
[ad_1]
Introduction
This submit exhibits how you need to use Vertex Pipelines to construct an end-to-end ML workflow. The workflow trains a customized mannequin utilizing AutoML; evaluates the accuracy of the educated mannequin; and if the mannequin is sufficiently correct, deploys it to Vertex AI for serving.
Vertex AI and Vertex Pipelines
The recently-launched Vertex AI is a unified ML Ops platform to assist information scientists and ML engineers improve their charge of experimentation, deploy fashions quicker, and handle fashions extra successfully. It brings AutoML and AI Platform collectively, with some new ML Ops-focused merchandise, right into a unified API, consumer library, and person interface.
Vertex Pipelines is a part of Vertex AI. It lets you automate, monitor, and govern your ML techniques by orchestrating your ML workflows. It’s automated, scalable, serverless, and cost-effective: you pay just for what you utilize. Vertex Pipelines is the spine of the Vertex AI ML Ops story, and makes it simple to construct and run ML workflows utilizing any ML framework. As a result of it’s serverless, and has seamless integration with GCP and Vertex AI instruments and providers, you may concentrate on constructing and operating your pipelines with out worrying about infrastructure or cluster upkeep.
Vertex Pipelines mechanically logs metadata to trace artifacts, lineage, metrics, and execution throughout your ML workflows, helps step execution caching, and offers assist for enterprise safety controls like Cloud IAM, VPC-SC, and CMEK.
Vertex Pipelines helps two open supply Python SDKs: TFX (TensorFlow Prolonged) and KFP (Kubeflow Pipelines). The instance Vertex pipeline highlighted on this submit makes use of the KFP SDK, and consists of use of the Google Cloud Pipeline Parts, which assist easy accessibility to Vertex AI providers. Vertex Pipelines requires v2 of the KFP SDK. Quickly, it will likely be potential to make use of the KFP v2 ‘compatibility mode’ to run KFP V2 examples like this on OSS KFP as nicely.
An end-to-end AutoML workflow with Vertex Pipelines
Vertex AI’s AutoML Tabular service helps you to convey your individual structured information to coach a mannequin, with no need to construct the mannequin structure your self. For this instance, I’ll use the UCI Machine Studying ‘Dry beans’ dataset. (From: KOKLU, M. and OZKAN, I.A., (2020) “Multiclass Classification of Dry Beans Utilizing Laptop Imaginative and prescient and Machine Studying Methods.”In Computer systems and Electronics in Agriculture, 174, 105507. DOI.)
The problem is a classification job: predict the kind of a bean given some details about its traits.
Vertex Pipelines makes it very easy to assemble a workflow to assist constructing, evaluating, and deploying such fashions. We’ll construct a pipeline that appears like this:
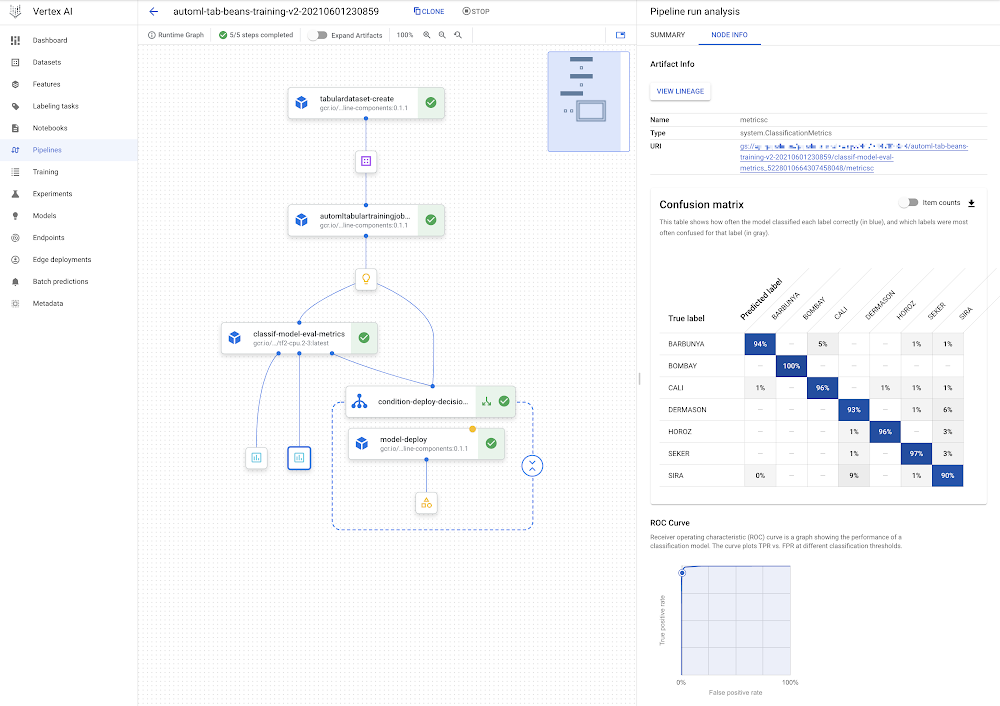
The DAG for the AutoML classification workflow.
