
[ad_1]

|
Improvements in deep studying (DL), particularly the fast progress of huge language fashions (LLMs), have taken the trade by storm. DL fashions have grown from thousands and thousands to billions of parameters and are demonstrating thrilling new capabilities. They’re fueling new purposes corresponding to generative AI or superior analysis in healthcare and life sciences. AWS has been innovating throughout chips, servers, information heart connectivity, and software program to speed up such DL workloads at scale.
At AWS re:Invent 2022, we introduced the preview of Amazon EC2 Inf2 situations powered by AWS Inferentia2, the most recent AWS-designed ML chip. Inf2 situations are designed to run high-performance DL inference purposes at scale globally. They’re essentially the most cost-effective and energy-efficient possibility on Amazon EC2 for deploying the most recent improvements in generative AI, corresponding to GPT-J or Open Pre-trained Transformer (OPT) language fashions.
In the present day, I’m excited to announce that Amazon EC2 Inf2 situations at the moment are usually obtainable!
Inf2 situations are the primary inference-optimized situations in Amazon EC2 to help scale-out distributed inference with ultra-high-speed connectivity between accelerators. Now you can effectively deploy fashions with lots of of billions of parameters throughout a number of accelerators on Inf2 situations. In comparison with Amazon EC2 Inf1 situations, Inf2 situations ship as much as 4x larger throughput and as much as 10x decrease latency. Right here’s an infographic that highlights the important thing efficiency enhancements that we now have made obtainable with the brand new Inf2 situations:
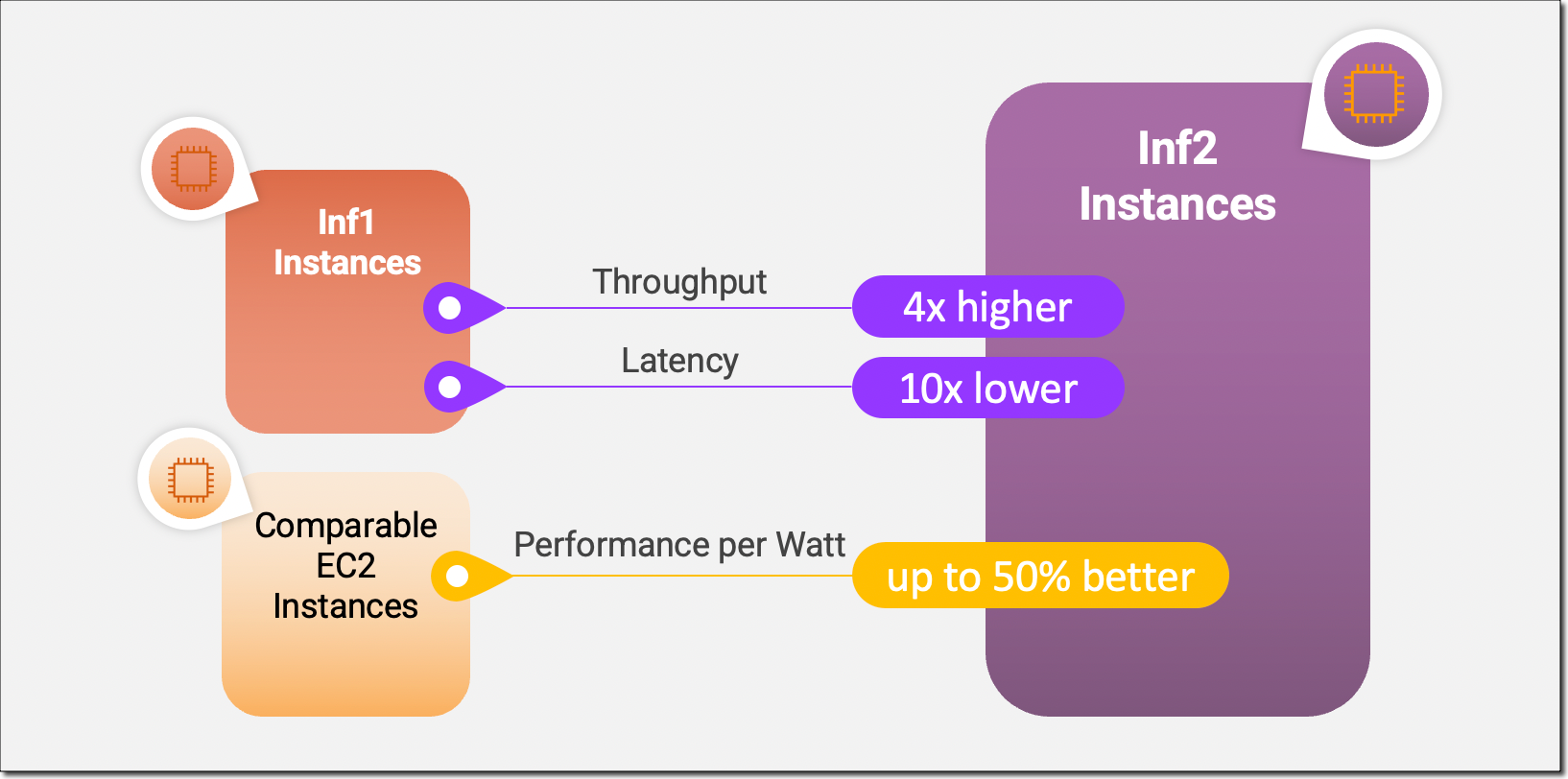
New Inf2 Occasion Highlights
Inf2 situations can be found right now in 4 sizes and are powered by as much as 12 AWS Inferentia2 chips with 192 vCPUs. They provide a mixed compute energy of two.three petaFLOPS at BF16 or FP16 information sorts and have an ultra-high-speed NeuronLink interconnect between chips. NeuronLink scales massive fashions throughout a number of Inferentia2 chips, avoids communication bottlenecks, and allows higher-performance inference.
