
[ad_1]

|
Immediately, I’m extraordinarily completely satisfied to announce Amazon SageMaker Pipelines, a brand new functionality of Amazon SageMaker that makes it straightforward for knowledge scientists and engineers to construct, automate, and scale finish to finish machine studying pipelines.
Machine studying (ML) is intrinsically experimental and unpredictable in nature. You spend days or even weeks exploring and processing knowledge in many alternative methods, attempting to crack the geode open to disclose its valuable gem stones. Then, you experiment with totally different algorithms and parameters, coaching and optimizing a lot of fashions looking for highest accuracy. This course of usually entails a lot of totally different steps with dependencies between them, and managing it manually can develop into fairly complicated. Specifically, monitoring mannequin lineage may be tough, hampering auditability and governance. Lastly, you deploy your high fashions, and also you consider them towards your reference check units. Lastly? Not fairly, as you’ll definitely iterate time and again, both to check out new concepts, or just to periodically retrain your fashions on new knowledge.
Regardless of how thrilling ML is, it does sadly contain loads of repetitive work. Even small tasks would require a whole bunch of steps earlier than they get the inexperienced mild for manufacturing. Over time, not solely does this work detract from the enjoyable and pleasure of your tasks, it additionally creates ample room for oversight and human error.
To alleviate guide work and enhance traceability, many ML groups have adopted the DevOps philosophy and carried out instruments and processes for Steady Integration and Steady Supply (CI/CD). Though that is definitely a step in the fitting course, writing your personal instruments typically results in complicated tasks that require extra software program engineering and infrastructure work than you initially anticipated. Worthwhile time and sources are diverted from the precise ML challenge, and innovation slows down. Sadly, some groups determine to revert to guide work, for mannequin administration, approval, and deployment.
Introducing Amazon SageMaker Pipelines
Merely put, Amazon SageMaker Pipelines brings in best-in-class DevOps practices to your ML tasks. This new functionality makes it straightforward for knowledge scientists and ML builders to create automated and dependable end-to-end ML pipelines. As typical with SageMaker, all infrastructure is absolutely managed, and doesn’t require any work in your facet.
Care.com is the world’s main platform for locating and managing high-quality household care. Right here’s what Clemens Tummeltshammer, Information Science Supervisor, Care.com, informed us: “A powerful care trade the place provide matches demand is important for financial progress from the person household as much as the nation’s GDP. We’re enthusiastic about Amazon SageMaker Function Retailer and Amazon SageMaker Pipelines, as we imagine they may assist us scale higher throughout our knowledge science and improvement groups, through the use of a constant set of curated knowledge that we will use to construct scalable end-to-end machine studying (ML) mannequin pipelines from knowledge preparation to deployment. With the newly introduced capabilities of Amazon SageMaker, we will speed up improvement and deployment of our ML fashions for various purposes, serving to our clients make higher knowledgeable selections by way of sooner real-time suggestions.”
Let me inform you extra about the primary parts in Amazon SageMaker Pipelines: pipelines, mannequin registry, and MLOps templates.
Pipelines – Mannequin constructing pipelines are outlined with a easy Python SDK. They will embody any operation out there in Amazon SageMaker, equivalent to knowledge preparation with Amazon SageMaker Processing or Amazon SageMaker Information Wrangler, mannequin coaching, mannequin deployment to a real-time endpoint, or batch remodel. You may as well add Amazon SageMaker Make clear to your pipelines, with the intention to detect bias previous to coaching, or as soon as the mannequin has been deployed. Likewise, you’ll be able to add Amazon SageMaker Mannequin Monitor to detect knowledge and prediction high quality points.
As soon as launched, mannequin constructing pipelines are executed as CI/CD pipelines. Each step is recorded, and detailed logging info is on the market for traceability and debugging functions. In fact, you too can visualize pipelines in Amazon SageMaker Studio, and observe their totally different executions in actual time.
