[ad_1]

|
Amazon Managed Streaming for Apache Kafka (Amazon MSK) offers a completely managed and extremely accessible Apache Kafka service simplifying the way in which you course of streaming information. When utilizing Apache Kafka, a standard architectural sample is to duplicate information from one cluster to a different.
Cross-cluster replication is commonly used to implement enterprise continuity and catastrophe restoration plans and enhance utility resilience throughout AWS Areas. One other use case, when constructing multi-Area purposes, is to have copies of streaming information in a number of geographies saved nearer to finish shoppers for decrease latency entry. You may also have to mixture information from a number of clusters into one centralized cluster for analytics.
To handle these wants, you would need to write customized code or set up and handle open-source instruments like MirrorMaker 2.zero, accessible as a part of Apache Kafka beginning with model 2.four. Nonetheless, these instruments could be advanced and time-consuming to arrange for dependable replication, and require steady monitoring and scaling.
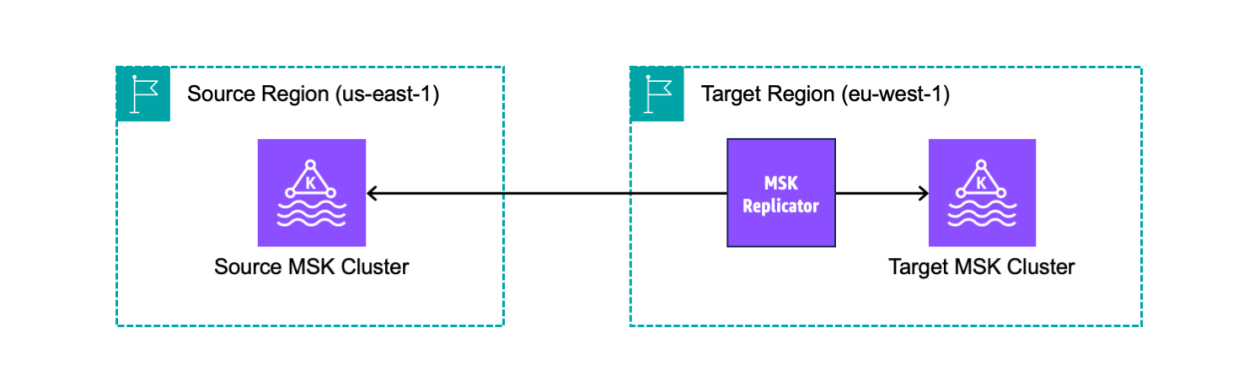
As we speak, we’re introducing MSK Replicator, a brand new functionality of Amazon MSK that makes it simpler to reliably arrange cross-Area and same-Area replication between MSK clusters, scaling robotically to deal with your workload. You need to use MSK Replicator with each provisioned and serverless MSK cluster sorts, together with these utilizing tiered storage.
With MSK Replicator, you may setup each active-passive and active-active cluster topologies to extend the resiliency of your Kafka utility throughout Areas:
- In an active-active setup, each MSK clusters are actively serving reads and writes.
- In an active-passive setup, just one MSK cluster at a time is actively serving streaming information whereas the opposite cluster is on standby.
Let’s see how that works in observe.
Creating an MSK Replicator throughout AWS Areas
I’ve two MSK clusters deployed in numerous Areas. MSK Replicator requires that the clusters have IAM authentication enabled. I can proceed to make use of different authentication strategies resembling mTLS or SASL for my different shoppers. The supply cluster additionally must allow multi-VPC non-public connectivity.

From a community perspective, the safety teams of the clusters enable site visitors between the cluster and the safety group utilized by the Replicator. For instance, I can add self-referencing inbound and outbound guidelines that enable site visitors from and to the identical safety group. For simplicity, I exploit the default VPC and its default safety group for each clusters.
Earlier than making a replicator, I replace the cluster coverage of the supply cluster to permit the MSK service (together with replicators) to seek out and attain the cluster. Within the Amazon MSK console, I choose the supply Area. I select Clusters from the navigation pane after which the supply cluster. First, I copy the supply cluster ARN on the prime. Then, within the Properties tab, I select Edit cluster coverage within the Safety settings. There, I exploit the next JSON coverage (changing the supply cluster ARN) and save the adjustments:
I choose the goal Area within the console. I select Replicators from the navigation pane after which Create replicator. Right here, I enter a reputation and an outline for the replicator.

Within the Supply cluster part, I choose the Area of the supply MSK cluster. Then, I select Browse to pick out the supply MSK cluster from the record. Word that Replicators could be created just for clusters which have a cluster coverage set.

I go away Subnets and Safety teams as their default values to make use of my default VPC and its default safety group. This community configuration could also be used to put elastic community interfaces (EINs) to facilitate communication along with your cluster.
The Entry management technique for the supply cluster is ready to IAM role-based authentication. Optionally, I can activate a number of authentication strategies on the identical time to proceed to make use of shoppers that want different authentication strategies like mTLS or SASL whereas the Replicator makes use of IAM. For cross-Area replication, the supply cluster can’t have unauthenticated entry enabled, as a result of we use multi-VPC to entry their supply cluster.

Within the Goal cluster part, the Cluster area is ready to the Area the place I’m utilizing the console. I select Browse to pick out the goal MSK cluster from the record.

