
[ad_1]

|
To construct machine studying fashions, machine studying engineers must develop a knowledge transformation pipeline to organize the info. The method of designing this pipeline is time-consuming and requires a cross-team collaboration between machine studying engineers, information engineers, and information scientists to implement the info preparation pipeline right into a manufacturing surroundings.
The primary goal of Amazon SageMaker Knowledge Wrangler is to make it straightforward to do information preparation and information processing workloads. With SageMaker Knowledge Wrangler, clients can simplify the method of knowledge preparation and the entire vital steps of knowledge preparation workflow on a single visible interface. SageMaker Knowledge Wrangler reduces the time to quickly prototype and deploy information processing workloads to manufacturing, so clients can simply combine with MLOps manufacturing environments.
Nevertheless, the transformations utilized to the shopper information for mannequin coaching must be utilized to new information throughout real-time inference. With out assist for SageMaker Knowledge Wrangler in a real-time inference endpoint, clients want to write down code to duplicate the transformations from their stream in a preprocessing script.
Introducing Assist for Actual-Time and Batch Inference in Amazon SageMaker Knowledge Wrangler
I’m happy to share that you may now deploy information preparation flows from SageMaker Knowledge Wrangler for real-time and batch inference. This function permits you to reuse the info transformation stream which you created in SageMaker Knowledge Wrangler as a step in Amazon SageMaker inference pipelines.
SageMaker Knowledge Wrangler assist for real-time and batch inference accelerates your manufacturing deployment as a result of there isn’t any must repeat the implementation of the info transformation stream. Now you can combine SageMaker Knowledge Wrangler with SageMaker inference. The identical information transformation flows created with the easy-to-use, point-and-click interface of SageMaker Knowledge Wrangler, containing operations resembling Principal Part Evaluation and one-hot encoding, shall be used to course of your information throughout inference. Because of this you don’t should rebuild the info pipeline for a real-time and batch inference utility, and you will get to manufacturing quicker.
Get Began with Actual-Time and Batch Inference
Let’s see how you can use the deployment helps of SageMaker Knowledge Wrangler. On this state of affairs, I’ve a stream inside SageMaker Knowledge Wrangler. What I must do is to combine this stream into real-time and batch inference utilizing the SageMaker inference pipeline.
First, I’ll apply some transformations to the dataset to organize it for coaching.
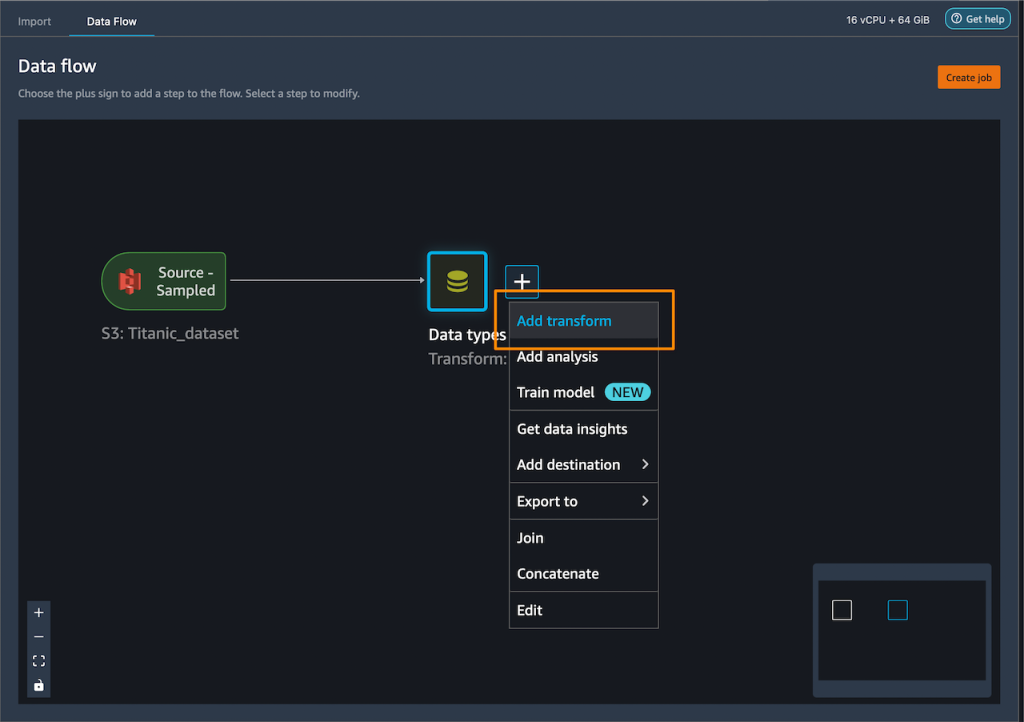
I add one-hot encoding on the explicit columns to create new options.
