
[ad_1]
Managing experiments is without doubt one of the predominant challenges for information science groups.
Discovering the very best modeling method that works for a specific downside requires each speculation testing and trial-and-error. Monitoring growth and outcomes utilizing docs and spreadsheets is neither dependable nor simple to share. Consequently the method of ML growth is severely affected.
Certainly, not having a monitoring service results in handbook copy/pasting of the parameters and metrics. With an growing variety of experiments, a mannequin builder received’t be capable to reproduce the information and mannequin configuration that was used to coach fashions. Consequently the mannequin’s predictive conduct and efficiency adjustments can’t be verified.
This lack of know-how is much more impactful when you’ve completely different groups concerned in a number of use instances.
At scale, the steps of an ML experiment must be orchestrated utilizing pipelines. However how can information science groups assure fast iteration of experiments and higher readiness on the similar time with out the advantage of having a centralized location to handle and validate the outcomes?
Backside line is that it’s a lot tougher to show your mannequin into an asset for the corporate and its enterprise.
To deal with these challenges, we’re excited to announce the overall availability of Vertex AI Experiments, the managed experiment monitoring service on Vertex AI.
Vertex AI Experiments is designed not just for monitoring however for supporting seamless experimentation. The service allows you to monitor parameters, visualize and examine the efficiency metrics of your mannequin and pipeline experiments. On the similar time, Vertex AI Experiments offers an experiment lineage you should use to signify every step concerned in arriving at the very best mannequin configuration.
On this weblog, we’ll dive into how Vertex AI Experiments works, showcasing the options that allow you to:
-
monitor parameters and metrics of fashions skilled regionally utilizing the Vertex AI SDK
-
create experiment lineage (for instance, information preprocessing, characteristic engineering) of experiment artifacts that others inside your group can reuse
-
document the coaching configuration of a number of pipeline runs
However earlier than we dive deeper, let’s make clear what a Vertex AI Experiment is.
Run, Experiment and the Metadata service
In Vertex AI Experiments, you’ve two predominant ideas : run and experiment.
Runs are related to a specific coaching configuration information scientist took whereas fixing a specific ML problem. For every run you’ll be able to document:
-
Parameters as key-value inputs of the run,
-
Abstract and time-series metrics (the metrics recorded on the finish of every epoch) as key-value outputs of the run,
-
Artifacts together with enter information, remodeled datasets and skilled fashions.
As a result of you will have a number of runs, you’ll be able to arrange them into an experiment, which is the highest stage container for all the things practitioner does to unravel a specific information science problem.
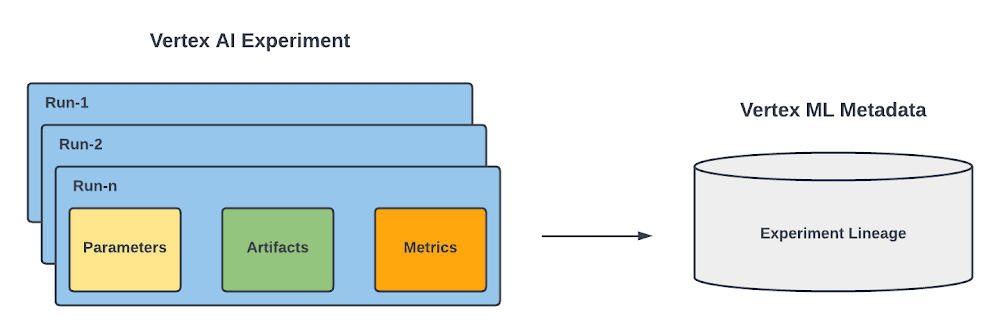
|
Determine 1. Run, Experiment and the Metadata service |
Discover that each runs and experiments leverages Vertex ML Metadata, which is a managed ML Metadata retailer primarily based on the open supply ML Metadata (MLMD) library developed by Google’s TensorFlow Prolonged group. It allows you to document, analyze, debug, and audit metadata and artifacts produced throughout your ML journey. Within the case of Vertex AI Experiments, it means that you can visualize the ML lineage of your ML experiment.
Now that you realize what a Vertex AI Experiment is, let’s see how one can leverage its capabilities to deal with the potential challenges of monitoring and managing your experiments at scale.
Evaluating fashions skilled and evaluated regionally
As a Information scientist, you in all probability will begin coaching your mannequin regionally. To seek out the optimum modeling method, you want to check out completely different configurations.
For instance, if you’re constructing a TensorFlow mannequin, you’d wish to monitor information parameters reminiscent of `buffer_size` or the `batch_size` of the tf.information.Dataset , and mannequin parameters reminiscent of layer title, the `learning_rate` of the optimizer , and `metrics` you wish to optimize.
As quickly as you strive a number of configurations , you’ll need to guage the ensuing mannequin by producing metrics for additional evaluation.
With Vertex AI Experiments, you’ll be able to simply create an experiment and log each parameters, metrics, and artifacts which are related along with your experiment runs by utilizing each the Vertex AI part of the Google Cloud console and the Vertex AI Python SDK.
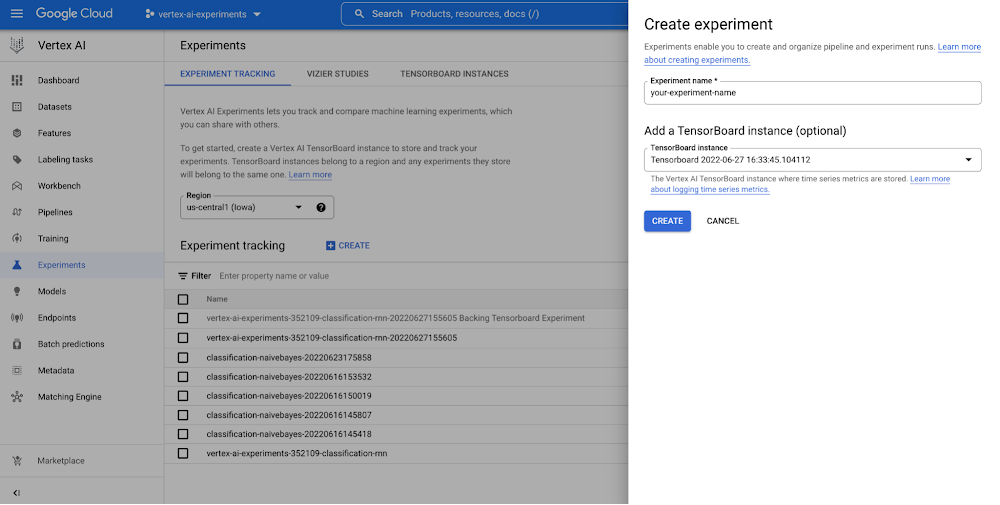
|
Determine 2. Create an experiment (console) |
Discover additionally that the SDK offers a helpful initialization technique that means that you can create a TensorBoard occasion utilizing Vertex AI TensorBoard for logging mannequin time collection metrics. Beneath you’ll be able to see learn how to begin an experiment, log mannequin parameters and monitor analysis metrics each per epoch and on the finish of the coaching session.
- code_block
- [StructValue([(u’code’, u’# Create Tensorboard instance and initialize Vertex AI clientrnvertex_ai_tb = vertex_ai.Tensorboard.create()rnvertex_ai.init(experiment=my_tensorflow_experiment, experiment_tensorboard=vertex_ai_tb)rnrn# Initialize the experimentrnwith vertex_ai.start_run(“run-1”) as run:rnrn # Log model parameters and build the modelrn run.log_params()rn model = get_model(model_params=model_params)rnrn # Train the modelrn history = train(model=model,rn train_dataset=train_dataset,rn test_dataset=test_dataset,rn epochs=epochs,rn steps=steps)rn rn # Log metrics recorded at the end of each epoch rn for idx in range(0, history.params[“epochs”]):rn vertex_ai.log_time_series_metrics()rnrn # Consider mannequin and log analysis metricsrn test_loss, test_accuracy = mannequin.consider(test_dataset)rn vertex_ai.log_metrics(“test_loss”: test_loss, “test_accuracy”: test_accuracy)’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e853839c250>)])]
Then you’ll be able to analyze the results of the experiment by viewing the Vertex AI part of the Google Cloud console or by retrieving them within the pocket book. This video exhibits what it will appear like.
