2 we began with the answer of the part-1 train and examined one other widespread sample of efficiency degradation, the dynamic graph. And eventually, on this publish we took a deeper dive into efficiency evaluation utilizing annotations and tensorboard hint viewer. We hope that the ideas introduced on this collection could be useful for the readers to debug their coaching runs successfully utilizing PyTorch/XLA profiler and derive actionable insights to enhance the coaching efficiency. The reader is inspired to experiment with their very own fashions and apply and study the ideas introduced right here.
Acknowledgements
The creator want to thank Jordan Totten, Rajesh Thallam, Karl Weinmeister and Jack Cao (Google) on your endurance and generosity. Every considered one of you supplied quite a few suggestions with out which this publish could be riddled with annoying errors. Particular because of Jordan for patiently testing the case research introduced on this collection, for locating many bugs, and offering precious ideas. Due to Joe Spisak, Geeta Chauhan (Meta) and Shauheen Zahirazami and Zak Stone (Google) on your encouragement, particularly for the suggestions to separate what would have been too lengthy a publish for anybody to learn. Due to Ronghong Hu (Meta AI) for the suggestions and questions on the early revisions which made, particularly, the hint dialogue far more accessible and useful. And eventually to Amanpreet Singh (Meta AI), the creator of MMF framework, on your inputs in varied debugging discussions, case research choice and on your inputs in constructing the TPU assist in MMF, with out your assist this collection wouldn’t be doable.
[ad_2]
Source link