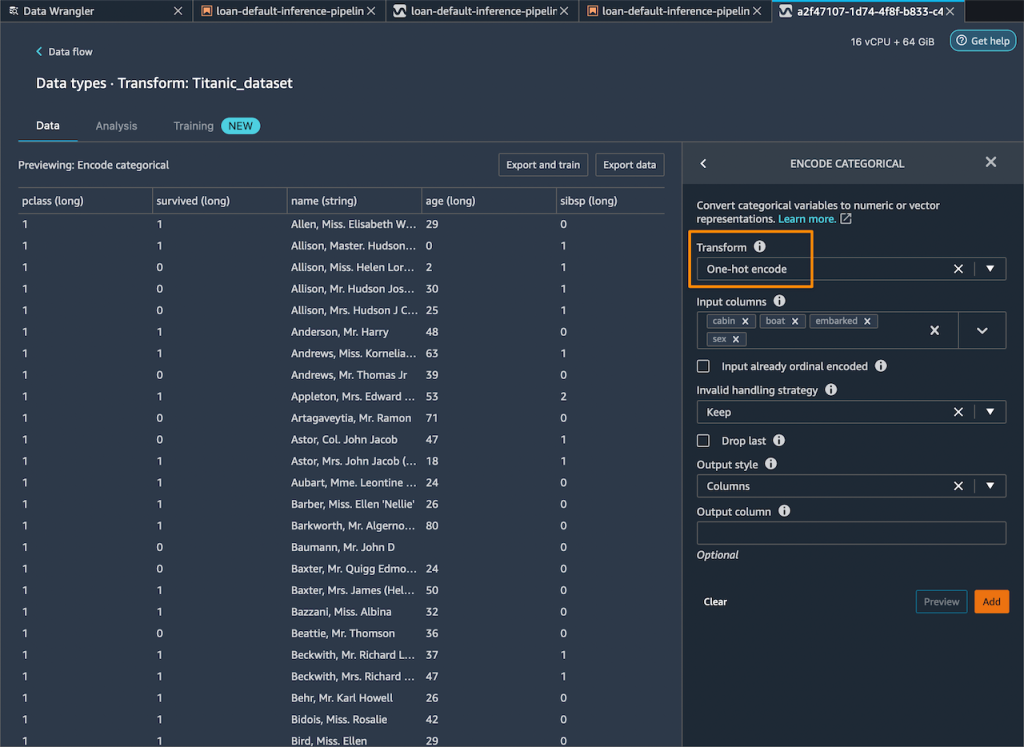
Then, I drop any remaining string columns that can’t be used throughout coaching.

My ensuing stream now has these two rework steps in it.
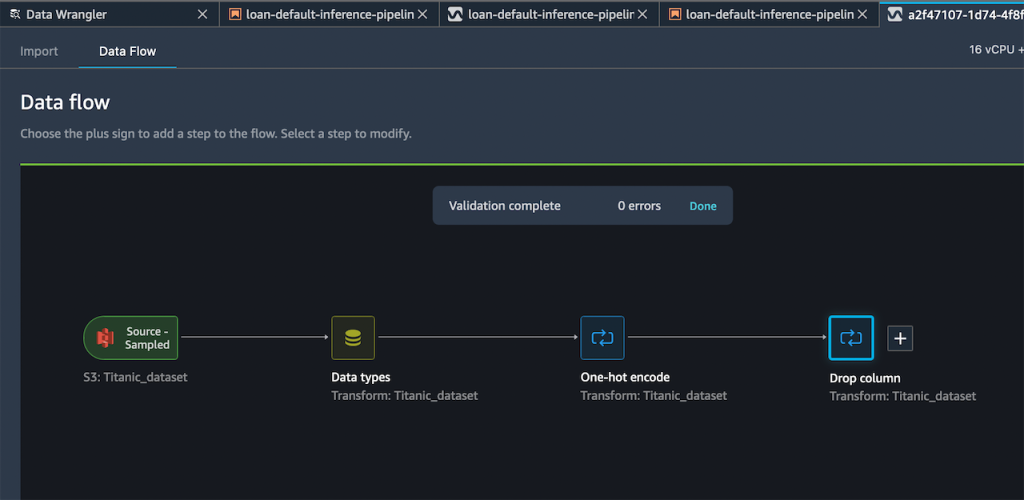
After I’m happy with the steps I’ve added, I can broaden the Export to menu, and I’ve the choice to export to SageMaker Inference Pipeline (through Jupyter Pocket book).

