[ad_1]

|
Final 12 months, Amazon S3 Glacier celebrated its tenth anniversary. Amazon S3 Glacier is the chief in cloud chilly storage, and I wrote about its improvements over the past decade.
The Amazon S3 Glacier storage courses offer you long-term, safe, and sturdy storage choices to optimally archive your knowledge on the lowest value. The Amazon S3 Glacier storage courses (Amazon S3 Glacier Immediate Retrieval, Amazon S3 Glacier Versatile Retrieval, and Amazon S3 Glacier Deep Archive) are purpose-built for colder knowledge, offering you with retrieval flexibility from milliseconds to days, along with the power to retailer archive knowledge for as little as $1 per terabyte per thirty days.
Many purchasers inform us that they’re preserving their knowledge for longer durations of time as a result of they acknowledge its future worth potential, and that they’re already monetizing subsets of their archival knowledge, or plan to make use of massive units of their archive knowledge sooner or later. Trendy knowledge archiving just isn’t solely about optimizing storage prices for chilly knowledge; it’s additionally about establishing mechanisms in order that when you’ll want to put that knowledge to work for your online business, you may entry it as shortly as your online business necessities demand.
In 2022, AWS prospects restored over 32 billion objects from Amazon S3 Glacier. Clients have to retrieve archived objects shortly when transcoding media, restoring operational backups, coaching machine studying (ML) fashions, or analyzing historic knowledge. Whereas prospects utilizing S3 Glacier Immediate Retrieval can entry their knowledge in simply milliseconds, S3 Glacier Versatile Retrieval is decrease value and gives three retrieval choices: expedited retrievals in 1–5 minutes, customary retrievals in three–5 hours, and free bulk retrievals in 5–12 hours. S3 Glacier Deep Archive is our lowest value storage class and gives knowledge retrieval inside 12 hours utilizing the usual retrieval possibility or 48 hours utilizing the majority retrieval possibility.
In November 2022, Amazon S3 Glacier improved restore throughput by as much as 10 occasions at no further value when retrieving massive volumes of archived knowledge in S3 Glacier Versatile Retrieval and S3 Glacier Deep Archive. With Amazon S3 Batch Operations, you may routinely provoke requests at a quicker fee, permitting you to revive billions of objects containing petabytes of information.
To proceed the decade-long pattern of chilly storage innovation, we’re asserting right now the final availability of quicker Normal retrievals from S3 Glacier Versatile Retrieval by as much as 85 %, at no further value. Sooner knowledge restores routinely apply to the Normal retrieval tier when utilizing S3 Batch Operations.
Utilizing S3 Batch Operations, you may restore archived knowledge at scale by offering a manifest of objects to be retrieved and specifying a retrieval tier. With S3 Batch Operations, restores within the Normal retrieval tier now sometimes start to return objects to you inside minutes, down from three–5 hours, so you may simply pace up your knowledge restores from archive.
Moreover, S3 Batch Operations improves total restore throughput by making use of new efficiency optimizations to your jobs. Consequently, you may restore your knowledge quicker and course of restored objects sooner. Processing restored knowledge in parallel with ongoing restores helps you speed up knowledge workflows and shortly reply to enterprise wants.
Getting Began with Sooner Normal Retrievals from S3 Glacier Versatile Retrieval
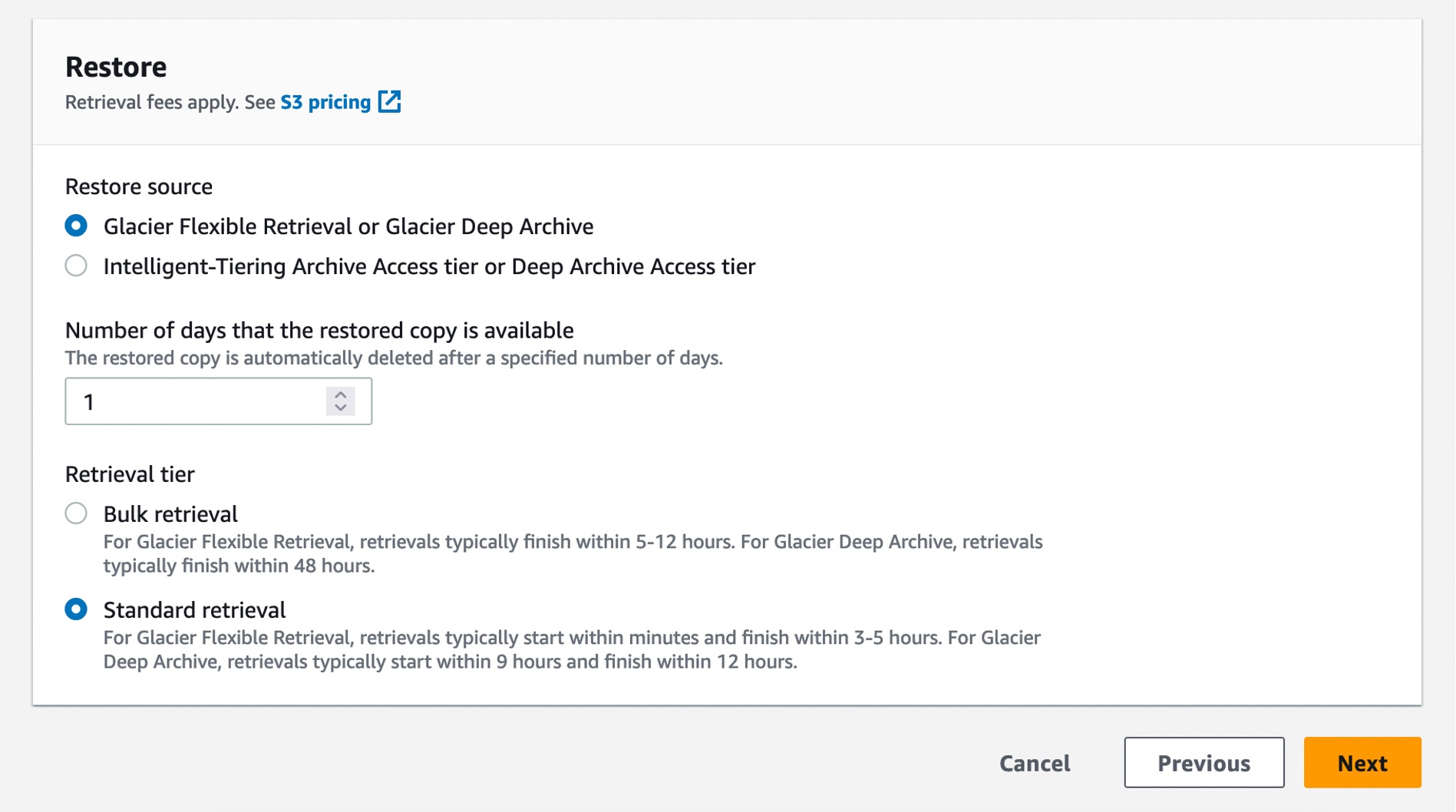
To revive archived knowledge with this efficiency enchancment, you should utilize S3 Batch Operations to carry out each large- and small-scale batch operations on S3 objects. S3 Batch Operations can carry out a single operation on lists of S3 objects that you simply specify. You need to use S3 Batch Operations by way of the AWS Administration Console, AWS Command Line Interface (AWS CLI), SDKs, or REST API.
To create a batch job, select Batch Operations on the left navigation pane of the Amazon S3 console and select Create job. You may choose one of many manifest codecs, an inventory of S3 objects that accommodates object keys that you simply need to retrieve. In case your manifest format is a CSV file, every row within the file should embody the bucket title, object key, and, optionally, the thing model.