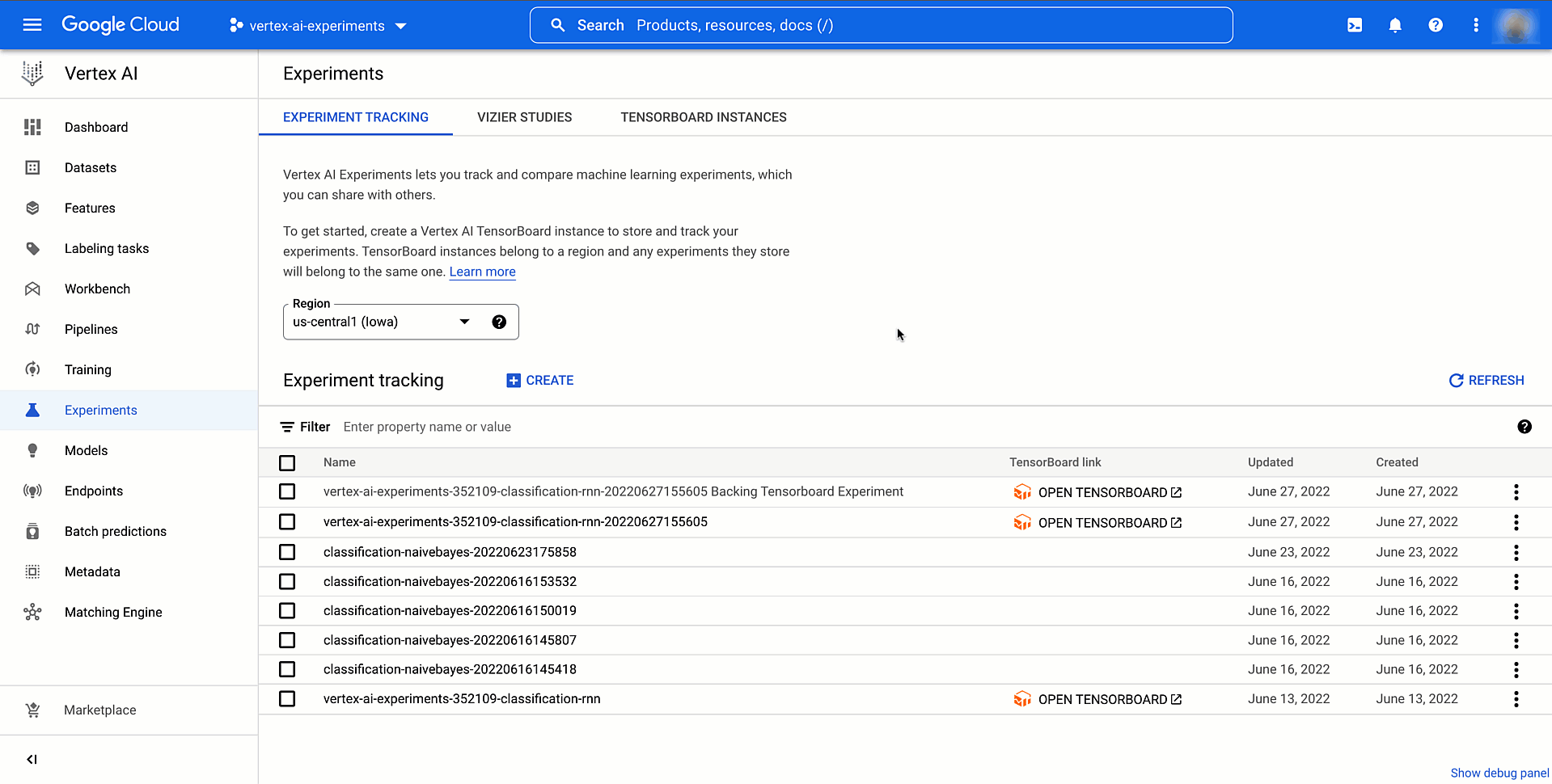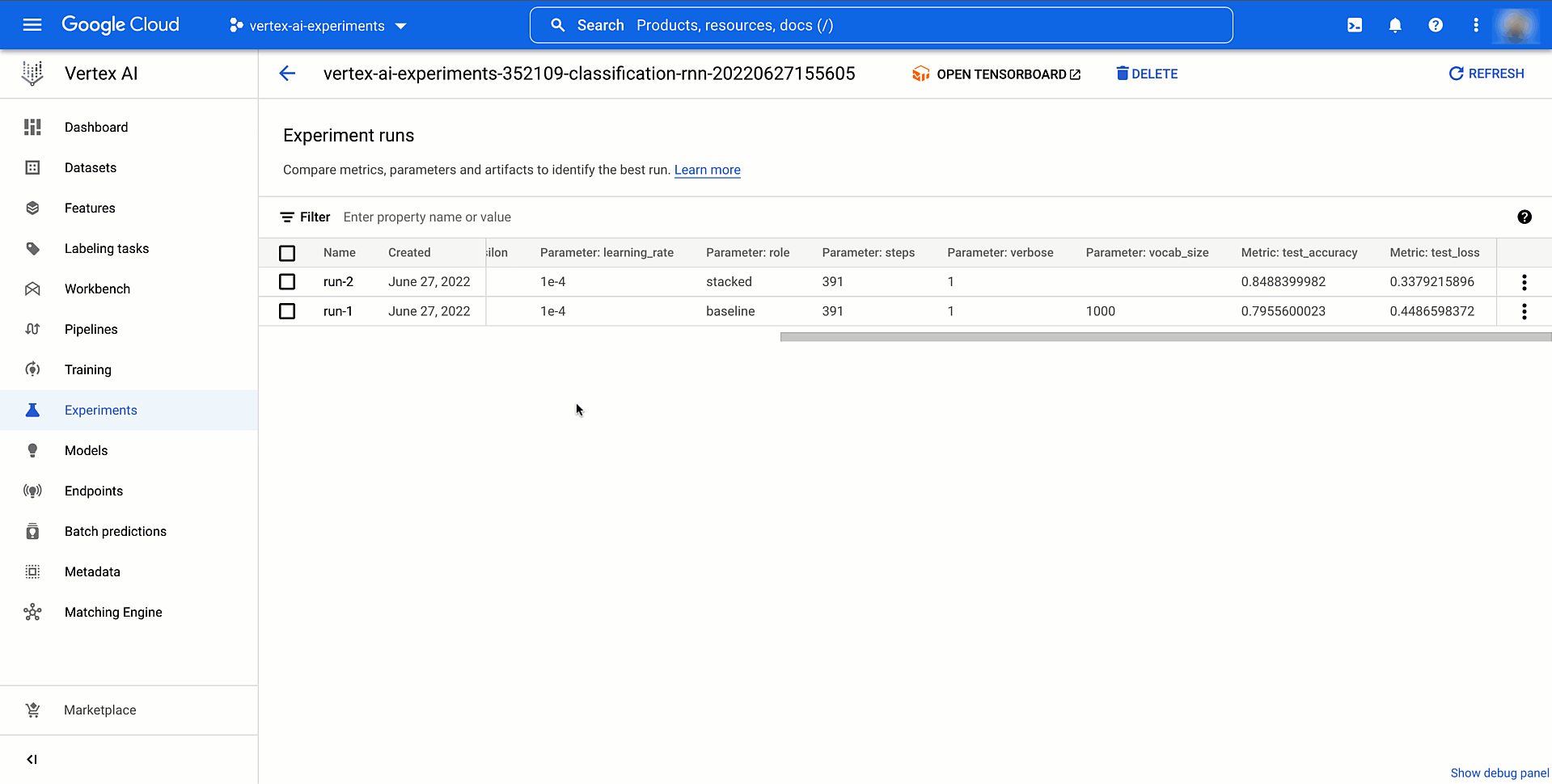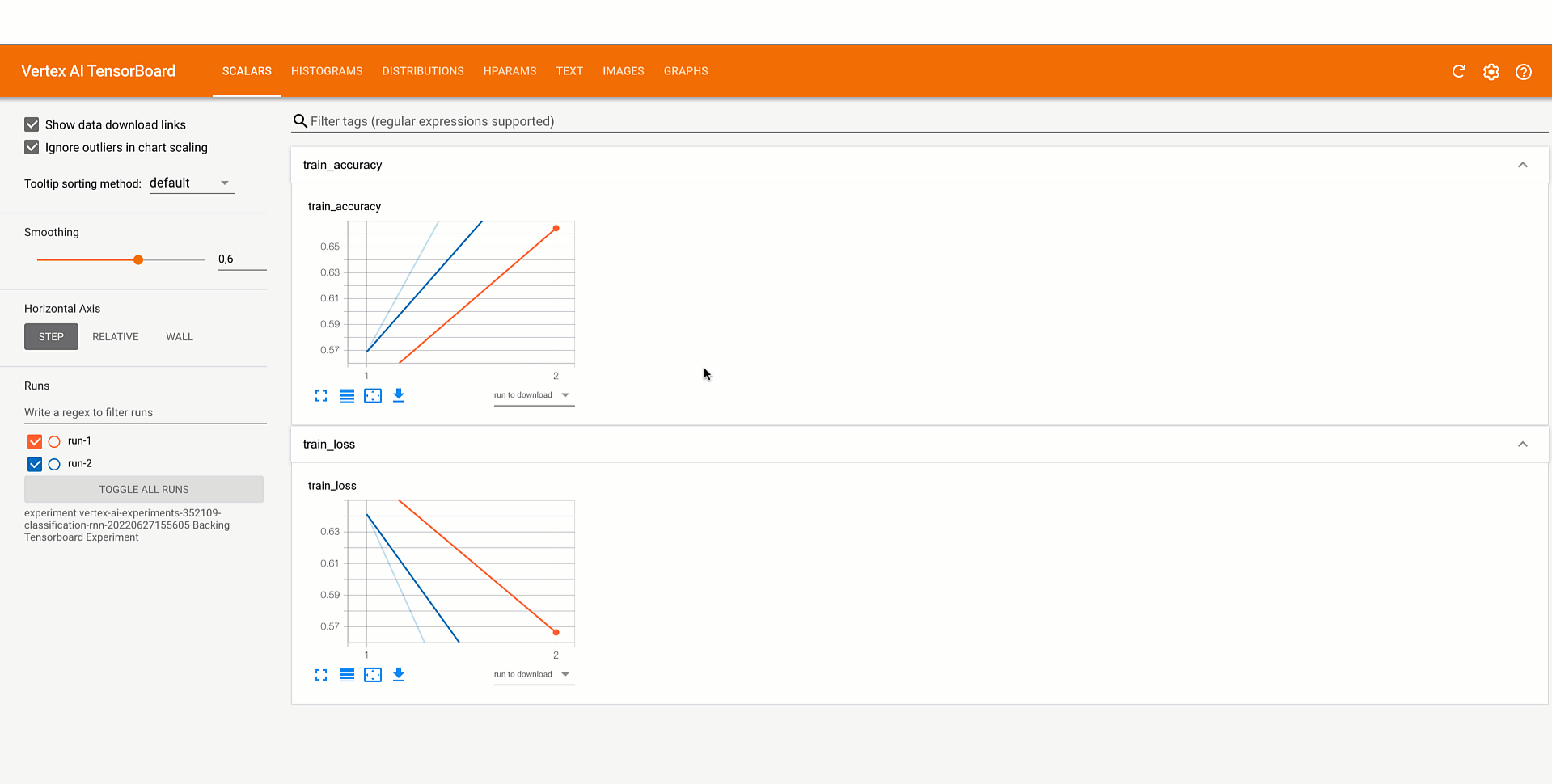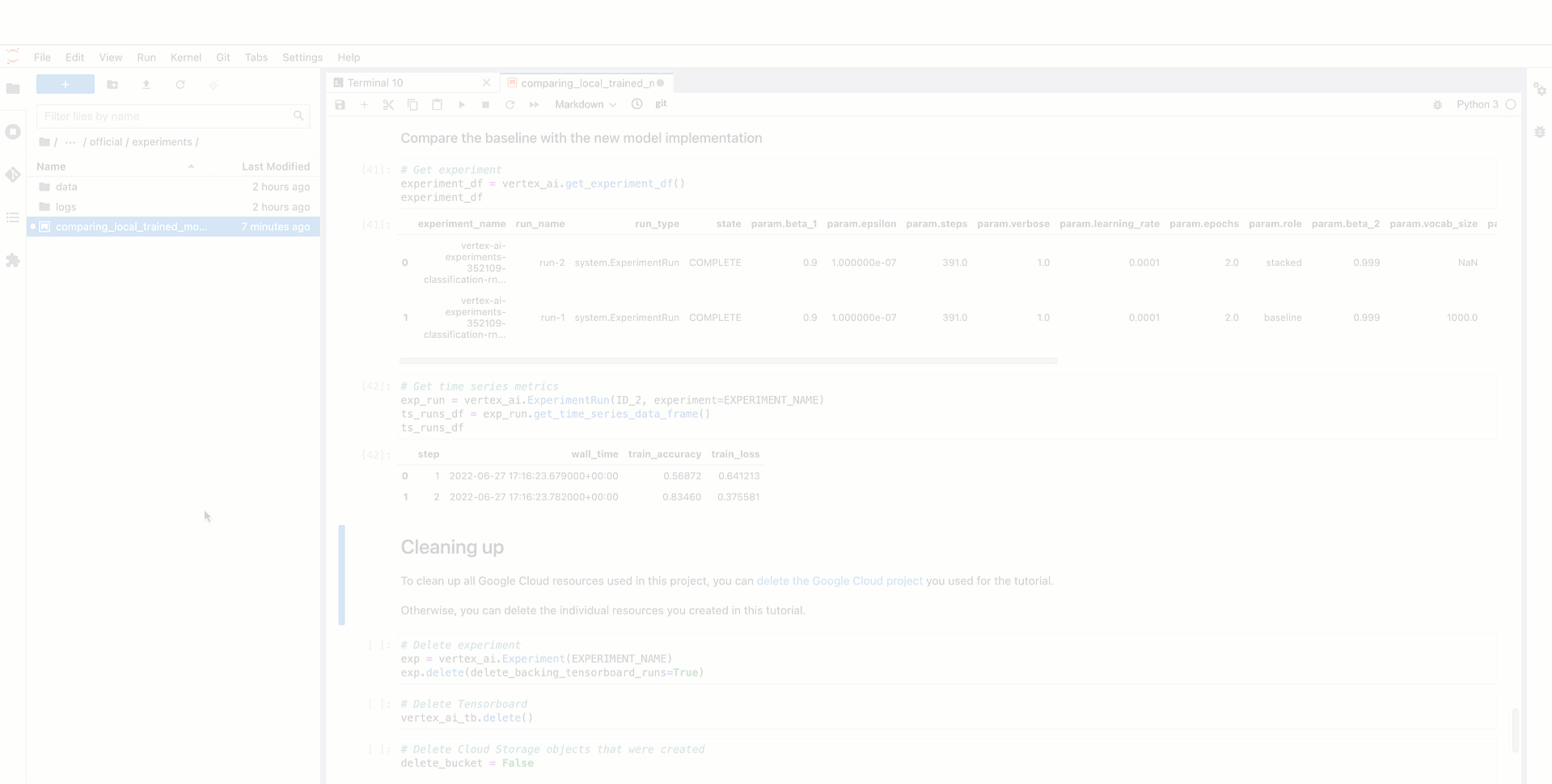
|
Determine three. Examine fashions skilled and evaluated regionally with Vertex AI Experiments |
Monitoring mannequin coaching experiment lineage
The mannequin coaching is only a single step in an experiment. Some information preprocessing can also be required that others inside your group could have written. For that motive, you want a strategy to simply combine preprocessing steps and document the ensuing dataset to reuse it alongside a number of experiment runs.