I choose Export to SageMaker Inference Pipeline, and SageMaker Knowledge Wrangler will put together a totally custom-made Jupyter pocket book to combine the SageMaker Knowledge Wrangler stream with inference. This generated Jupyter pocket book performs a number of vital actions. First, outline information processing and mannequin coaching steps in a SageMaker pipeline. The following step is to run the pipeline to course of my information with Knowledge Wrangler and use the processed information to coach a mannequin that shall be used to generate real-time predictions. Then, deploy my Knowledge Wrangler stream and educated mannequin to a real-time endpoint as an inference pipeline. Final, invoke my endpoint to make a prediction.

This function makes use of Amazon SageMaker Autopilot, which makes it straightforward for me to construct ML fashions. I simply want to offer the remodeled dataset which is the output of the SageMaker Knowledge Wrangler step and choose the goal column to foretell. The remainder shall be dealt with by Amazon SageMaker Autopilot to discover varied options to search out the very best mannequin.

Utilizing AutoML as a coaching step from SageMaker Autopilot is enabled by default within the pocket book with the use_automl_step variable. When utilizing the AutoML step, I must outline the worth of target_attribute_name, which is the column of my information I need to predict throughout inference. Alternatively, I can set use_automl_step to False if I need to use the XGBoost algorithm to coach a mannequin as an alternative.
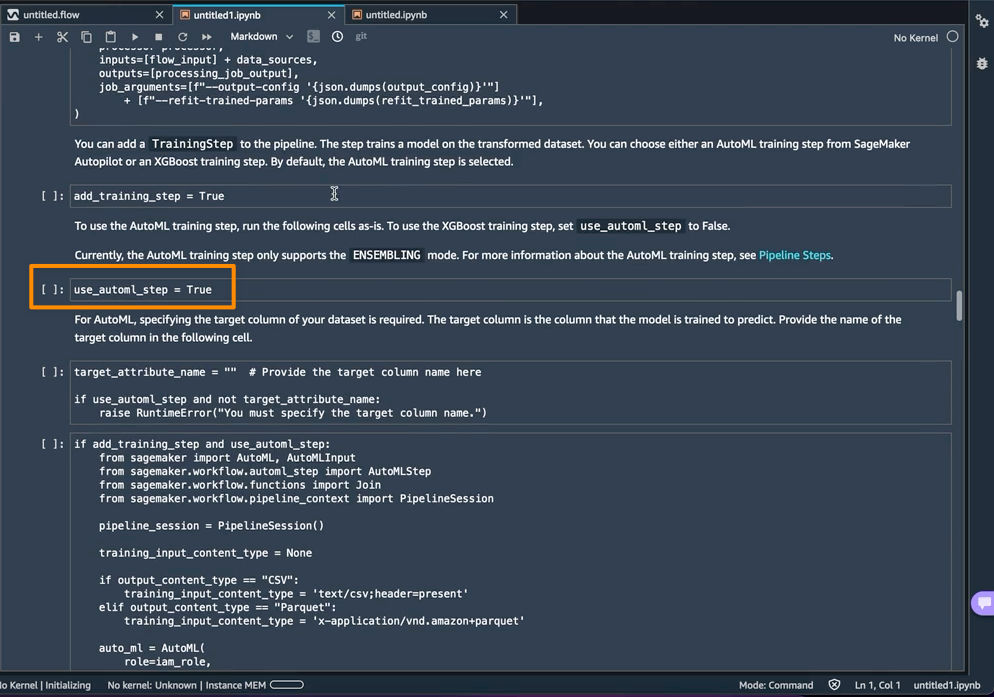
Then again, if I wish to as an alternative use a mannequin I educated exterior of this pocket book, then I can skip on to the Create SageMaker Inference Pipeline part of the pocket book. Right here, I would want to set the worth of the byo_model variable to True. I additionally want to offer the worth of algo_model_uri, which is the Amazon Easy Storage Service (Amazon S3) URI the place my mannequin is situated. When coaching a mannequin with the pocket book, these values shall be auto-populated.
