
[ad_1]
Beforehand within the PyTorch on Google Cloud collection, we educated, tuned and deployed a PyTorch textual content classification mannequin utilizing Coaching and Prediction companies on Vertex AI. On this publish, we’ll present the way to automate and monitor a PyTorch based mostly ML workflow by orchestrating the pipeline in a serverless method utilizing Vertex AI Pipelines. Let’s get began!
Why Pipelines?
Earlier than we dive in, first, let’s perceive why pipelines are wanted for ML workflows? As seen beforehand, coaching and deploying a PyTorch based mostly mannequin encapsulates a sequence of duties corresponding to processing information, coaching a mannequin, hyperparameter tuning, analysis, packaging the mannequin artifacts, mannequin deployment and retraining cycle. Every of those steps have completely different dependencies and if your entire workflow is handled as a monolith, it will possibly rapidly turn into unwieldy.

Because the ML methods and processes start to scale, you would possibly wish to share your ML workflow with others in your crew to execute the workflows or contribute to the code. And not using a dependable, reproducible course of, this may turn into troublesome. With pipelines, every step within the ML course of runs in its personal container. This allows you to develop steps independently and monitor the enter and output from every step in a reproducible manner permitting to iterate experiments successfully. Automating these duties and orchestrating them throughout a number of companies permits repeatable and reproducible ML workflows that may be shared between completely different groups corresponding to information scientists, information engineers.
Pipelines are additionally a key element to MLOps when formalizing coaching and deployment operationalization to mechanically retrain, deploy and monitor fashions. For instance, triggering a pipeline run when new coaching information is accessible, retraining a mannequin when efficiency of the mannequin begins decaying and extra such situations.
Orchestrating PyTorch based mostly ML workflows with Vertex AI Pipelines
PyTorch based mostly ML workflows might be orchestrated on Vertex AI Pipelines, which is a completely managed and serverless solution to automate, monitor, and orchestrate a ML workflow on Vertex AI platform. Vertex AI Pipelines is the best solution to orchestrate, automate and share ML workflows on Google Cloud for the next causes:
-
Reproducible and shareable workflows: A Vertex AI pipeline might be outlined with Kubeflow Pipelines (KFP) v2 SDK, a simple to make use of open supply Python based mostly library. The compiled pipelines might be model managed with the git device of selection and shared among the many groups. This enables reproducibility and reliability of ML workflows whereas automating the pipeline. Pipelines will also be authored with Tensorflow Prolonged (TFX) SDK.
-
Streamline operationalizing ML fashions: Vertex AI Pipelines mechanically logs metadata utilizing Vertex ML Metadata service to trace artifacts, lineage, metrics, visualizations and pipeline executions throughout ML workflows. This permits information scientists to trace experiments as they fight new fashions or new options. By storing the reference to the artifacts in Vertex ML Metadata, the lineage of ML artifacts might be analyzed — corresponding to datasets and fashions, to know how an artifact was created and consumed by downstream duties, what parameters and hyperparameters had been used to create the mannequin.
-
Serveless, scalable and value efficient: Vertex AI Pipelines is solely serverless permitting ML engineers to concentrate on ML options fairly than on infrastructure duties (provisioning, sustaining, deploying cluster and many others). When a pipeline is uploaded and submitted, the service handles provisioning and scaling of the infrastructure required to run the pipeline. This implies pay just for the assets used for working the pipeline.
Integration with different Google cloud companies: A pipeline step might import information from BigQuery or Cloud Storage or different sources, remodel datasets utilizing Cloud Dataflow or Dataproc, prepare fashions with Vertex AI, retailer pipeline artifacts in Cloud Storage, get mannequin analysis metrics, and deploy fashions to Vertex AI endpoints. Utilizing the pre-built pipeline elements for Vertex AI Pipelines makes it simple to name these steps in a pipeline.
NOTE: You can even orchestrate PyTorch based mostly ML workflows on Google Cloud utilizing open supply Kubeflow Pipelines (KFP) which is a core element within the OSS Kubeflow mission for constructing and deploying transportable, scalable ML workflows based mostly on Docker containers. The OSS KFP backend runs on a Kubernetes cluster corresponding to Google Kubernetes Engine (GKE). The OSS KFP contains the pre-built PyTorch KFP elements SDK for various ML duties corresponding to information loading, mannequin coaching, mannequin profiling and lots of extra. Confer with this weblog publish for exploring additional on orchestrating PyTorch based mostly ML workflow on OSS KFP.