Inf2 situations supply as much as 384 GB of shared accelerator reminiscence, with 32 GB high-bandwidth reminiscence (HBM) in each Inferentia2 chip and 9.eight TB/s of whole reminiscence bandwidth. This kind of bandwidth is especially necessary to help inference for giant language fashions which can be reminiscence sure.
For the reason that underlying AWS Inferentia2 chips are purpose-built for DL workloads, Inf2 situations supply as much as 50 % higher efficiency per watt than different comparable Amazon EC2 situations. I’ll cowl the AWS Inferentia2 silicon improvements in additional element later on this weblog publish.
The next desk lists the sizes and specs of Inf2 situations intimately.
| Occasion Identify |
vCPUs | AWS Inferentia2 Chips | Accelerator Reminiscence | NeuronLink | Occasion Reminiscence | Occasion Networking |
| inf2.xlarge | four | 1 | 32 GB | N/A | 16 GB | As much as 15 Gbps |
| inf2.8xlarge | 32 | 1 | 32 GB | N/A | 128 GB | As much as 25 Gbps |
| inf2.24xlarge | 96 | 6 | 192 GB | Sure | 384 GB | 50 Gbps |
| inf2.48xlarge | 192 | 12 | 384 GB | Sure | 768 GB | 100 Gbps |
AWS Inferentia2 Innovation
Much like AWS Trainium chips, every AWS Inferentia2 chip has two improved NeuronCore-v2 engines, HBM stacks, and devoted collective compute engines to parallelize computation and communication operations when performing multi-accelerator inference.
Every NeuronCore-v2 has devoted scalar, vector, and tensor engines which can be purpose-built for DL algorithms. The tensor engine is optimized for matrix operations. The scalar engine is optimized for element-wise operations like ReLU (rectified linear unit) features. The vector engine is optimized for non-element-wise vector operations, together with batch normalization or pooling.
Here’s a quick abstract of extra AWS Inferentia2 chip and server improvements:
- Information Varieties – AWS Inferentia2 helps a variety of information sorts, together with FP32, TF32, BF16, FP16, and UINT8, so you possibly can select essentially the most appropriate information kind in your workloads. It additionally helps the brand new configurable FP8 (cFP8) information kind, which is particularly related for giant fashions as a result of it reduces the reminiscence footprint and I/O necessities of the mannequin. The next picture compares the supported information sorts.

- Dynamic Execution, Dynamic Enter Shapes – AWS Inferentia2 has embedded general-purpose digital sign processors (DSPs) that allow dynamic execution, so management stream operators don’t should be unrolled or executed on the host. AWS Inferentia2 additionally helps dynamic enter shapes which can be key for fashions with unknown enter tensor sizes, corresponding to fashions processing textual content.
- Customized Operators – AWS Inferentia2 helps customized operators written in C++. Neuron Customized C++ Operators allow you to write down C++ customized operators that natively run on NeuronCores. You should utilize normal PyTorch customized operator programming interfaces emigrate CPU customized operators to Neuron and implement new experimental operators, all with none intimate information of the NeuronCore .
- NeuronLink v2 – Inf2 situations are the primary inference-optimized occasion on Amazon EC2 to help distributed inference with direct ultra-high-speed connectivity—NeuronLink v2—between chips. NeuronLink v2 makes use of collective communications (CC) operators corresponding to all-reduce to run high-performance inference pipelines throughout all chips.
The next Inf2 distributed inference benchmarks present throughput and value enhancements for OPT-30B and OPT-66B fashions over comparable inference-optimized Amazon EC2 situations.

Now, let me present you methods to get began with Amazon EC2 Inf2 situations.
Get Began with Inf2 Situations
The AWS Neuron SDK integrates AWS Inferentia2 into standard machine studying (ML) frameworks like PyTorch. The Neuron SDK features a compiler, runtime, and profiling instruments and is consistently being up to date with new options and efficiency optimizations.