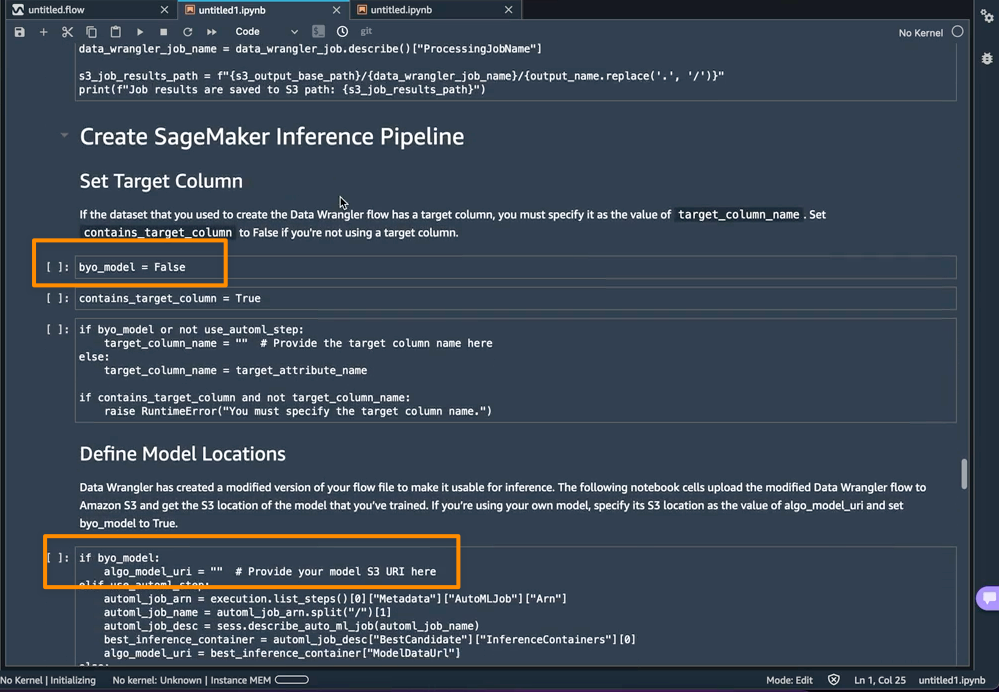
As well as, this function additionally saves a tarball contained in the data_wrangler_inference_flows folder on my SageMaker Studio occasion. This file is a modified model of the SageMaker Knowledge Wrangler stream, containing the info transformation steps to be utilized on the time of inference. Will probably be uploaded to S3 from the pocket book in order that it may be used to create a SageMaker Knowledge Wrangler preprocessing step within the inference pipeline.
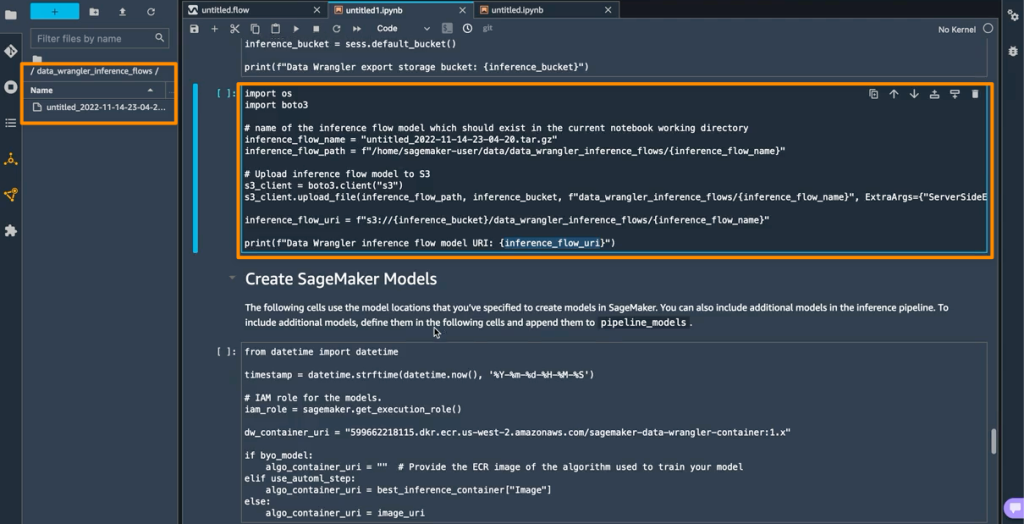
The following step is that this pocket book will create two SageMaker mannequin objects. The primary object mannequin is the SageMaker Knowledge Wrangler mannequin object with the variable data_wrangler_model, and the second is the mannequin object for the algorithm, with the variable algo_model. Object data_wrangler_model shall be used to offer enter within the type of information that has been processed into algo_model for prediction.