On this publish, we’ll outline a pipeline utilizing KFP SDK v2 to automate and orchestrate the mannequin coaching, tuning and deployment workflow of the PyTorch textual content classification mannequin lined beforehand. With KFP SDK v2, element and pipeline authoring is simplified and has top quality assist for metadata logging and monitoring making it simpler to trace metadata and artifacts produced by the pipelines.
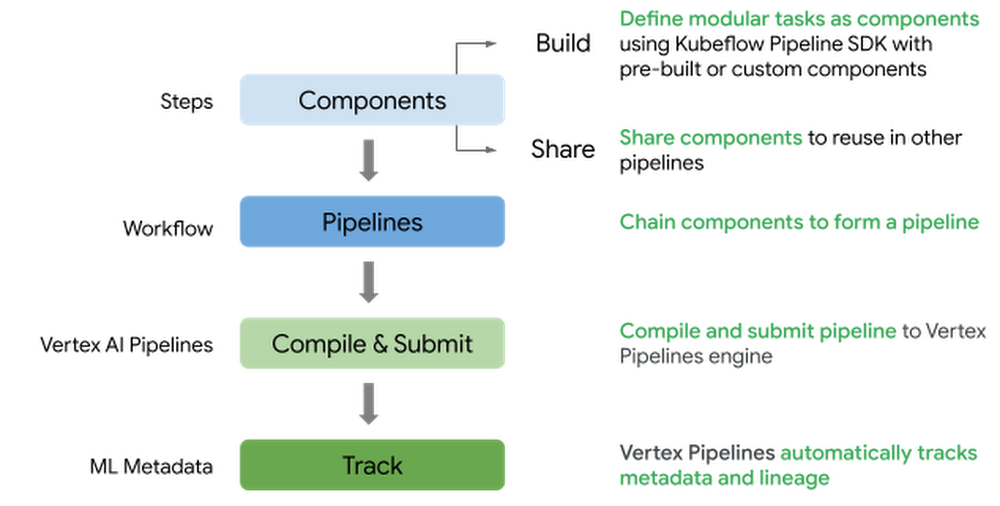
Following is the excessive stage circulation to outline and submit a pipeline on Vertex AI Pipelines:
-
Outline pipeline elements concerned in coaching and deploying a PyTorch mannequin
-
Outline a pipeline by stitching the elements within the workflow together with pre-built Google Cloud elements and customized elements
-
Compile and submit the pipeline to Vertex AI Pipelines service to run the workflow
-
Monitor the pipeline and analyze the metrics and artifacts generated
This publish builds on the coaching and serving code from the earlier posts. You will discover the accompanying code and pocket book for this weblog publish on the GitHub repository.
Ideas of a Pipeline
Let us take a look at the terminology and ideas utilized in KFP SDK v2. In case you are acquainted with KFP SDK, skip to the subsequent part – “Defining the Pipeline for PyTorch based mostly ML workflow”.
-
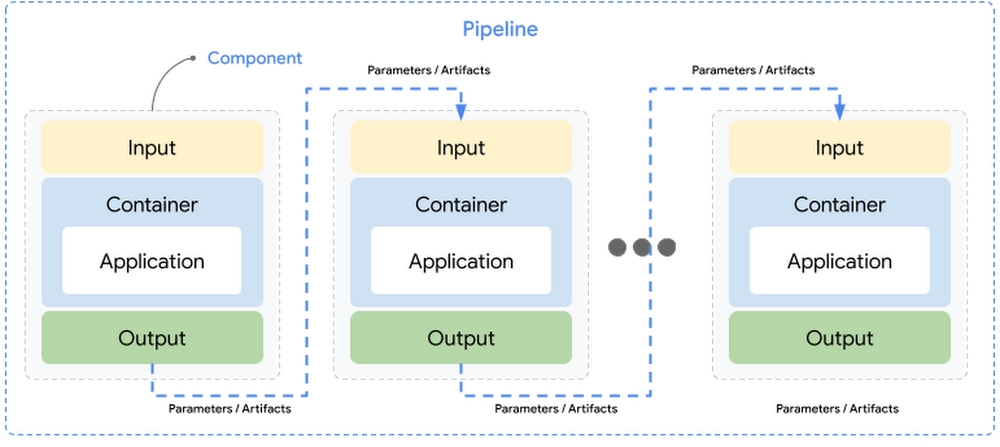
Element: A element is a self-contained set of code performing a single activity in a ML workflow, for instance, coaching a mannequin. A element interface consists of inputs, outputs and a container picture that the element’s code runs in – together with an executable code and surroundings definition.