You may see that the mannequin deployment step is wrapped by a conditional: the mannequin will solely be deployed if the analysis step signifies that it’s sufficiently correct.
For this instance, almost all of the elements (steps) within the pipeline are prebuilt Google Cloud Pipeline Parts. Because of this we principally simply must specify how the pipeline is put collectively utilizing these constructing blocks.
Nevertheless, I’ll add one Python function-based customized part for mannequin analysis and metrics visualization.
The pipeline definition appears as follows (with a little bit of element elided):
We first create a Dataset from a BigQuery desk that holds the coaching information. Then, we use AutoML to coach a tabular classification mannequin. The dataset arg to the coaching step will get its worth from the output of the Dataset step (dataset=dataset_create_op.outputs["dataset"]).
After the mannequin is educated, its analysis metrics are checked in opposition to given ‘threshold’ info, to determine whether or not it’s correct sufficient to deploy.
The following part goes into extra element about how this practice ‘eval metrics’ part is outlined. One in every of its inputs is an output of the coaching step (training_op.outputs["model"])— which factors to the educated mannequin.
Then, a KFP conditional makes use of an output of the eval step to determine whether or not to proceed with the deployment:
If the mannequin is sufficiently correct, the prebuilt deployment part is named. This step creates an Endpoint and deploys the educated mannequin to that endpoint for serving.
Defining a customized part
A lot of the steps within the pipeline above are drawn from pre-built elements; constructing blocks that make it simple to assemble an ML workflow. However I’ve outlined one customized part to parse the educated mannequin’s analysis metrics, render some metrics visualizations, and decide— based mostly on given ‘threshold’ info— whether or not the mannequin is nice sufficient to be deployed. This tradition part is outlined as a Python operate with a @kfp.v2.dsl.part decorator. When this operate is evaluated, it’s compiled to a job ‘manufacturing unit operate’ that can be utilized in a pipeline specification. The KFP SDK makes it very easy to outline new pipeline elements on this approach.
Under is the customized part definition, with some element elided. The @part decorator specifies three optionally available arguments: the bottom container picture to make use of; any packages to put in; and the yaml file to which to jot down the part specification.
The part operate, classif_model_eval_metrics, has some enter parameters of observe. The mannequin parameter is an enter kfp.v2.dsl.Mannequinartifact. As it’s possible you’ll keep in mind from the pipeline specification above, right here this enter can be supplied by an output of the coaching step.
The final two operate args, metrics and metricsc , are part Outputs, on this case of sorts Metrics and ClassificationMetrics. They’re not explicitly handed as inputs to the part step, however slightly are mechanically instantiated and can be utilized within the part. For instance, within the operate under, we’re calling metricsc.log_roc_curve() and metricsc.log_confusion_matrix() to render these visualizations within the Pipelines UI. These Output params grow to be part outputs when the part is compiled, and might be consumed by different pipeline steps.
The NamedTuple outputs are one other kind of part output. Right here we’re returning a string that signifies whether or not or to not deploy the mannequin.
When this operate is evaluated, we will use the generated manufacturing unit operate to outline a pipeline step as a part of a pipeline definition, as we noticed within the earlier part:
The instance pocket book has the complete part definition.
Sharing part specs
When the part is compiled, we will additionally request that a yaml part specification be generated. We did this through the optionally available output_component_file="tables_eval_component.yaml" arg handed to the @part decorator.
The yaml format permits the part specification to be put underneath model management and shared with others.
Then, the part can be utilized in different pipelines by calling the kfp.elements.load_component_from_url operate (and different variants like load_component_from_file).
Working a pipeline job on Vertex Pipelines
As soon as a pipeline is outlined, the following step is to compile it — which generates a json job spec file— then submit and run it on Vertex Pipelines. While you submit a pipeline job, you may specify values for pipeline enter parameters, overriding their defaults.
The instance pocket book exhibits the small print of how to do that.
As soon as a pipeline is operating, you may view its particulars within the Cloud Console, together with the pipeline run and lineage graphs proven above, in addition to pipeline step logs and pipeline Artifact particulars.
You can even submit pipeline job specs through the Cloud Console UI, and the UI makes it simple to clone pipeline runs. The json pipeline specification file might also be put underneath model management and shared with others.
Leveraging Pipeline step caching to develop and debug
Vertex Pipelines helps step caching, and this helps with iterating on pipeline improvement— whenever you rerun a pipeline, if a part’s inputs haven’t modified, its cached execution outcomes might be reused. Should you run this pipeline greater than as soon as, you may discover this characteristic in motion.