By leveraging the mixing with Vertex ML Metadata, Vertex AI Experiments means that you can monitor the information preprocessing as a part of the experiment lineage by working an Vertex ML Metadata execution in your experiment context. Right here you’ll be able to see learn how to use execution to combine preprocessing code in a Vertex AI Experiments.
- code_block
- [StructValue([(u’code’, u’# Create the dataset artifactrnraw_dataset_artifact = vertex_ai.Artifact.create(rn schema_title=”system.Dataset”, rn display_name=”my-raw-dataset”, rn uri=”my-raw-dataset-uri”rn)rnrn# Initiate the preprocessing execution rnwith vertex_ai.start_execution(schema_title=”system.ContainerExecution”,rn display_name=”preprocess”rn ) as exc:rnrn # Assign raw dataset as input artifactrn exc.assign_input_artifacts([raw_dataset_artifact])rnrn # Log preprocessing paramsrn vertex_ai.log_params()rnrn # Preprocessing rn raw_df = pd.read_csv(raw_dataset_artifact.uri)rn preprocessed_df = your_preprocess_function(raw_df)rn preprocessed_df.to_csv(“gs://vertex-ai-experiments-demo/preprocess_data.csv”)rnrn # Log preprocessing metricsrn vertex_ai.log_metrics()rn rn # File the preprocessed dataset as output artifactrn preprocessed_dataset_metadata = vertex_ai.Artifact.create(rn schema_title=”system.Dataset”,display_name=”my-preprocessed-dataset-name”,rn uri=”gs://vertex-ai-experiments-demo/preprocess_data.csv”,rn )rn exc.assign_output_artifacts([preprocessed_dataset_metadata])’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e85357cc290>)])]