-
Pipeline: A pipeline consists of modular duties outlined as elements which might be chained collectively by way of inputs and outputs. Pipeline definition contains configuration corresponding to parameters required to run the pipeline. Every element in a pipeline executes independently and the information (inputs and outputs) is handed between the elements in a serialized format.
-
Inputs & Outputs: Element’s inputs and outputs should be annotated with information kind, which makes enter or output a parameter or an artifact.
-
Parameters: Parameters are inputs or outputs to assist easy information varieties corresponding to
str,int,float,bool,dict,record. Enter parameters are at all times handed by worth between the elements and are saved within the Vertex ML Metadata service. -
Artifacts: Artifacts are references to the objects or information produced by pipeline runs which might be handed as inputs or outputs. Artifacts assist wealthy or bigger information varieties corresponding to datasets, fashions, metrics, visualizations which might be written as information or objects. Artifacts are outlined by identify, uri and metadata which is saved mechanically within the Vertex ML Metadata service and the precise content material of artifacts refers to a path within the Cloud Storage bucket. Enter artifacts are at all times handed by reference.
Study extra about KFP SDK v2 ideas right here.
Defining the Pipeline for PyTorch based mostly ML workflow
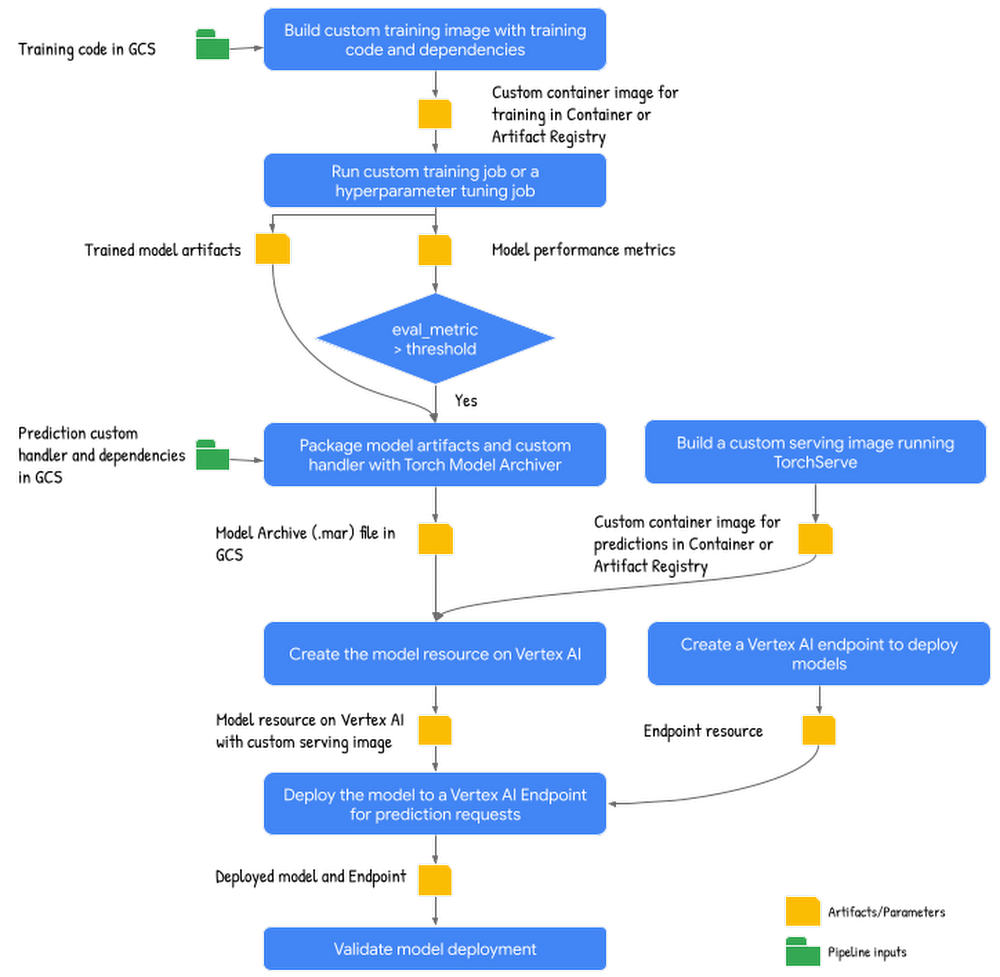
Now that pipeline ideas are acquainted, let us take a look at constructing a pipeline for the PyTorch based mostly textual content classification mannequin. The next pipeline schematic reveals excessive stage steps concerned together with enter and outputs:
Following are the steps within the pipeline:
-
Construct customized coaching picture: This step builds a customized coaching container picture from the coaching utility code and related Dockerfile with the dependencies. The output from this step is the Container or Artifact registry URI of the customized coaching container.
-
Run the customized coaching job to coach and consider the mannequin: This step downloads and preprocesses coaching information from IMDB sentiment classification dataset on HuggingFace, then trains and evaluates a mannequin on the customized coaching container from the earlier step. The step outputs Cloud Storage path to the educated mannequin artifacts and the mannequin efficiency metrics.
-
Bundle mannequin artifacts: This step packages educated mannequin artifacts together with customized prediction handler to create a mannequin archive (.mar) file utilizing Torch Mannequin Archiver device. The output from this step is the situation of the mannequin archive (.mar) file on GCS.
-
Construct customized serving picture: The step builds a customized serving container working TorchServe HTTP server to serve prediction requests for the fashions mounted. The output from this step is the Container or Artifact registry URI to the customized serving container.