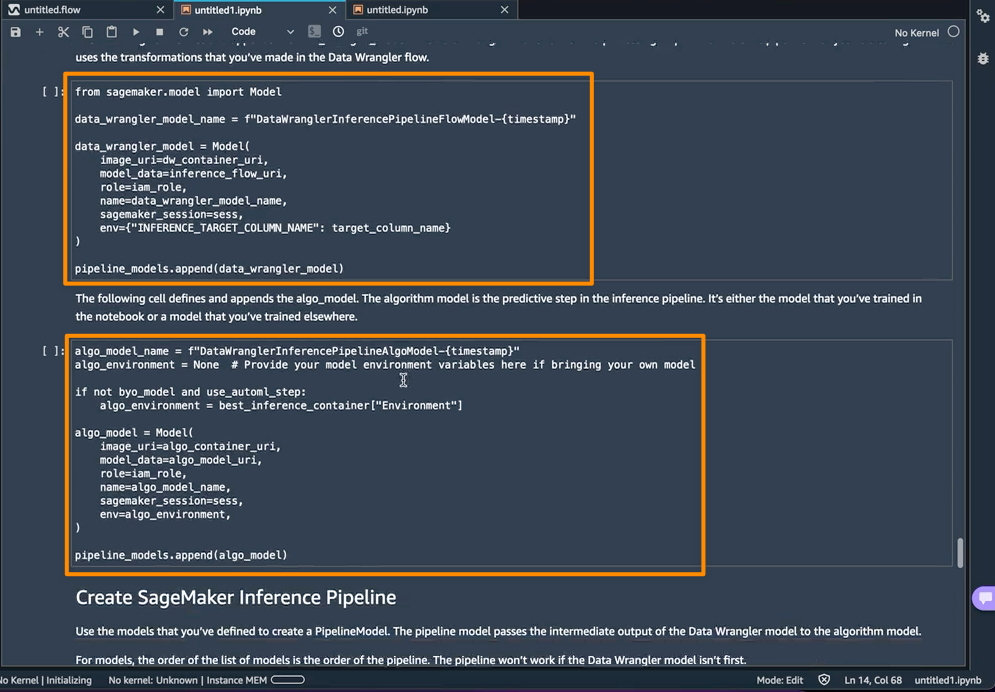
The ultimate step inside this pocket book is to create a SageMaker inference pipeline mannequin, and deploy it to an endpoint.
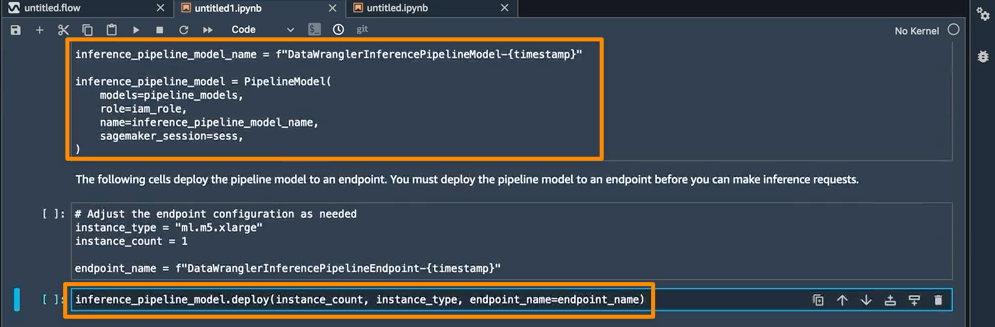
As soon as the deployment is full, I’ll get an inference endpoint that I can use for prediction. With this function, the inference pipeline makes use of the SageMaker Knowledge Wrangler stream to rework the info out of your inference request right into a format that the educated mannequin can use.
Within the subsequent part, I can run particular person pocket book cells in Make a Pattern Inference Request. That is useful if I must do a fast verify to see if the endpoint is working by invoking the endpoint with a single information level from my unprocessed information. Knowledge Wrangler mechanically locations this information level into the pocket book, so I don’t have to offer one manually.