As soon as the execution is instantiated, you begin recording the information preprocessing step. You possibly can assign the dataset as enter artifact, devour the dataset within the preprocessing code and cross the preprocessed dataset as output artifact of the execution. Then, that preprocessing step and its dataset, are robotically recorded as a part of the experiment lineage and they’re able to be consumed as enter artifacts of various coaching run executions related to the identical experiment. That is how the coaching execution would appear like with the ensuing mannequin uploaded as an mannequin artifact after coaching efficiently completed.
- code_block
- [StructValue([(u’code’, u’# Provoke the prepare executionrnwith vertex_ai.start_execution(schema_title=”system.ContainerExecution”, display_name=”prepare”) as exc:rnrn exc.assign_input_artifacts([preprocessed_dataset_metadata])rnrn # Log information parametersrn vertex_ai.log_params()rnrnrnrnrn # Get coaching and testing datarn x_train, x_val, y_train, y_val = get_training_split(preprocessed_df[[“feature1″,”feature2″,”feature3”]], preprocessed_df[“target”], test_size=zero.2, random_state=eight)rn # Get and prepare mannequin pipeline rn pipeline = get_pipeline()rn trained_pipeline = train_pipeline(pipeline, x_train, y_train)rnrn # Consider mannequin and log coaching metricsrn model_metrics = evaluate_model(trained_pipeline, x_val, y_val)rn vertex_ai.log_metrics(model_metrics)rnrn # Add Modelrn loaded = save_model(trained_pipeline, “gs://vertex-ai-experiments-demo/mannequin.joblib”)rnrn #File the skilled mannequin as output artifactrn mannequin = vertex_ai.Mannequin.add(rn serving_container_image_uri=”serving-container-image-uri”,rn artifact_uri=”gs://vertex-ai-experiments-demo/mannequin.joblib”,rn display_name=”my-model”,rn )rnrn exc.assign_output_artifacts([model])’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e85357ccd50>)])]
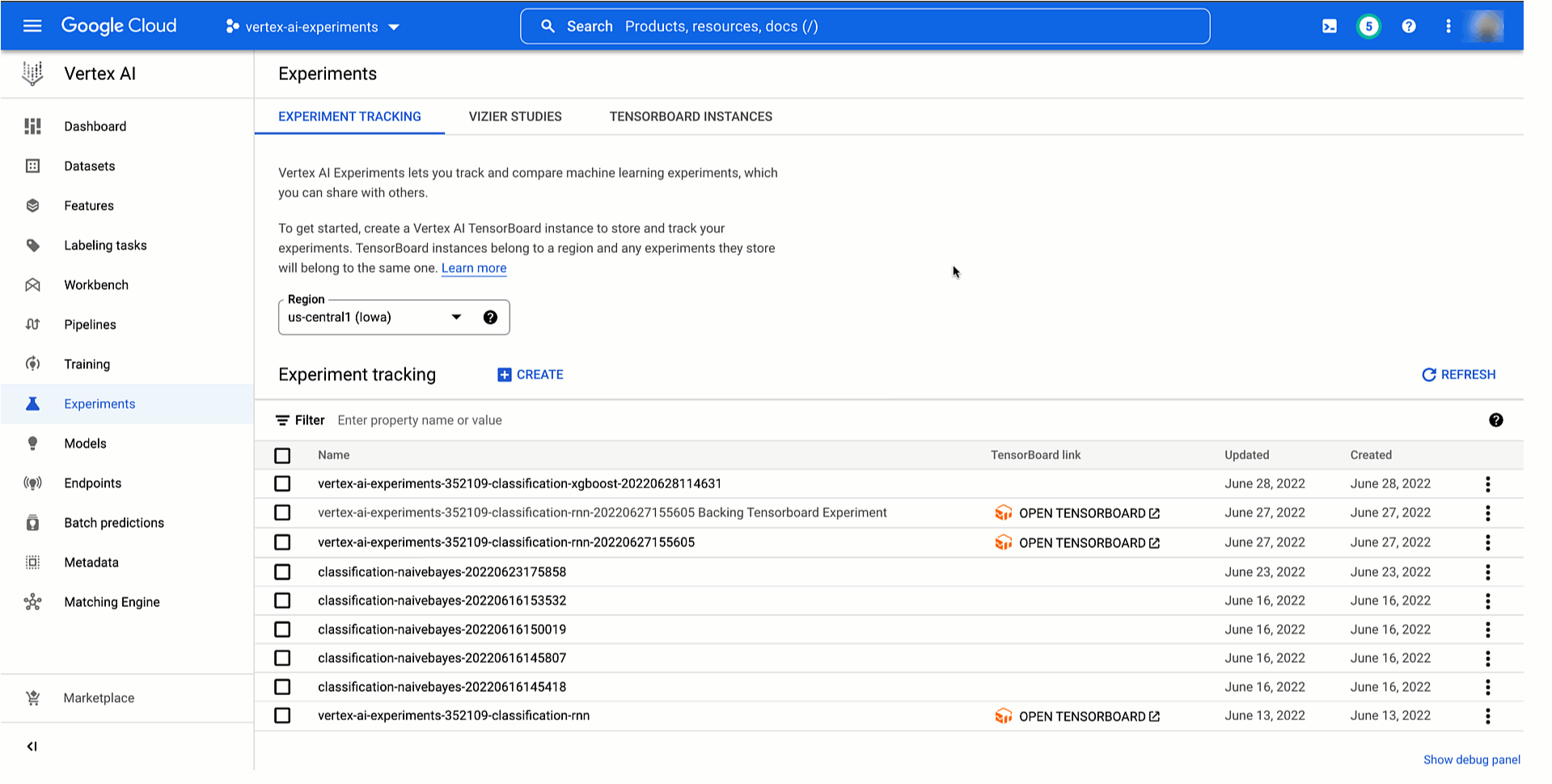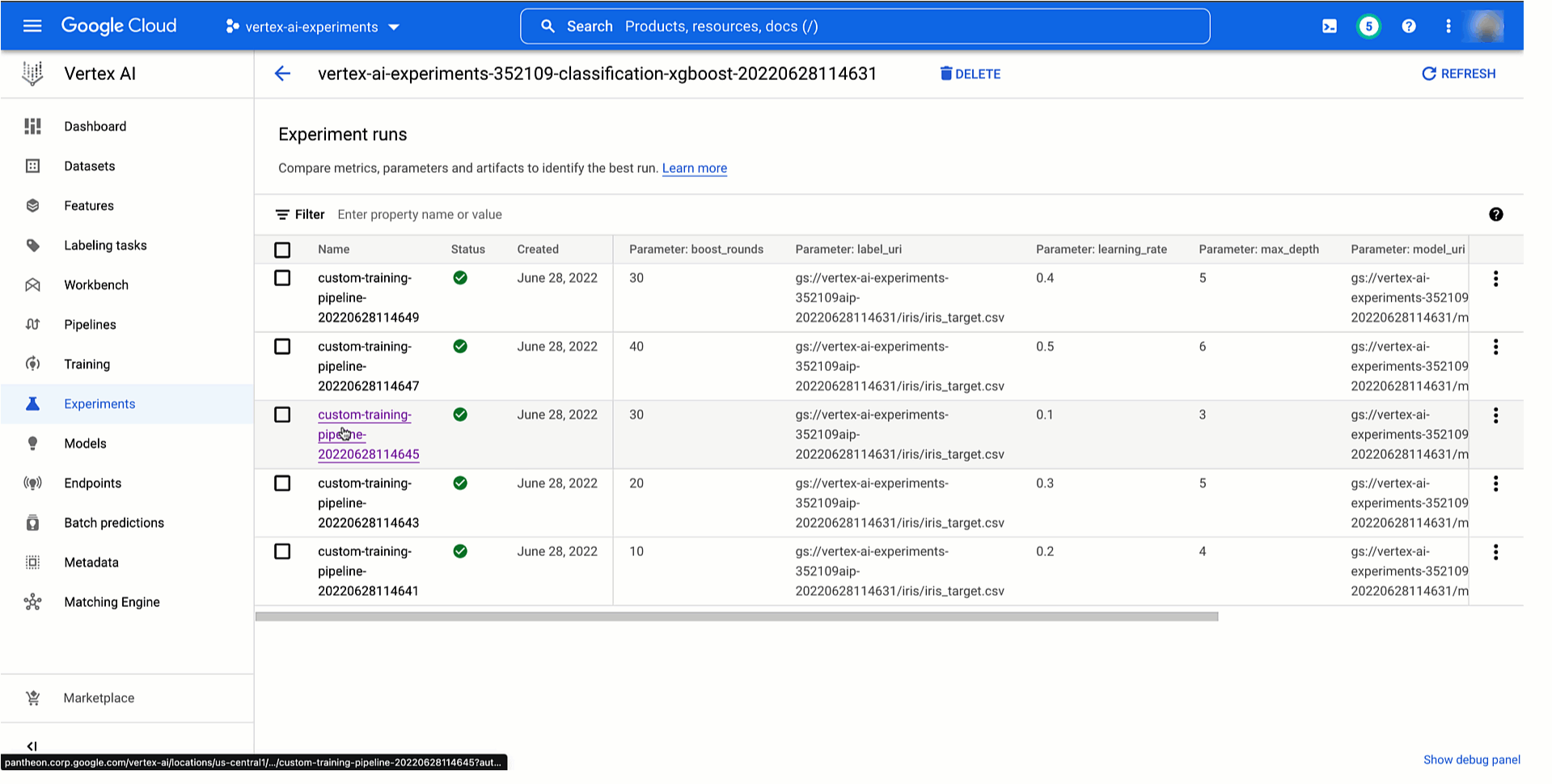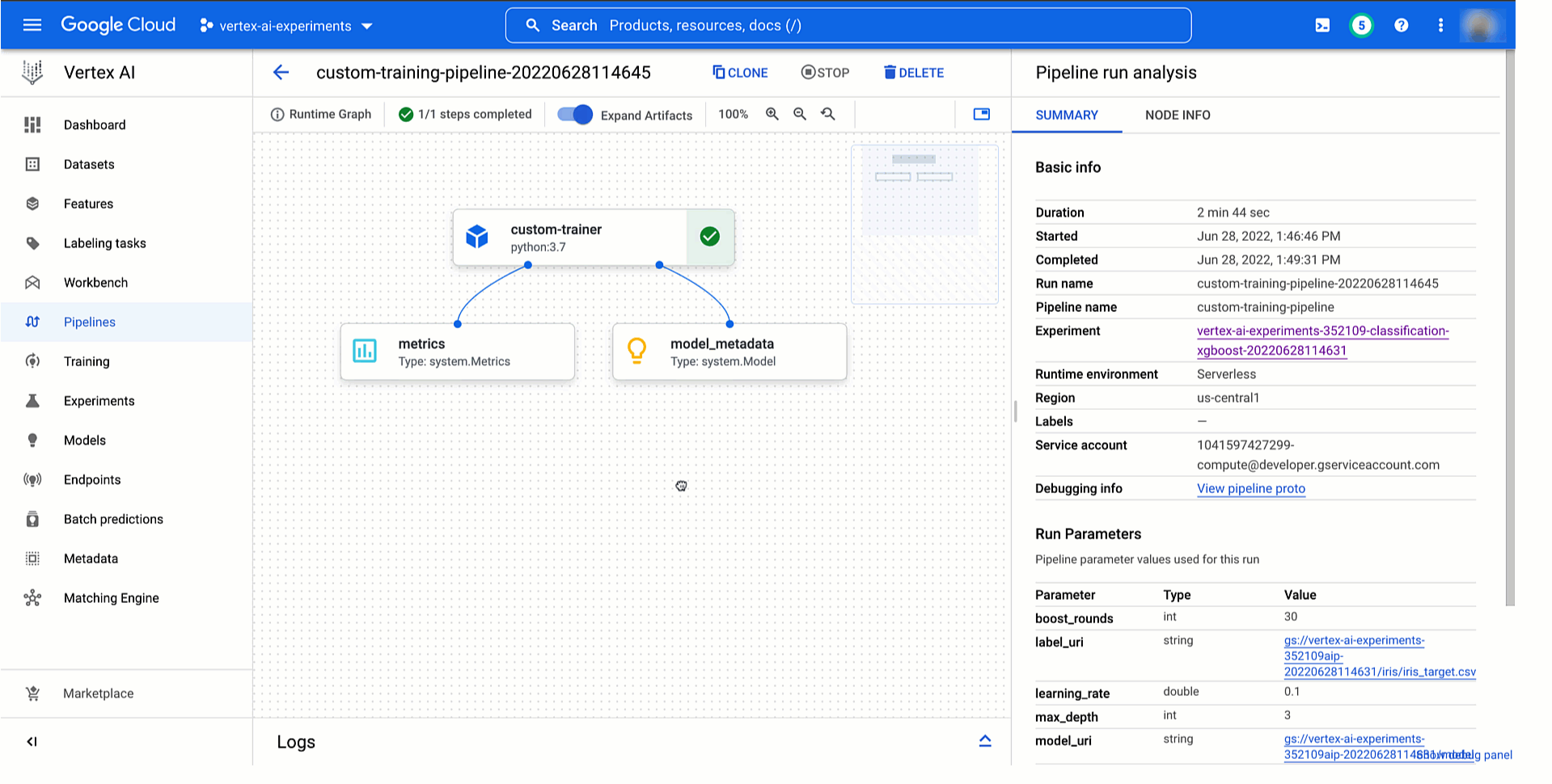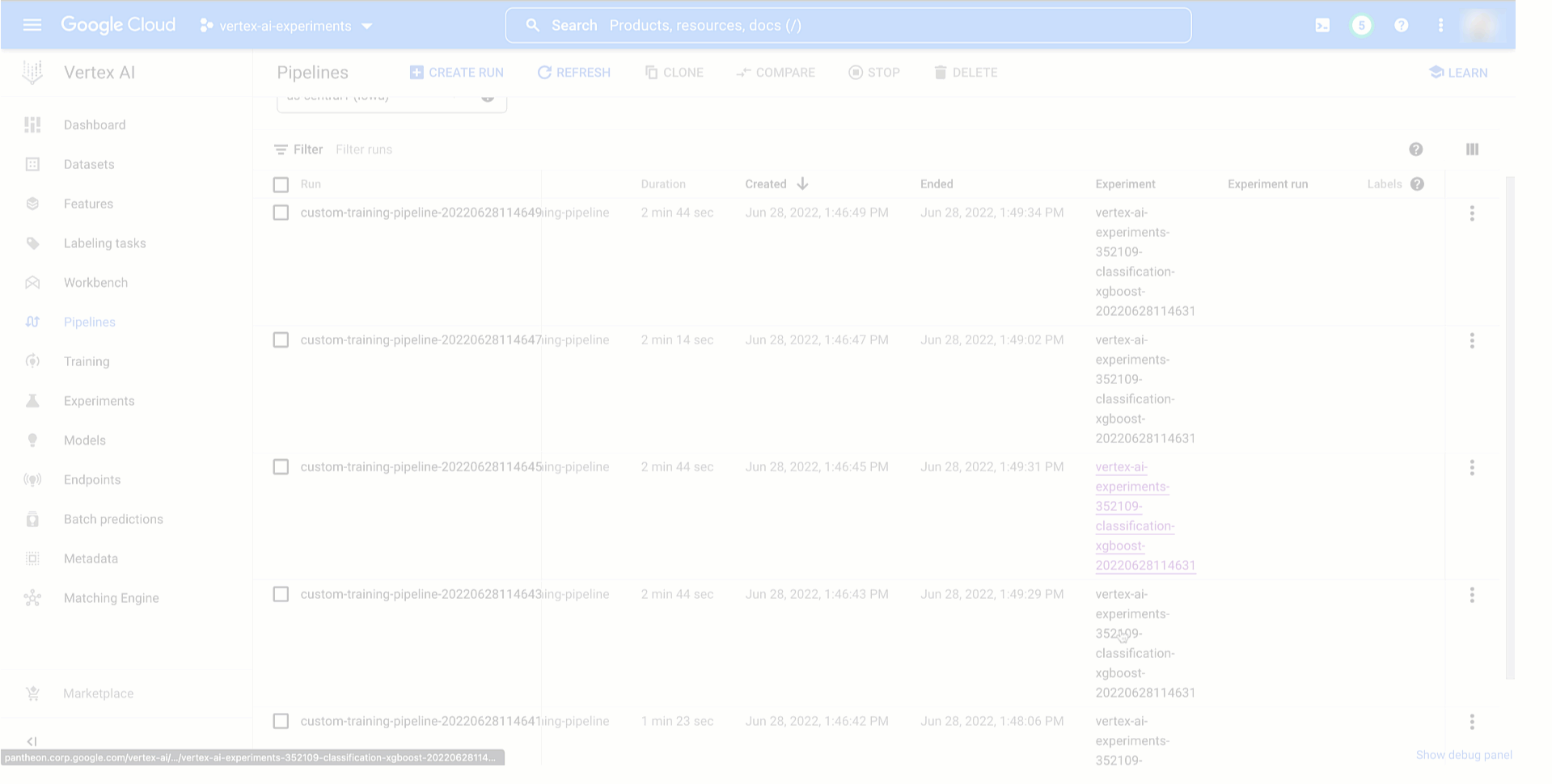
Beneath you’ll be able to see learn how to entry information and mannequin artifacts of an experiment run from the Vertex AI Experiments view and the way the ensuing experiment lineage would appear like within the Vertex ML Metadata.
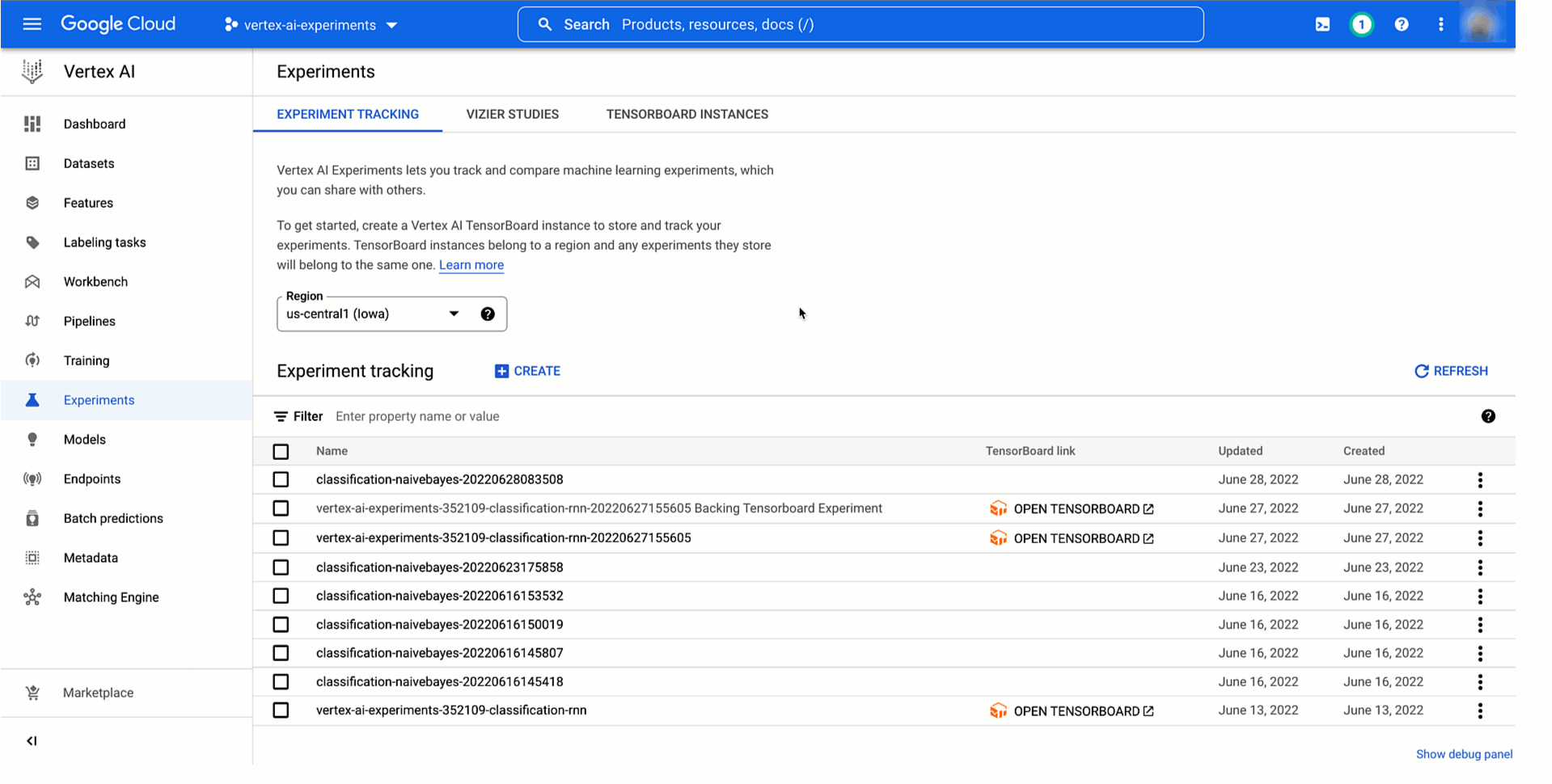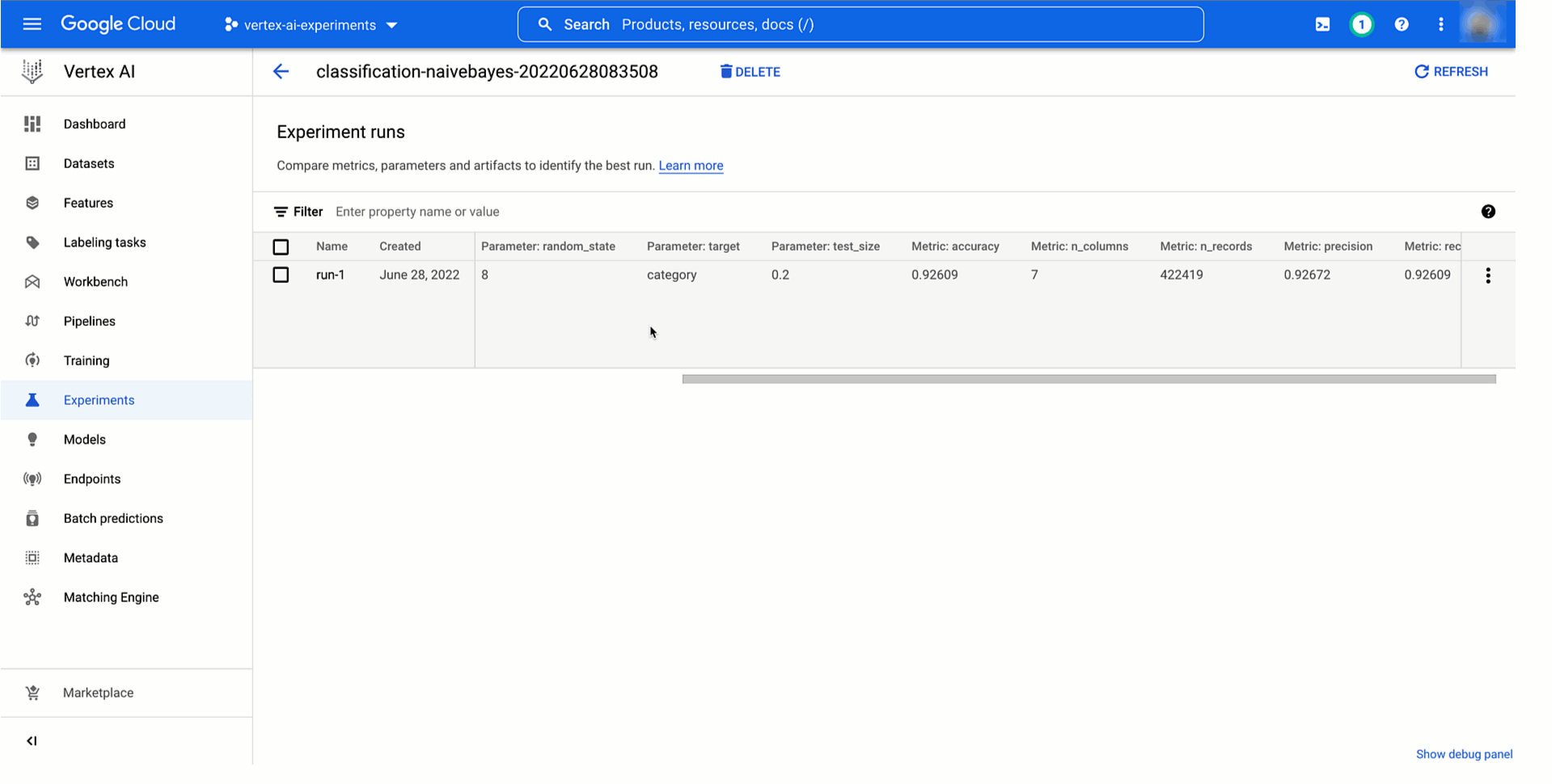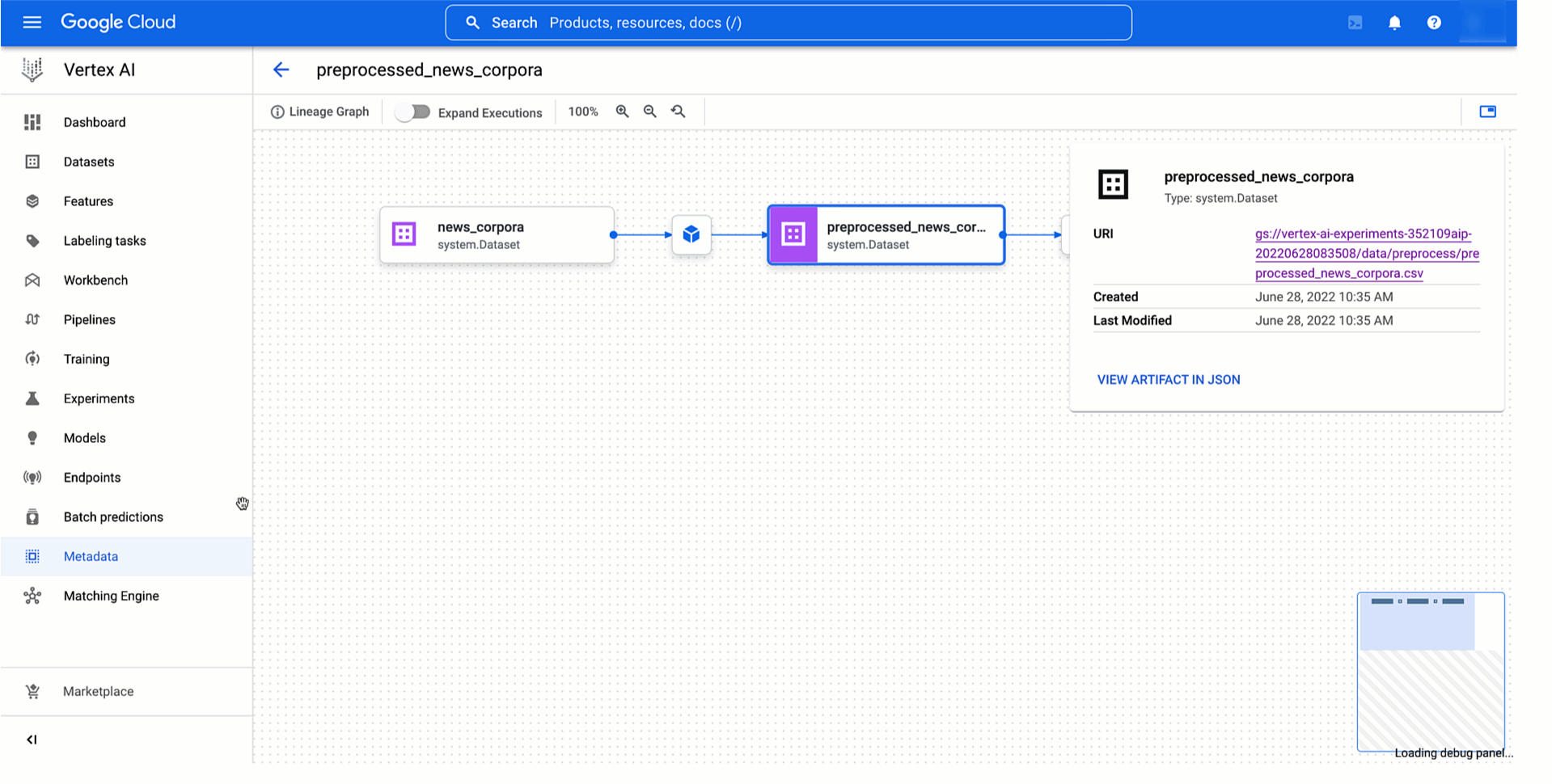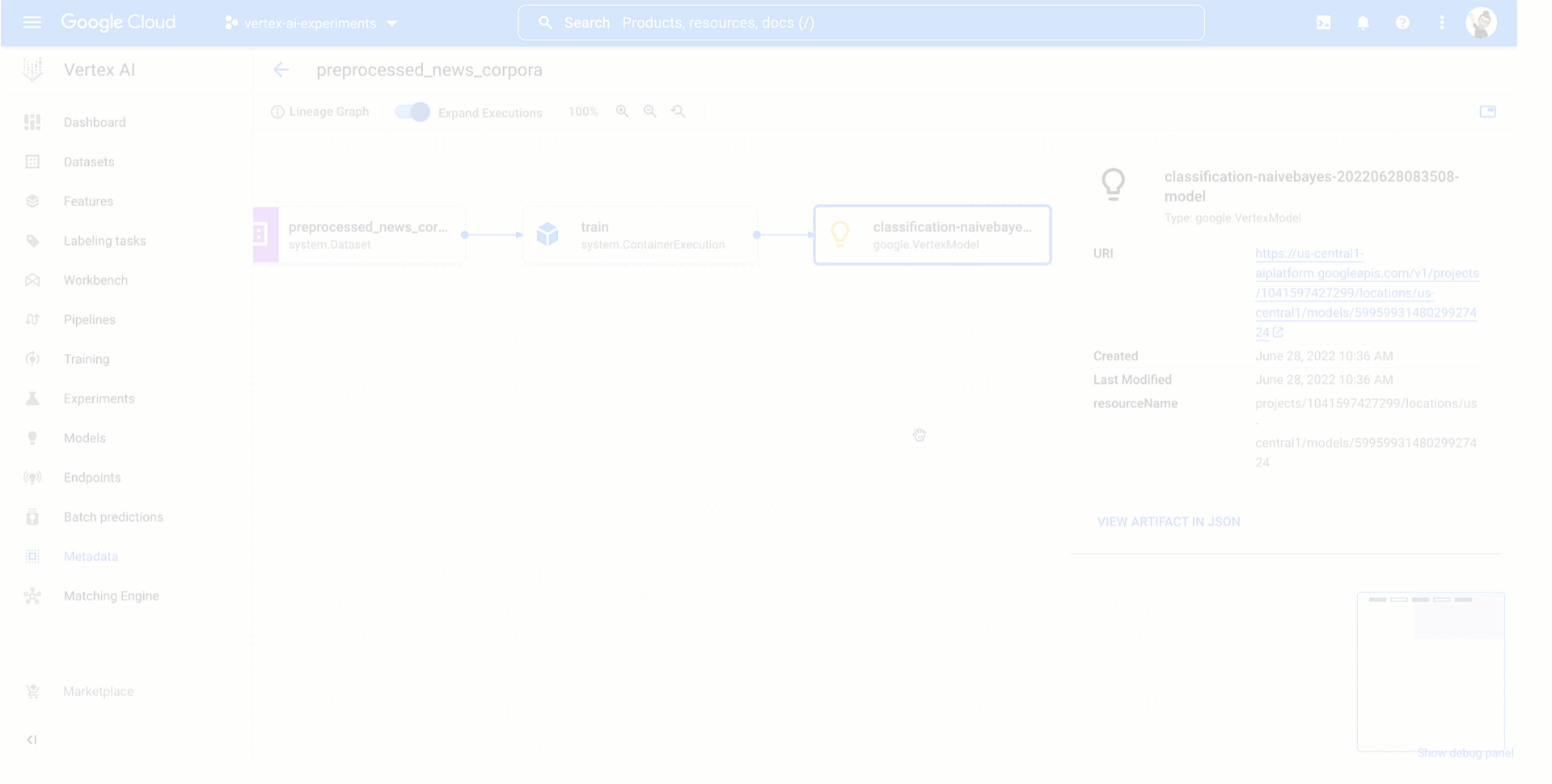
|
Determine four. Monitoring mannequin coaching experiment lineage |
Evaluating mannequin coaching pipeline runs
Automating experimentation of a pipeline run is crucial when you could retrain your fashions steadily. The earlier you formalize your experiments in pipelines, the better and sooner will probably be to maneuver them to manufacturing. The diagram depicts a excessive stage view of a fast experimentation course of.