Mannequin Registry – The mannequin registry helps you to observe and catalog your fashions. In SageMaker Studio, you’ll be able to simply view mannequin historical past, listing and evaluate variations, and observe metadata equivalent to mannequin analysis metrics. You may as well outline which variations might or will not be deployed in manufacturing. In actual fact, you’ll be able to even construct pipelines that robotically set off mannequin deployment as soon as approval has been given. You’ll discover that the mannequin registry may be very helpful in tracing mannequin lineage, bettering mannequin governance, and strengthening your compliance posture.
MLOps Templates – SageMaker Pipelines features a assortment of built-in CI/CD templates revealed by way of AWS Service Catalog for widespread pipelines (construct/practice/deploy, deploy solely, and so forth). You may as well add and publish your personal templates, in order that your groups can simply uncover them and deploy them. Not solely do templates save a lot of time, in addition they make it straightforward for ML groups to collaborate from experimentation to deployment, utilizing normal processes and with out having to handle any infrastructure. Templates additionally let Ops groups customise steps as wanted, and provides them full visibility for troubleshooting.
Now, let’s do a fast demo!
Constructing an Finish-to-end Pipeline with Amazon SageMaker Pipelines
Opening SageMaker Studio, I choose the “Parts” tab and the “Initiatives” view. This shows an inventory of built-in challenge templates. I decide one to construct, practice, and deploy a mannequin.

Then, I merely give my challenge a reputation, and create it.
A number of seconds later, the challenge is prepared. I can see that it contains two Git repositories hosted in AWS CodeCommit, one for mannequin coaching, and one for mannequin deployment.

The primary repository offers scaffolding code to create a multi-step mannequin constructing pipeline: knowledge processing, mannequin coaching, mannequin analysis, and conditional mannequin registration based mostly on accuracy. As you’ll see within the pipeline.py file, this pipeline trains a linear regression mannequin utilizing the XGBoost algorithm on the well-known Abalone dataset. This repository additionally features a construct specification file, utilized by AWS CodePipeline and AWS CodeBuild to execute the pipeline robotically.
Likewise, the second repository accommodates code and configuration information for mannequin deployment, in addition to check scripts required to go the standard gate. This operation can be based mostly on AWS CodePipeline and AWS CodeBuild, which run a AWS CloudFormation template to create mannequin endpoints for staging and manufacturing.
Clicking on the 2 blue hyperlinks, I clone the repositories regionally. This triggers the primary execution of the pipeline.

A couple of minutes later, the pipeline has run efficiently. Switching to the “Pipelines” view, I can visualize its steps.

Clicking on the coaching step, I can see the Root Imply Sq. Error (RMSE) metrics for my mannequin.
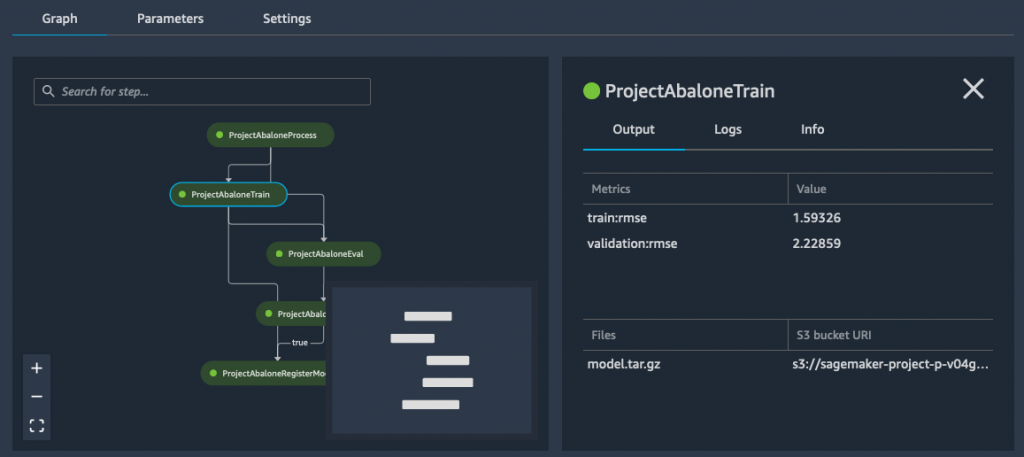
Because the RMSE is decrease than the edge outlined within the conditional step, my mannequin is added to the mannequin registry, as seen beneath.