-
Add mannequin with customized serving container: This step creates a mannequin useful resource utilizing the customized serving picture and mannequin archive file (.mar) from the earlier step.
-
Create an endpoint: This step creates a Vertex AI Endpoint to supply a service URL the place the prediction requests are despatched.
-
Deploy mannequin to endpoint for serving: This step deploys the mannequin to the endpoint created that creates needed compute assets (based mostly on the machine spec configured) to serve on-line prediction requests.
-
Validate deployment: This step sends take a look at requests to the endpoint and validates the deployment.
There are couple of issues to notice concerning the pipeline right here:
-
The pipeline begins with constructing a coaching container picture, as a result of the textual content classification mannequin we’re engaged on has information preparation and pre-processing steps within the coaching code itself. When working with your personal datasets, you possibly can embody information preparation or pre-processing duties as a separate element from the mannequin coaching.
-
Constructing customized coaching and serving containers might be carried out both as a part of the ML pipeline or inside the current CI/CD pipeline (Steady Integration/ Steady Supply). On this publish, we selected to incorporate constructing customized containers as a part of the ML pipeline. In a future publish, we’ll go in depth on CI/CD for ML pipelines and fashions.
Please discuss with the accompanying pocket book for the entire definition of pipeline and element spec.
Element specification
With this pipeline schematic, the subsequent step is to outline the person elements to carry out the steps within the pipeline utilizing KFP SDK v2 element spec. We use a mixture of pre-built elements from Google Cloud Pipeline Parts SDK and customized elements within the pipeline.
Let’s look into the element spec for one of many steps – constructing the customized coaching container picture. Right here we’re defining a Python function-based element the place the element code is outlined as a standalone python perform. The perform accepts Cloud Storage path to the coaching utility code together with mission and mannequin show identify as enter parameters and outputs the Container Registry (GCR) URI to the customized coaching container. The perform runs a Cloud Construct job that pulls the coaching utility code and the Dockerfile and builds the customized coaching picture which is pushed to Container Registry (or Artifact Repository). Within the earlier publish, this step was carried out within the pocket book utilizing docker instructions and now this activity is automated by self-containing the step inside a element and together with it in a pipeline.