Much like what I did for the supply cluster, I go away Subnets and Safety teams as their default values. This community configuration is used to put the ENIs required to speak with the goal cluster. The Entry management technique for the goal cluster can be set to IAM role-based authentication.

Within the Replicator settings part, I exploit the default Matter replication configuration, so that every one subjects are replicated. Optionally, I can specify a comma-separated record of standard expressions that point out the names of the subjects to duplicate or to exclude from replication. Within the Extra settings, I can select to repeat subjects configurations, entry management lists (ACLs), and to detect and replica new subjects.

Shopper group replication permits me to specify if shopper group offsets must be replicated in order that, after a switchover, consuming purposes can resume processing close to the place they left off within the main cluster. I can specify a comma-separated record of standard expressions that point out the names of the buyer teams to duplicate or to exclude from replication. I may select to detect and replica new shopper teams. I exploit the default settings that replicate all shopper teams.

In Compression, I choose None from the record of obtainable compression sorts for the information that’s being replicated.

The Amazon MSK console can robotically create a service execution function with the mandatory permissions required for the Replicator to work. The function is utilized by the MSK service to hook up with the supply and goal clusters, to learn from the supply cluster, and to write down to the goal cluster. Nonetheless, I can select to create and supply my very own function as properly. In Entry permissions, I select Create or replace IAM function.

Lastly, I add tags to the replicator. I can use tags to look and filter my sources or to trace my prices. Within the Replicator tags part, I enter Setting as the important thing and AWS Information Weblog as the worth. Then, I select Create.

After a couple of minutes, the replicator is working. Let’s put it into use!
Testing an MSK Replicator throughout AWS Areas
To hook up with the supply and goal clusters, I already arrange two Amazon Elastic Compute Cloud (Amazon EC2) situations within the two Areas. I adopted the directions within the MSK documentation to put in the Apache Kafka shopper instruments. As a result of I’m utilizing IAM authentication, the 2 situations have an IAM function hooked up that permits them to attach, ship, and obtain information from the clusters. To simplify networking, I used the default safety group for the EC2 situations and the MSK clusters.
First, I create a brand new matter within the supply cluster and ship just a few messages. I exploit Amazon EC2 Occasion Connect with log into the EC2 occasion within the supply Area. I alter the listing to the trail the place the Kafka shopper executables have been put in (the trail is determined by the model you employ):
To hook up with the supply cluster, I have to know its bootstrap servers. Utilizing the MSK console within the supply Area, I select Clusters from the navigation web page after which the supply cluster from the record. Within the Cluster abstract part, I select View shopper data. There, I copy the record of Bootstrap servers. As a result of the EC2 occasion is in the identical VPC because the cluster, I copy the record within the Non-public endpoint (single-VPC) column.

Again to the EC2 occasion, I put the record of bootstrap servers within the SOURCE_BOOTSTRAP_SERVERS setting variable.
Now, I create a subject on the supply cluster.
Utilizing the brand new matter, I ship just a few messages to the supply cluster.
Let’s see what occurs within the goal cluster. I connect with the EC2 occasion within the goal Area. Much like what I did for the opposite occasion, I get the record of bootstrap servers for the goal cluster and put it into the TARGET_BOOTSTRAP_SERVERS setting variable.
On the goal cluster, the supply cluster alias is added as a prefix to the replicated matter names. To seek out the supply cluster alias, I select Replicators within the MSK console navigation pane. There, I select the replicator I simply created. Within the Properties tab, I search for the Cluster alias within the Supply cluster part.

I verify the title of the replicated matter by trying on the record of subjects within the goal cluster (it’s the final one within the output record):
Now that I do know the title of the replicated matter on the goal cluster, I begin a shopper to obtain the messages initially despatched to the supply cluster:
Word that I can use a wildcard within the matter subscription (for instance, .*my-topic) to robotically deal with the prefix and have the identical configuration within the supply and goal clusters.
As anticipated, all of the messages I despatched to the supply cluster have been replicated and acquired by the buyer related to the goal cluster.
I can monitor the MSK Replicator latency, throughput, errors, and lag metrics utilizing the Monitoring tab. As a result of this works by way of Amazon CloudWatch, I can simply create my very own alarms and embody these metrics in my dashboards.
To replace the configuration to an active-active setup, I observe comparable steps to create a replicator within the different Area and replicate streaming information between the clusters within the different course. For particulars on find out how to handle failover and failback, see the MSK Replicator documentation.
Availability and Pricing
MSK Replicator is accessible at present in: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Europe (Frankfurt), and Europe (Eire).
With MSK Replicator, you pay per GB of knowledge replicated and an hourly charge for every Replicator. You additionally pay Amazon MSK’s common expenses in your supply and goal MSK clusters and customary AWS expenses for cross-Area information switch. For extra data, see MSK pricing.
Utilizing MSK replicators, you may shortly implement cross-Area and same-Area replication to enhance the resiliency of your structure and retailer information near your companions and finish customers. It’s also possible to use this new functionality to get higher insights by replicating streaming information to a single, centralized cluster the place it’s simpler to run your analytics.
Simplify your information streaming architectures utilizing Amazon MSK Replicator.
— Danilo
[ad_2]
Source link