Should you’re operating the instance, strive making a small change to the instance pocket book cell that holds the customized part definition (the classif_model_eval_metrics operate within the “Outline a metrics eval customized part” part) by uncommenting this line:
# metrics.metadata["model_type"] = "AutoML Tabular classification"
Then re-compile the part, recompile the pipeline with out altering the DISPLAY_NAME worth, and run it once more. While you achieve this, you need to see that Vertex Pipelines can leverage the cached executions for the upstream steps— as their inputs didn’t change— and solely must re-execute from the modified part. The pipeline DAG for the brand new run ought to look as follows, with the ‘recycle’ icon on a few of the steps indicating that their cached executions have been used.
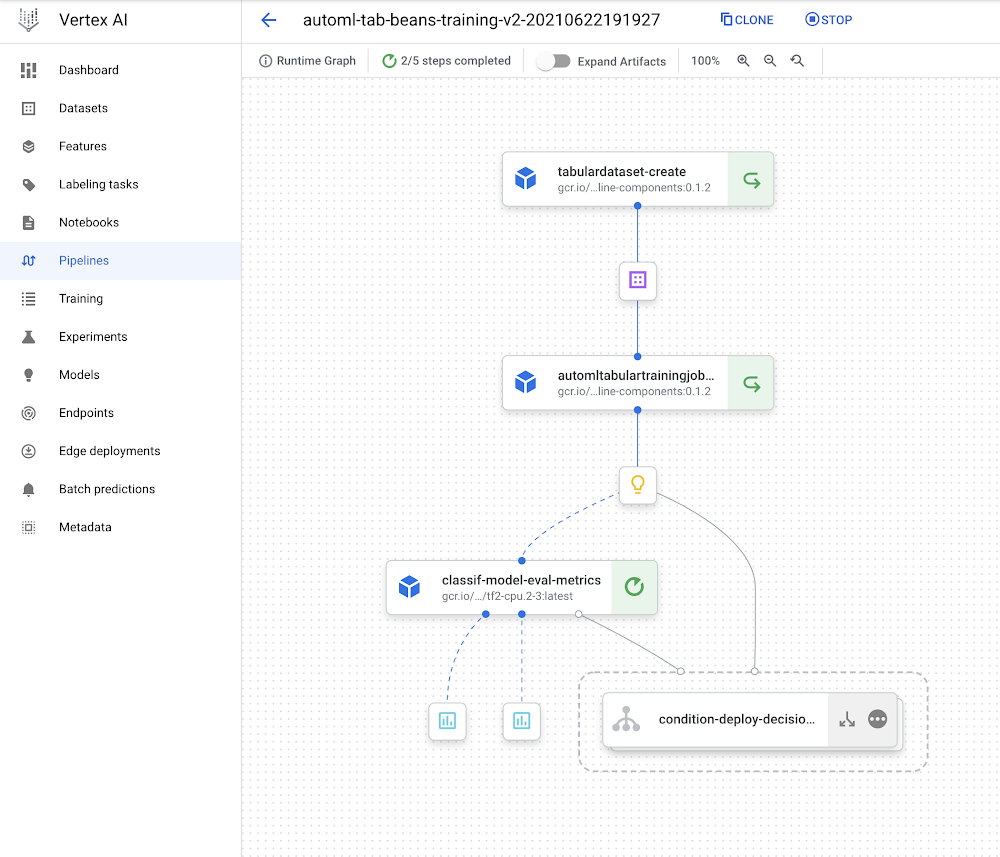
Leveraging step caching with the AutoML classification workflow.
Observe: Step caching is on by default, however if you wish to disable it, you may go the enable_caching=False arg to the create_run_from_job_spec operate whenever you submit a pipeline run.
Lineage monitoring
Should you click on on an Artifact in a pipeline graph, you’ll see a “VIEW LINEAGE” button. This tracks how the artifacts are linked by step executions. So it’s form of the inverse of the pipeline DAG, and might embody a number of executions that consumed the identical artifact (this typically occurs with cache hits, for instance). The monitoring info proven is just not essentially only for a single pipeline run, however for any pipeline execution that has used the given artifact.
What’s subsequent?
This submit launched Vertex Pipelines, and the prebuilt Google Cloud Pipeline Parts, which permit easy accessibility to Vertex AI providers. The Pipelines instance on this submit makes use of the AutoML Tabular service, displaying how easy it’s to convey your individual information to coach a mannequin. It confirmed a pipeline that creates a Dataset, trains a mannequin utilizing that dataset, obtains the mannequin’s analysis metrics, and decides whether or not or to not deploy the mannequin to Vertex AI for serving.
For subsequent steps, take a look at different Vertex Pipelines instance notebooks in addition to a codelab based mostly partially on the pipeline on this submit.
You can even discover different Vertex AI pocket book examples right here and right here.
[ad_2]
Source link