There are some things to note concerning the element spec:
-
The standalone perform outlined is transformed as a pipeline element utilizing the @kfp.v2.dsl.element decorator.
-
All of the arguments within the standalone perform should have information kind annotations as a result of KFP makes use of the perform’s inputs and outputs to outline the element’s interface.
-
By default Python three.7 is used as the bottom picture to run the code outlined. You may configure the @element decorator to override the default picture by specifying base_image, set up extra python packages utilizing packages_to_install parameter and write the compiled element as a YAML file utilizing output_component_file to share or reuse the element.
The inputs and outputs within the standalone perform above are outlined as Parameters, that are easy information varieties representing values. Inputs and outputs might be Artifacts representing any information or objects generated through the element execution. These arguments are annotated as an kfp.dsl.Enter or kfp.dsl.Output artifact. For instance, the element specification for creating Mannequin Archive file refers back to the mannequin artifacts generated within the coaching job because the enter – Enter[Model] within the following snippet:
Refer right here for the artifact varieties in KFP v2 SDK and right here for the artifact varieties for Google Cloud Pipeline Parts.
For element specs of different steps within the pipeline, discuss with the accompanying pocket book.
Pipeline definition
After defining the elements, the subsequent step is to construct the pipeline definition describing how enter and output parameters and artifacts are handed between the steps. The next code snippet reveals the elements chained collectively:
Let’s unpack this code and perceive a couple of issues:
-
The pipeline is outlined as a standalone Python perform annotated with the @kfp.dsl.pipeline decorator, specifying the pipeline’s identify and the basis path the place the pipeline’s artifacts are saved.
-
The pipeline definition consists of each pre-built and customized outlined elements
-
Pre-built elements from Google Cloud Pipeline Parts SDK are outlined for steps calling Vertex AI companies corresponding to submitting customized coaching job (custom_job.CustomTrainingJobOp), importing a mannequin (ModelUploadOp), creating an endpoint (EndpointCreateOp) and deploying a mannequin to the endpoint (ModelDeployOp)
-
Customized elements are outlined for steps to construct customized containers for coaching (build_custom_train_image), get coaching job particulars (get_training_job_details), create mar file (generate_mar_file) and serving (build_custom_serving_image) and validating the mannequin deployment activity (make_prediction_request). Confer with the pocket book for customized element specification for these steps.
-
A element’s inputs might be set from the pipeline’s inputs (handed as arguments) or they’ll depend upon the output of different elements inside this pipeline. For instance, ModelUploadOp is determined by customized serving container picture URI from build_custom_serving_image activity together with the pipeline’s inputs corresponding to mission id, serving container routes and ports.
-
kfp.dsl.Situation is a management construction with a gaggle of steps which runs solely when the situation is met. On this pipeline, mannequin deployment steps run solely when the educated mannequin efficiency exceeds the set threshold. If not, these steps are skipped.
-
Every element within the pipeline runs inside its personal container picture. You may specify machine kind for every pipeline step corresponding to CPU, GPU and reminiscence limits. By default, every element runs as a Vertex AI CustomJob utilizing an e2-standard-Four machine.
-
By default, pipeline execution caching is enabled. Vertex AI Pipelines service checks to see whether or not an execution of every pipeline step exists in Vertex ML metadata. It makes use of a mix of pipeline identify, step’s inputs, output and element specification. When an identical execution already exists, the step is skipped and thereby decreasing prices. Execution caching might be turned off at activity stage or at pipeline stage.
To study extra about constructing pipelines, discuss with the constructing Kubeflow pipelines part, and observe the samples and tutorials.
Compiling and submitting the Pipeline
Pipeline should be compiled for executing on Vertex AI Pipeline companies. When a pipeline is compiled, the KFP SDK analyzes the information dependencies between the elements to create a directed acyclic graph. The compiled pipeline is in JSON format with all data required to run the pipeline.
Pipeline is submitted to Vertex AI Pipelines by defining a PipelineJob utilizing Vertex AI SDK for Python shopper, passing needed pipeline inputs.