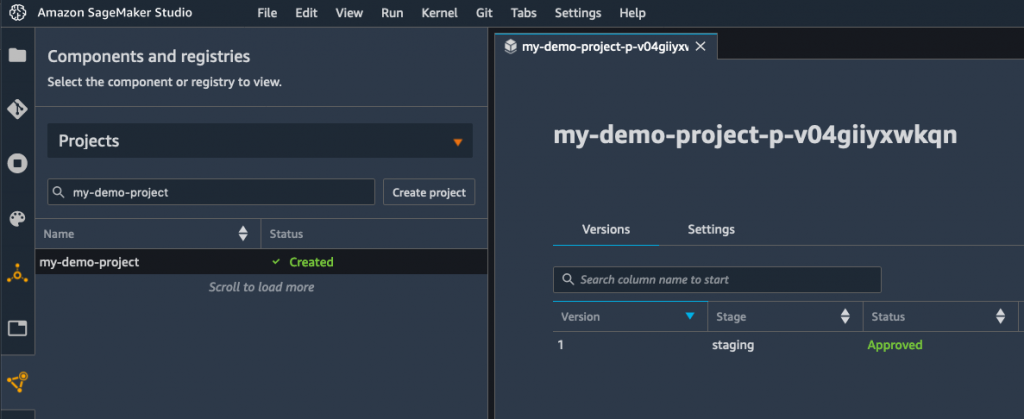
For simplicity, the registration step units the mannequin standing to “Authorized”, which robotically triggers its deployment to a real-time endpoint in the identical account. Inside seconds, I see that the mannequin is being deployed.
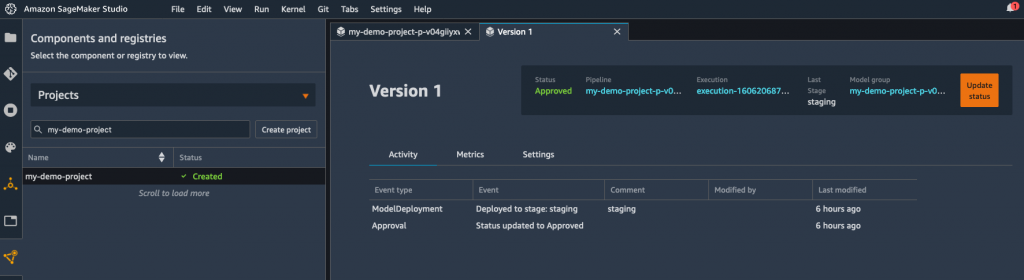
Alternatively, you could possibly register your mannequin with a “Pending guide approval” standing. It will block deployment till the mannequin has been reviewed and authorised manually. Because the mannequin registry helps cross-account deployment, you could possibly additionally simply deploy in a distinct account, with out having to repeat something throughout accounts.
A couple of minutes later, the endpoint is up, and I might use it to check my mannequin.
