
[ad_1]
With everybody and their canine shifting to containers, and away from digital machines (VMs), we realized that operating vendor-provided software program on VMs at Google was slowing us down.
So we moved.
Enter Anthos, Google Cloud’s managed software platform, and its related developer instruments. At present we’ll take you thru our strategy of transferring Confluence and Acrolinx from VMs operating in our personal information heart surroundings over to a completely managed, containerized deployment for Google. Each Confluence and Acrolinx had been deployed earlier than on the Google Compute Engine platform and have been used inside Google for content material administration.
Up to now, Google used inside methods for allocating software assets, automating replication and offering excessive availability for enterprise functions, however these methods relied on custom-made infrastructure and so they had been usually incompatible with enterprise software program.
The numerous frustrations that got here with operating enterprise functions on VMs included:
-
Service turnup occasions within the order of days
-
Exhausting-to-manage infrastructure and workloads programmatically
-
Challenges with VM monoliths administration (as in comparison with microservices)
-
Dependable rollback of software set up/improve failures
-
Challenges with imposing safety insurance policies at scale
… and plenty of others
To mitigate these frustrations, we made the shift to an industry-standard, universally out there managed platform: Kubernetes.
Kubernetes and Anthos
Deploying Kubernetes gave us the power to configure, handle, and prolong workloads operating on containers reasonably than VMs. The excellent news was that it may deal with the dimensions of our deployments with ease.
Anthos is Google Cloud’s platform of instruments and applied sciences designed to ease the administration of containerized workloads, whether or not operating on Google Cloud, different clouds, or on-premises. It brings configuration administration, service administration, telemetry, logging and cluster administration tooling. As well as, it saves operational overhead for our software groups.
As our vendor-provided software program turned suitable with containerization, we may construct on 15 years of expertise operating containerized workloads and benefit from the perks of utilizing a completely managed cloud service for our functions.
Adopting Anthos gave us some massive advantages immediately:
-
Automated useful resource provisioning
-
Utility lifecycle administration
-
Safety Insurance policies Administration
-
Config-as-code for workload state
This eliminated substantial guide toil from our group, liberating them up for extra productive work. Utilizing Anthos Config Connector we may specific the compute, networking and storage wants by code, permitting Anthos to allocate them with out guide interplay. We additionally relied on Anthos to manage creating Kubernetes clusters and handle a single admin cluster that might host the Config Connector. This gave us less complicated orchestration once we wanted to create new Kubernetes clusters to run our functions.
How we modernized operations
Our steady integration and steady deployment course of benefitted from Anthos as nicely. By utilizing Anthos Config Administration (Config Sync), a multi-repository configuration sync utility, we will automate the method of making use of our desired configuration to the Kubernetes clusters that we’d in any other case have utilized manually earlier than through kubectl. The multi-repo Config Sync supplies a constant expertise when managing each the frequent safety insurance policies throughout clusters and the workload particular configs which are namespace-scoped.
Config Sync is a Kubernetes Customized Useful resource Definition (CRD) useful resource which is put in on a consumer cluster by GKE Hub.
GKE Hub supplies networking help inside Anthos, and allows you to logically group collectively related GKE clusters. As soon as the clusters are registered with a GKE Hub, the identical safety insurance policies might be administered on all of the registered clusters. Onboarding a brand new software then wouldn’t incur any further overhead, as a result of the identical safety insurance policies can be utilized routinely.