When the pipeline is submitted, the logs present a hyperlink to view the pipeline run on Google Cloud Console or entry the run by opening Pipelines dashboard on Vertex AI.

Right here is the runtime graph of the pipeline for the PyTorch textual content classification mannequin:
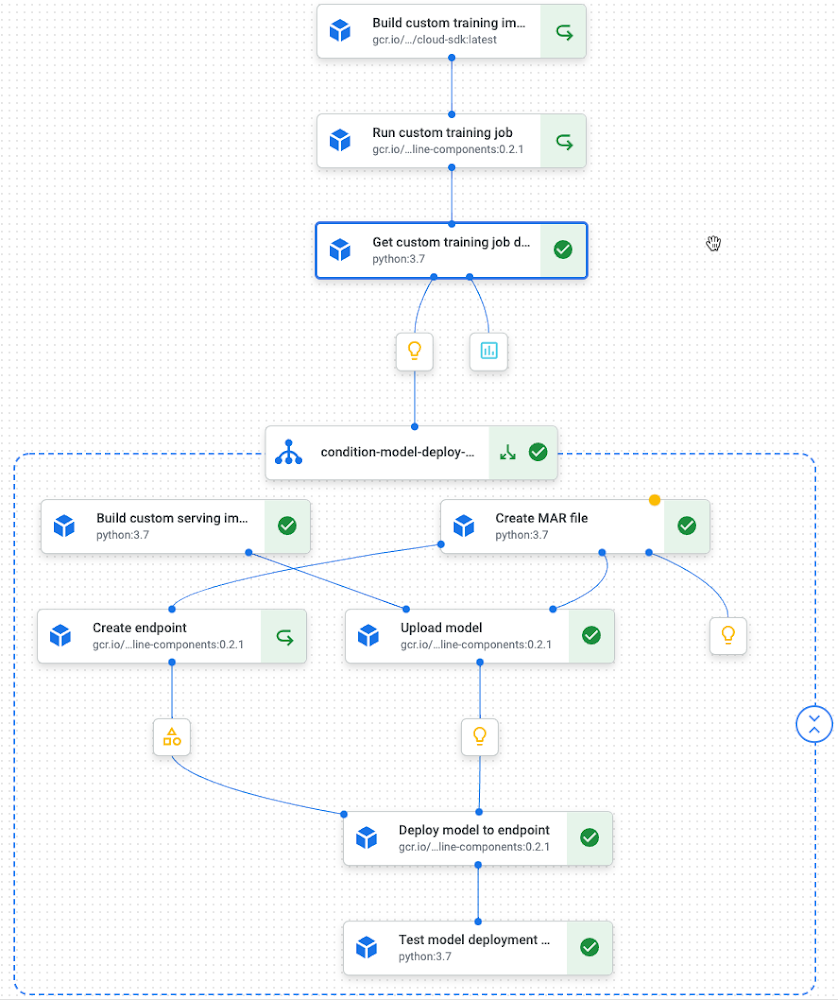
Pipeline runtime graph
A pipeline execution might be scheduledto run at a selected frequency utilizing Cloud Scheduler ortriggeredbased on an occasion.
You may view the compiled JSON from the Pipeline Run abstract tab on the Vertex AI Pipelines dashboard, which might be helpful for debugging.
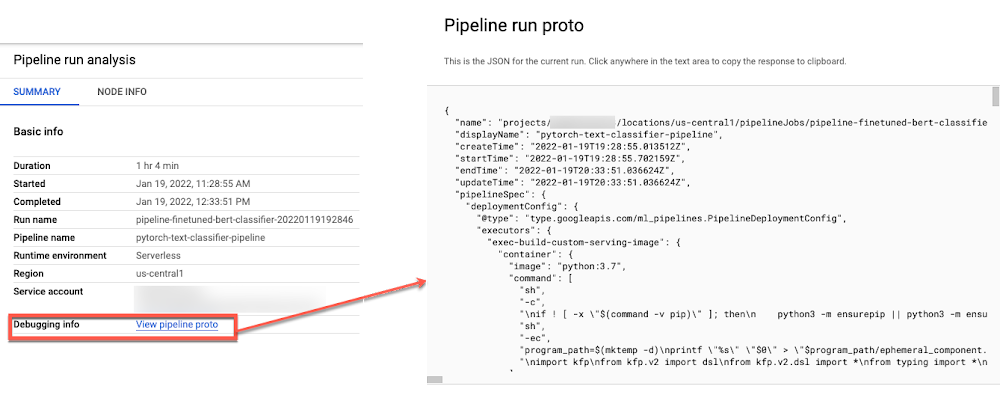
Monitoring the Pipeline
The pipeline run web page reveals the run abstract as properly particulars about particular person steps together with step inputs and outputs generated corresponding to Mannequin, Artifacts, Metrics, Visualizations.