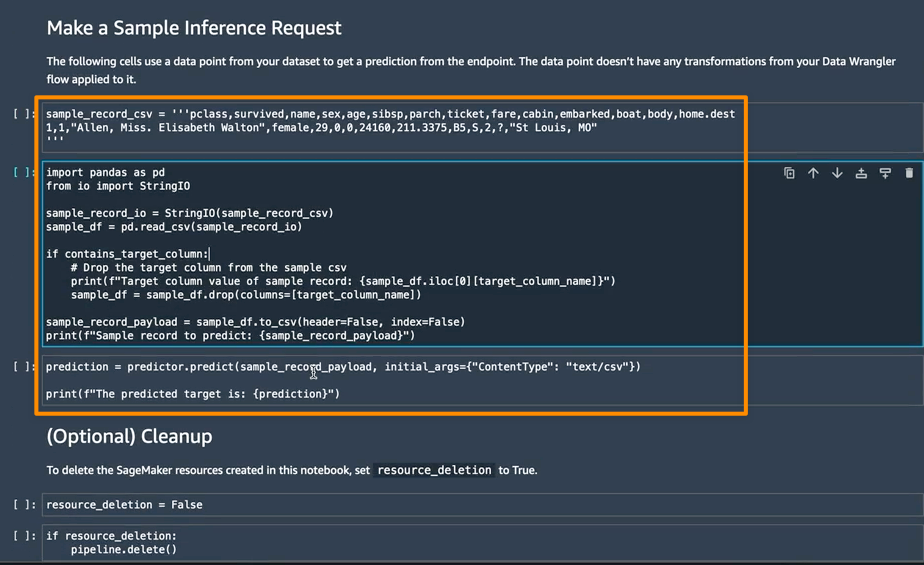
Issues to Know
Enhanced Apache Spark configuration — On this launch of SageMaker Knowledge Wrangler, now you can simply configure how Apache Spark partitions the output of your SageMaker Knowledge Wrangler jobs when saving information to Amazon S3. When including a vacation spot node, you’ll be able to set the variety of partitions, akin to the variety of recordsdata that shall be written to Amazon S3, and you may specify column names to partition by, to write down information with completely different values of these columns to completely different subdirectories in Amazon S3. Furthermore, it’s also possible to outline the configuration within the offered pocket book.

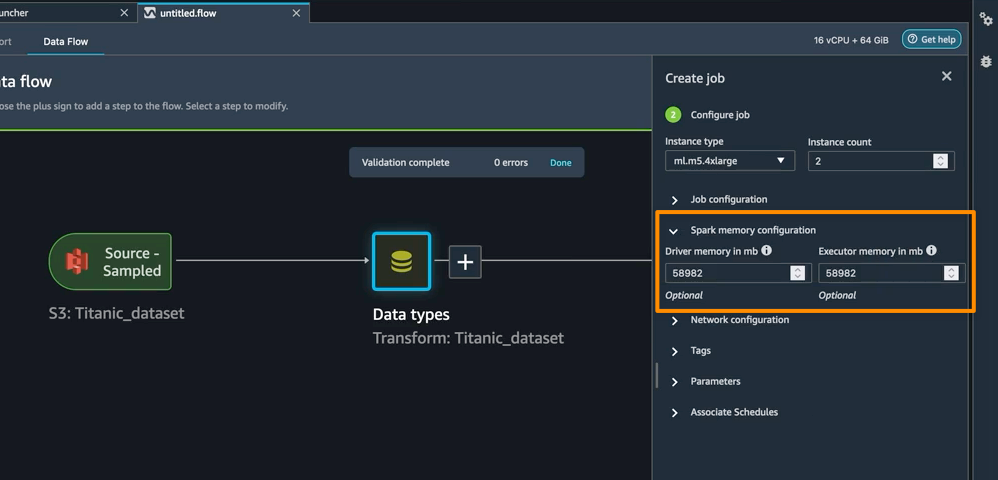
It’s also possible to outline reminiscence configurations for SageMaker Knowledge Wrangler processing jobs as a part of the Create job workflow. You can find related configuration as a part of your pocket book.
Availability — SageMaker Knowledge Wrangler helps for real-time and batch inference in addition to enhanced Apache Spark configuration for information processing workloads are usually accessible in all AWS Areas that Knowledge Wrangler at the moment helps.
To get began with Amazon SageMaker Knowledge Wrangler helps for real-time and batch inference deployment, go to AWS documentation.
Glad constructing
— Donnie
[ad_2]
Source link





