
[ad_1]
Data Know-how groups, particularly in assist desk and assist, want a method to monitor what issues individuals are having. Ideally additionally they can know the way these issues change over time, particularly when know-how or coverage shifts.
Think about you might be in command of sending a newspaper supply group to completely different neighborhoods. Every particular person has a bicycle, so that you give them a route, and so they depart the papers on the proper doorways. However the roads change. Day by day they alter. It is chaos.
What do you do when routes are altering continuously? How do you present the knowledge wanted when the context is shifting on a regular basis?
In an IT context we run into related challenges with conventional downside administration frameworks akin to ITIL four, which are inclined to at all times assume a hard and fast, well-defined catalog of companies. That approach each situation that the IT of us remedy is tracked and accounted for. That connection again to the catalog permits perception into what’s inflicting points, or the place outages or incidents could also be impacting a big group of workers.
At Google we do not have that. Partly as a result of we deal with placing the person first, and so we deal with getting individuals again to a productive state as job #1. Additionally as a result of merchandise, companies and points are at all times shifting–similar to the roads, the route isn’t the identical, even when the objective stays constant. Meaning customers come into our IT service desk with new downside sorts on a regular basis.
Our tech assist group, known as Techstop, acts because the one-stop store for all IT points, and helps individuals throughout chat, e mail and video channels. They should stay adaptable to new issues Googlers expertise and new merchandise they use. So as to monitor what issues could be on the rise, the Techstop group wants a method to catalog what instruments, purposes and companies are in use at Google.
Considering again to the newspaper supply routes, we used a tough approximate map, reasonably than a really detailed one, giving us a taxonomy of companies that was “ok” for many of our use circumstances. We bought some helpful knowledge out of it, but it surely did not give us very granular perception.
Want for innovation
Covid-19 put a brand new deal with scalable downside understanding, particularly for on a regular basis worker IT points. With a lot of the workforce moved to a work-from-home mannequin, we actually wanted to know the place workers had been experiencing know-how ache. It is as if entire new neighborhoods popped into existence in a single day, however our newspaper supply crew was the identical. Extra floor to cowl, with completely novel avenue maps.
Moreover, merchandise used on a regular basis for productiveness, akin to Google Meet, started to see exponential development in utilization, inflicting scaling points and outages. These product groups appeared to the Techstop group to assist them prioritize the ever rising listing of characteristic requests and bugs being crammed day-after-day.
Finally the “ok” downside taxonomy failed to provide actually useful insights. We may discover out which merchandise had been being affected probably the most, however not what points individuals had been having with these merchandise. Even worse, new points that had been distinctive to the work-from-home mannequin had been being hidden by the truth that the catalog couldn’t replace in time to catch the quickly altering downside house beneath it.
Borrowing spam tech
Having a look round different efforts at Google, the Techstop group discovered examples of fixing an analogous downside: detecting new patterns shortly in quickly altering knowledge.
Gmail handles spam filtering for over a billion individuals. These engineers had thought by “how will we detect a brand new spam marketing campaign shortly?” Spammers quickly ship bulk messages with slight variations in content material (noise, misspellings, and many others.) Most classification makes an attempt would turn out to be a recreation of cat and mouse because it takes classifiers a while to find out about new patterns.
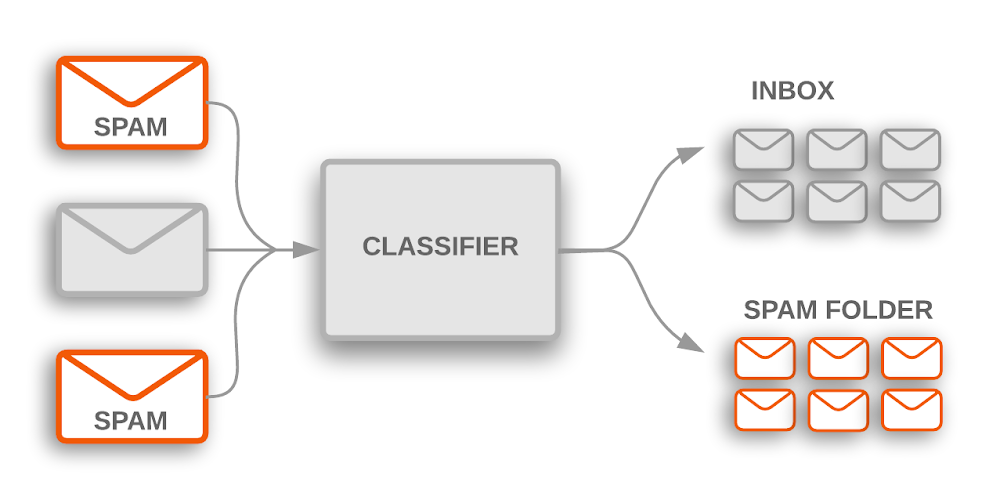
Invoking a development identification engine utilizing unsupervised density clustering on unstructured textual content unlocked the flexibility for Gmail to detect ephemeral spam campaigns extra shortly.