The ensuing clusters and administration of those functions seems like this:
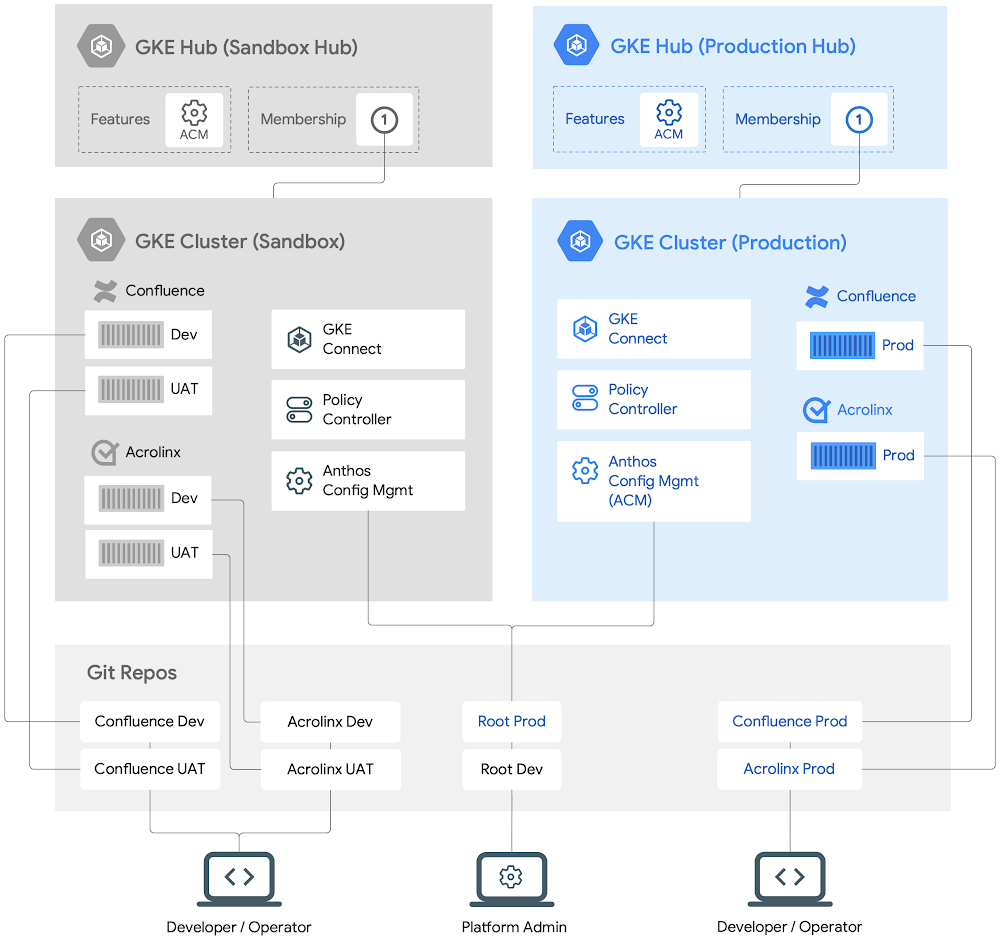
A excessive stage view of Anthos-managed workloads operating on GKE clusters
Our up to date deployment course of
We have deployed quite a lot of third-party functions on Anthos. At present, we’ll stroll you thru how we arrange Confluence and Acrolinx.
To provision and deploy, we have to:
-
Make sure that all of the configs (each safety insurance policies and workload configs) are saved in a single supply of reality (i.e Git repos). Any adjustments should be reviewed and accepted by a number of events to forestall unilateral adjustments.
-
Deploy and implement our required safety insurance policies.
-
Specific the specified state of workload configs in a Git repo.
-
Deploy a Steady Integration and Steady Deployment pipeline to make sure that adjustments to the configs are examined earlier than committing them to a Git repo. Such configs will then be utilized to the goal clusters to make sure the specified state of each the functions.
Though we’re operating a number of segmented workloads, we will apply frequent safety insurance policies to all of them. We additionally delegate software deployment to the builders whereas sustaining safety guardrails to forestall errors.
How we arrange Anthos clusters
We all know what we need to deploy, and how you can defend them. Let’s dig into how we will arrange these clusters with Terraform after which how to verify all our safety insurance policies are utilized. As soon as that’s full we will let the developer or operator handle any future adjustments to the applying, whereas the cluster admin retains management of any cluster coverage adjustments.
We’ll register the cluster with the correct GKE Hub, then apply our desired configuration to that cluster, and eventually deploy the functions to their namespaces.
Let’s begin with the prod GKE cluster. We will create it utilizing these Terraform templates,then cluster with GKE Hub utilizing:
Subsequent, we’ll allow the ACM/Config Sync characteristic for the GKE Hub, hub-prod, utilizing the gcloud command-line:
Right here, a ConfigManagement useful resource configures Config Sync on the prod GKE cluster with the related root Git repo (root-prod).