As a knowledge scientist, you formalize your experiment in a pipeline which can absorb quite a few parameters to coach your mannequin. After you have your pipeline, you want a strategy to monitor and consider pipeline runs at scale to find out which parameters configuration generates the very best performing mannequin.
By leveraging the mixing with Vertex AI Pipelines, Vertex AI Experiments allows you to to trace pipeline parameters, artifacts and metrics and examine pipeline runs.
All you could do is declare the experiment title earlier than submitting the pipeline job on Vertex AI.
- code_block
- [StructValue([(u’code’, u’# Define run specificationsrnruns = [rn “max_depth”: 4, “learning_rate”: 0.2, “boost_rounds”: 10,rn ,rn ,rn]rnrn# Submit a number of pipelines and monitor them as experiment runsrnfor i, parameter_values in enumerate(runs):rnrn job = vertex_ai.PipelineJob(rn display_name=f”my-pipeline-experiment-run-i”,rn template_path=”pipeline.json”,rn pipeline_root=”gs://vertex-ai-experiments-demo/pipelines/pipeline.json”,rn parameter_values=parameter_values,rn )rn rn job.submit(experiment=”my-experiment”)’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e8538143290>)])]
Then, as demonstrated under, it is possible for you to to see your pipeline experiment run and its parameters and metrics in Vertex AI Experiments and examine it with earlier runs to then promote the very best coaching configuration to manufacturing. You can too see the connection along with your experiment run and monitor your pipeline run in Vertex AI Pipelines. And since every run is mapped to a useful resource in Vertex ML Metadata, it is possible for you to to clarify your option to others by exhibiting the lineage robotically created on Vertex AI.
|
Determine 5. Monitor and evaluating mannequin coaching pipeline experiment runs |
Conclusion
With Vertex AI Experiments it is possible for you to not solely to trace parameters, visualize and examine efficiency metrics of your fashions, it is possible for you to to construct managed experiments which are able to go to manufacturing rapidly due to the ML pipeline and the metadata lineage integration capabilities of Vertex AI.
Now it is your flip. Whereas I am fascinated with the subsequent weblog publish, try notebooks within the official Github repo and the assets under to begin getting your fingers soiled. And keep in mind…At all times have enjoyable!
Wish to be taught extra?
Documentation
-
Study extra about Vertex AI Workbench
-
Study extra about Vertex AI Experiments
-
Study extra about Vertex AI Tensorboard
-
Study extra about Vertex ML Metadata
-
Study extra about Vertex AI Pipelines
Samples
-
Google Cloud Vertex AI Samples
[ad_2]
Source link