Within the subsequent step, select the operation that you simply need to carry out on all objects listed within the manifest. The Restore operation initiates restore requests for archived objects on an inventory of S3 objects that you simply specify. Utilizing a restore operation ends in a restore request for each object that’s specified within the manifest.
While you restore with the Normal retrieval tier from the S3 Glacier Versatile Retrieval storage class, you routinely get quicker retrievals.
It’s also possible to create a restore job with S3InitiateRestoreObject job utilizing the AWS CLI:
$aws s3control create-job
--region us-east-1
--account-id 123456789012
--operation '"S3InitiateRestoreObject": '
--report ''
--manifest ''
--role-arn arn:aws:iam::123456789012:position/s3batch-roleYou may then verify the standing of the job submission of the requests by operating the next CLI command:
$ aws s3control describe-job
--region us-east-1
--account-id 123456789012
--job-id <JobID>
--query 'Job'.'ProgressSummary'You may view and replace the job standing, add notifications and logging, monitor job failures, and generate completion reviews. S3 Batch Operations job exercise is recorded as occasions in AWS CloudTrail. For monitoring job occasions, you may create a customized rule in Amazon EventBridge and ship these occasions to the goal notification useful resource of your selection, equivalent to Amazon Easy Notification Service (Amazon SNS).
While you create an S3 Batch Operations job, you can even request a completion report for all duties or simply for failed duties. The completion report accommodates further data for every activity, together with the thing key title and model, standing, error codes, and descriptions of any errors.
For extra data, see Monitoring job standing and completion reviews within the Amazon S3 Consumer Information.
Right here is the results of a pattern retrieval job with 250 objects, every sized 100 MB. As you may see from the Earlier restore efficiency line (blue line on the proper), these restores would sometimes end in three–5 hours utilizing Normal retrievals. Now, while you use Normal retrievals with S3 Batch Operations, your job sometimes begins inside minutes, as proven within the Improved restore efficiency line (orange line on the left), bettering knowledge restore time by as much as 85 %.

For extra data on this new function and the right way to get began with quicker Normal retrievals from S3 Glacier Versatile Retrieval, watch this introduction video that features a demo walkthrough.
To be taught extra, see Restoring archived objects at scale from the Amazon S3 Glacier storage courses on the AWS Storage Weblog and Restoring an archived object within the Amazon S3 Consumer Information.
Moreover, take a look at this weblog to be taught how one can scale back restoration time and optimize storage prices with quicker restores from Amazon S3 Glacier storage courses and Commvault.
Now Accessible
Sooner customary retrievals for Amazon S3 Glacier Versatile Retrieval at the moment are obtainable in all AWS Areas, together with the AWS GovCloud (US) Areas and China Areas. This efficiency enchancment is offered to you at no further value. You might be charged for S3 Batch Operations and knowledge retrievals. For extra data, see the S3 pricing web page.
 Lastly, we printed a brand new e book titled “Maximize the worth of chilly storage with Amazon S3 Glacier“. Learn this e book to learn the way Amazon S3 Glacier helps organizations of all sizes and from all industries remodel their knowledge archiving to unlock enterprise worth, improve agility, and save on storage prices.
Lastly, we printed a brand new e book titled “Maximize the worth of chilly storage with Amazon S3 Glacier“. Learn this e book to learn the way Amazon S3 Glacier helps organizations of all sizes and from all industries remodel their knowledge archiving to unlock enterprise worth, improve agility, and save on storage prices.
To be taught extra, go to the S3 Glacier storage courses web page and getting began information, and ship suggestions to AWS re:Publish for S3 Glacier or by way of your regular AWS Help contacts.
I’m actually excited so that you can begin utilizing this new function, and I look ahead to listening to about much more methods you might be reinventing your online business with archive knowledge.
— Channy
[ad_2]
Source link