After creating the GKE clusters, we’ll arrange cluster namespaces to deploy Confluence and Acrolinx:
Here is a technique the basis and namespace repos might be organized in a root-prod structured repo.
All of the cluster-scoped assets might be saved within the cluster listing whereas all of the namespace scoped assets for the given functions might be saved in every of the namespaces sub-directories. This separation permits us to outline the frequent cluster scoped safety insurance policies at the next stage whereas nonetheless defining software configs at every software namespace stage. The cluster admins can personal the safety insurance policies whereas delegating namespace possession to the builders.
We now have a GKE cluster prod that’s registered with a GKE Hub. Because the cluster is registered with the GKE Hub with Config Sync enabled, the safety insurance policies now might be utilized on this cluster.
Deploying adjustments to functions
To ensure that Config Sync to use config adjustments to assets of Confluence and Acrolinx functions, every of the Namespace assets and Namespace repos should first be configured.
Taking a look at an instance of a root-prod Git repo as proven above and the respective Namespaces repos, RepoSync assets and the way Confluence and Acrolinx software assets might be managed by Config Sync within the prod GKE cluster.
The next is an instance of a Namespace and RepoSync useful resource within the confluence-prod listing.
Config Sync will learn the Namespace config file and create confluence-prod Namespace in the identical prod GKE cluster.
The RepoSync useful resource units up a course of to connect with the Git repo to search out configuration data that might be utilized by the Confluence software.
We at the moment are able to create Kubernetes assets for Confluence from its namespace Git repo.
Subsequent, we will deploy a StatefulSet useful resource that defines the container’s spec (CPU, RAM, and so forth.) for operating Confluence app within the confluence-prod namespace repo:
After submission to the repo, Config Sync will learn the StatefulSet and deploy the picture primarily based on the assets listed.
Our safety follow
Each group has a requirement to make sure that the workloads are made safe with none further efforts from the builders and that there’s a central governing course of that enforces such safety insurance policies throughout all of the workloads. Thisensures that everybody follows finest practices when deploying workloads. It additionally reduces a lot of the burden and cognitive load from the builders when making certain that workloads comply with such safety rules and insurance policies.
Traditionally, when operating functions on VMs, it has been historically troublesome to micro-segment functions, apply a special set of insurance policies to the micro-segmented functions and/or primarily based on workload identities. Some examples of such insurance policies are: whether or not an software is constructed and deployed in a verifiable method; stopping privilege escalation (e.g setuid binaries) and making use of that config for a bunch of workloads and so forth.
With the appearance of Kubernetes and requirements resembling OPA (Open Coverage Agent), it’s doable now to micro-segment workloads, outline a set of insurance policies that may implement sure constraints and guidelines on the workload id stage for a bunch of comparable workload assets. That is one such library of OPA Constraints that can be utilized to implement coverage throughout Cluster workloads.
Coverage Controller allows the enforcement of totally programmable insurance policies. You need to use these insurance policies to actively block non-compliant API requests, or just to audit the configuration of your clusters and report violations. Coverage Controller relies on the open supply Open Coverage Agent Gatekeeper venture and comes with a full library of pre-built insurance policies for frequent safety and compliance controls.
This may permit the builders to deal with simply the applying lifecycle administration whereas the platform admins will be sure that such safety insurance policies are enforced on all of the registered clusters and workloads.
Conclusion
In the long run we received to a a lot better place by deploying our functions with Anthos, backed by Kubernetes.
Our safety insurance policies had been enforced routinely, we scale up and down with demand, and new variations could possibly be deployed easily. Our builders loved quicker workflows, whether or not spinning up a brand new surroundings or testing out an replace for stability. Provisioning received simpler too, with much less overhead for the group, particularly as deployments grew to service the entire of Google.
Total we’re fairly pleased with how we improved developer productiveness with quicker software turnup occasions, going from days to simply hours for a brand new software. On the similar time we’re higher in a position to reliably implement insurance policies that be sure that functions are hosted in a safe and dependable surroundings.
We’re glad we will share a few of our journey with you; if you wish to attempt it out your self, get began with Anthos at present.
[ad_2]
Source link