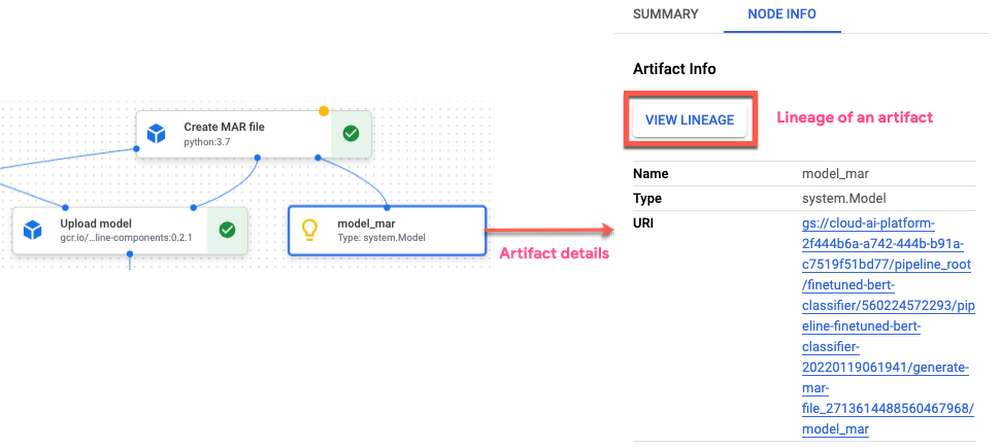
Vertex AI Pipelines mechanically tracks pipeline execution data in Vertex ML Metadata together with metadata and artifacts thereby enabling comparability throughout pipeline runs and the lineage of ML artifacts.

You may evaluate throughout pipeline runs corresponding to inputs, parameters, metrics and visualizations from the Vertex AI Pipelines dashboard. You can even use aiplatform.get_pipeline_df() technique from the Vertex AI SDK to fetch pipeline execution metadata for a pipeline as a Pandas dataframe.

Cleansing up assets
After you’re carried out experimenting, you possibly can both cease or delete the Notebooks occasion. If you wish to save your work, you possibly can select to cease the occasion. Once you cease an occasion, you’re charged just for the persistent disk storage.
To wash up all Google Cloud assets created on this publish, you possibly can delete the person assets created:
-
Coaching Jobs
-
Mannequin
-
Endpoint
-
Cloud Storage Bucket
-
Container Photographs
-
Pipeline runs
Observe the Cleansing Up part within the Jupyter Pocket book to delete the person assets.
What’s subsequent?
This publish continues from the coaching and deploying of the PyTorch based mostly textual content classification mannequin on Vertex AI and reveals the way to automate a PyTorch based mostly ML workflow usingVertex AI Pipelines and Kubeflow Pipelines v2 SDK. As the subsequent steps, you possibly can work by means of this pipeline instance on Vertex AI or maybe orchestrate considered one of your personal PyTorch fashions.
References
-
Introduction to Vertex AI Pipelines
-
Samples and tutorials to study extra about Vertex AI Pipelines
-
Kubeflow Pipelines SDK (v2)
-
Prepare and tune PyTorch fashions on Vertex AI
-
Deploy PyTorch fashions on Vertex AI
-
GitHub repository with code and accompanying pocket book
Keep tuned. Thanks for studying! Have a query or wish to chat? Discover Rajesh on Twitter or LinkedIn.
Because of Vaibhav Singh, Karl Weinmeister and Jordan Totten for serving to and reviewing the publish.
[ad_2]
Source link