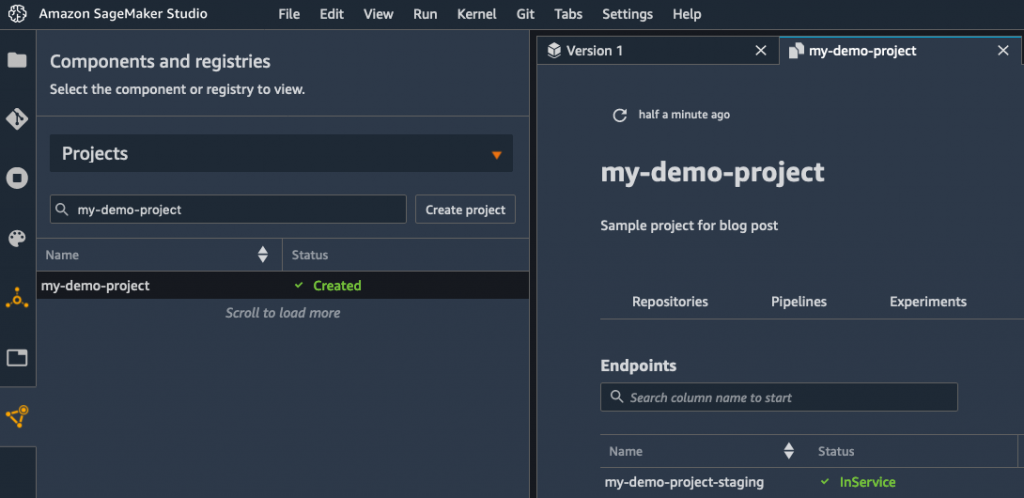
As soon as I’ve made positive that this mannequin works as anticipated, I might ping the MLOps group, and ask them to deploy the mannequin in manufacturing.
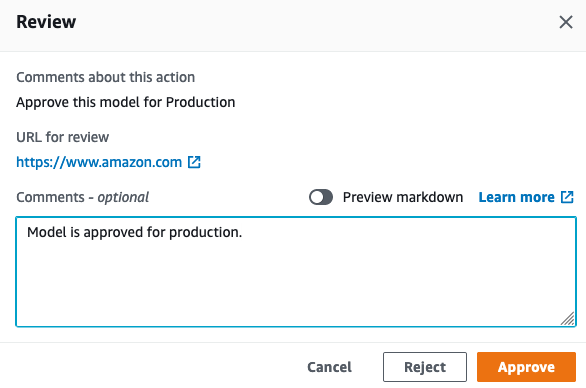
Placing my MLOps hat on, I open the AWS CodePipeline console, and I see that my deployment is certainly ready for approval.

I then approve the mannequin for deployment, which triggers the ultimate stage of the pipeline.
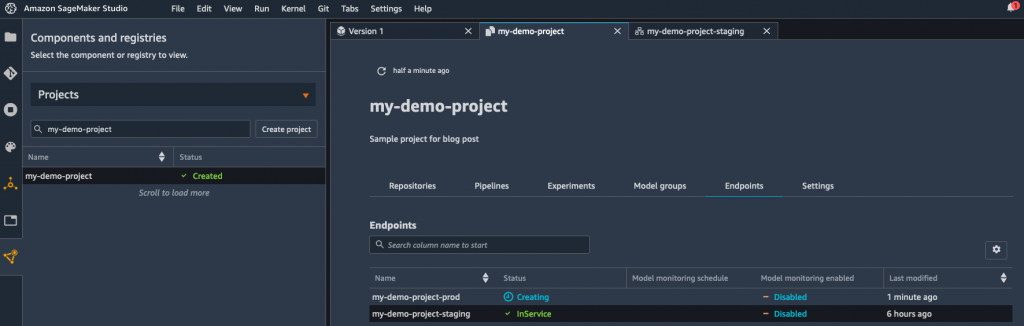
Reverting to my Information Scientist hat, I see in SageMaker Studio that my mannequin is being deployed. Job performed!
Getting Began
As you’ll be able to see, Amazon SageMaker Pipelines makes it very easy for Information Science and MLOps groups to collaborate utilizing acquainted instruments. They will create and execute sturdy, automated ML pipelines that ship prime quality fashions in manufacturing faster than earlier than.
You can begin utilizing SageMaker Pipelines in all business areas the place SageMaker is on the market. The MLOps capabilities can be found within the areas the place CodePipeline can be out there.
Pattern notebooks can be found to get you began. Give them a strive, and tell us what you assume. We’re at all times wanting ahead to your suggestions, both by way of your typical AWS help contacts, or on the AWS Discussion board for SageMaker.
– Julien
Particular due to my colleague Urvashi Chowdhary for her valuable help throughout early testing.
[ad_2]
Source link