On this instance, I’ll compile and deploy a pre-trained BERT mannequin from Hugging Face on an EC2 Inf2 occasion utilizing the obtainable PyTorch Neuron packages. PyTorch Neuron relies on the PyTorch XLA software program bundle and allows the conversion of PyTorch operations to AWS Inferentia2 directions.
SSH into your Inf2 occasion and activate a Python digital setting that features the PyTorch Neuron packages. If you happen to’re utilizing a Neuron-provided AMI, you possibly can activate the preinstalled setting by operating the next command:
supply aws_neuron_venv_pytorch_p37/bin/activateNow, with only some adjustments to your code, you possibly can compile your PyTorch mannequin into an AWS Neuron-optimized TorchScript. Let’s begin with importing torch, the PyTorch Neuron bundle torch_neuronx, and the Hugging Face transformers library.
import torch
import torch_neuronx from transformers import AutoTokenizer, AutoModelForSequenceClassification
import transformers
...Subsequent, let’s construct the tokenizer and mannequin.
title = "bert-base-cased-finetuned-mrpc"
tokenizer = AutoTokenizer.from_pretrained(title)
mannequin = AutoModelForSequenceClassification.from_pretrained(title, torchscript=True)We will take a look at the mannequin with instance inputs. The mannequin expects two sentences as enter, and its output is whether or not or not these sentences are a paraphrase of one another.
def encode(tokenizer, *inputs, max_length=128, batch_size=1):
tokens = tokenizer.encode_plus(
*inputs,
max_length=max_length,
padding='max_length',
truncation=True,
return_tensors="pt"
)
return (
torch.repeat_interleave(tokens['input_ids'], batch_size, zero),
torch.repeat_interleave(tokens['attention_mask'], batch_size, zero),
torch.repeat_interleave(tokens['token_type_ids'], batch_size, zero),
)
# Instance inputs
sequence_0 = "The corporate Hugging Face relies in New York Metropolis"
sequence_1 = "Apples are particularly unhealthy in your well being"
sequence_2 = "Hugging Face's headquarters are located in Manhattan"
paraphrase = encode(tokenizer, sequence_0, sequence_2)
not_paraphrase = encode(tokenizer, sequence_0, sequence_1)
# Run the unique PyTorch mannequin on examples
paraphrase_reference_logits = mannequin(*paraphrase)[0]
not_paraphrase_reference_logits = mannequin(*not_paraphrase)[0]
print('Paraphrase Reference Logits: ', paraphrase_reference_logits.detach().numpy())
print('Not-Paraphrase Reference Logits:', not_paraphrase_reference_logits.detach().numpy())The output ought to look much like this:
Paraphrase Reference Logits: [[-0.34945598 1.9003887 ]]
Not-Paraphrase Reference Logits: [[ 0.5386365 -2.2197142]]Now, the torch_neuronx.hint() methodology sends operations to the Neuron Compiler (neuron-cc) for compilation and embeds the compiled artifacts in a TorchScript graph. The tactic expects the mannequin and a tuple of instance inputs as arguments.
neuron_model = torch_neuronx.hint(mannequin, paraphrase)Let’s take a look at the Neuron-compiled mannequin with our instance inputs:
paraphrase_neuron_logits = neuron_model(*paraphrase)[0]
not_paraphrase_neuron_logits = neuron_model(*not_paraphrase)[0]
print('Paraphrase Neuron Logits: ', paraphrase_neuron_logits.detach().numpy())
print('Not-Paraphrase Neuron Logits: ', not_paraphrase_neuron_logits.detach().numpy())The output ought to look much like this:
Paraphrase Neuron Logits: [[-0.34915772 1.8981738 ]]
Not-Paraphrase Neuron Logits: [[ 0.5374032 -2.2180378]]That’s it. With just some strains of code adjustments, we compiled and ran a PyTorch mannequin on an Amazon EC2 Inf2 occasion. To be taught extra about which DL mannequin architectures are an excellent match for AWS Inferentia2 and the present mannequin help matrix, go to the AWS Neuron Documentation.
Accessible Now
You’ll be able to launch Inf2 situations right now within the AWS US East (Ohio) and US East (N. Virginia) Areas as On-Demand, Reserved, and Spot Situations or as a part of a Financial savings Plan. As traditional with Amazon EC2, you pay just for what you employ. For extra data, see Amazon EC2 pricing.
Inf2 situations will be deployed utilizing AWS Deep Studying AMIs, and container pictures can be found by way of managed providers corresponding to Amazon SageMaker, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), and AWS ParallelCluster.
To be taught extra, go to our Amazon EC2 Inf2 situations web page, and please ship suggestions to AWS re:Submit for EC2 or by your traditional AWS Assist contacts.
— Antje
[ad_2]
Source link