The Techstop downside had an analogous form to it. Points brought on by quickly altering merchandise induced extremely dynamic person journeys for each workers and the IT professionals troubleshooting these points. The tickets filed — just like the spam emails — had been related, with slight variations in spelling and phrase alternative.
Density clustering
In distinction to extra inflexible approaches, akin to centroid-based algorithms like k-means, density-based clustering is healthier suited to massive and extremely heterogeneous knowledge units, which can include clusters of drastically variant measurement. This flexibility helps us deal with the duty of downside identification throughout all the scope of the corporate, which requires the flexibility to detect and distinguish small-but-significant perturbations within the presence of large-but-stable patterns.
Our implementation makes use of ClustOn, an in-house know-how with a hybrid strategy that comes with density-based clustering. However a extra time-tested algorithm akin to DBSCAN — an open-source implementation of which is obtainable through scikit-learn’s clustering module — could possibly be leveraged to related impact.
Center of the highway answer utilizing ML
Piggy-backing off of what Gmail was capable of do utilizing density clustering methods, the Techstop group constructed a sturdy answer to monitoring issues in a approach that solved the inflexible taxonomy downside. With density clustering, the taxonomy buckets are redefined as trending clusters and supply an index of points occurring in real-time throughout the firm. Importantly, these buckets emerge naturally, reasonably than being outlined forward of time by the Engineering or Tech Help groups.
By utilizing the know-how constructed for billions of e mail accounts, we knew we may deal with the size of Google’s assist requests. And the options could be extra versatile than a tightly outlined taxonomy, with out compromising on relevance or granularity.
The group took it one step additional by modeling cluster conduct utilizing Poisson regression and applied anomaly detection measures to alert operations groups in actual time about ongoing outages, or poorly executed adjustments. With a light-weight operations group and this new know-how, Techstop was capable of finding granular insights that may have taken a complete devoted group to manually comb by and combination every incident.
The mixture of ML and Operations reworked Techstop knowledge right into a invaluable reference for product managers and engineering groups trying to perceive the problems customers face with their merchandise in an enterprise surroundings.
The way it works
To convey all of it collectively, we constructed a ML pipeline that we name Help Insights, so we may mechanically distill abstract knowledge from the various interactions and tickets we acquired. The Help Insights Pipeline combines machine studying, human validation and probabilistic evaluation collectively in a single methods dynamics strategy.
As knowledge strikes by this pipeline, they’re:
- Extracted – Makes use of the BigQuery API to retailer and extract, prepare and cargo assist knowledge. To ingest the 1M+ quantity of IT associated assist knowledge.
- Processed Half-of-speech tagging, PII Redaction and TF-IDF transformations to mannequin assist knowledge for our clustering algorithms
- Clustered Centroid-based clustering runs in timed batches with persistent snaphotting of earlier run states to keep up cluster ids and monitor conduct of clusters over time.
- Scored Makes use of Poisson Regression to mannequin each long-term and short-term conduct of cluster tendencies and calculates the distinction between the 2 to measure deviation. This deviation rating is used to detect anomalous conduct inside a development.
- Operationalized Traits with an anomalous rating over a sure threshold set off an IssueTracker API bug. This bug is then picked up by operations groups for related deep dive and incident monitoring.
- Resampled – Makes use of statistical strategies to estimate proportions of buyer person journeys (CUJs) inside tendencies
- Categorized/mapped – We work with the Operations groups to map development proportions to Consumer Journey Segments
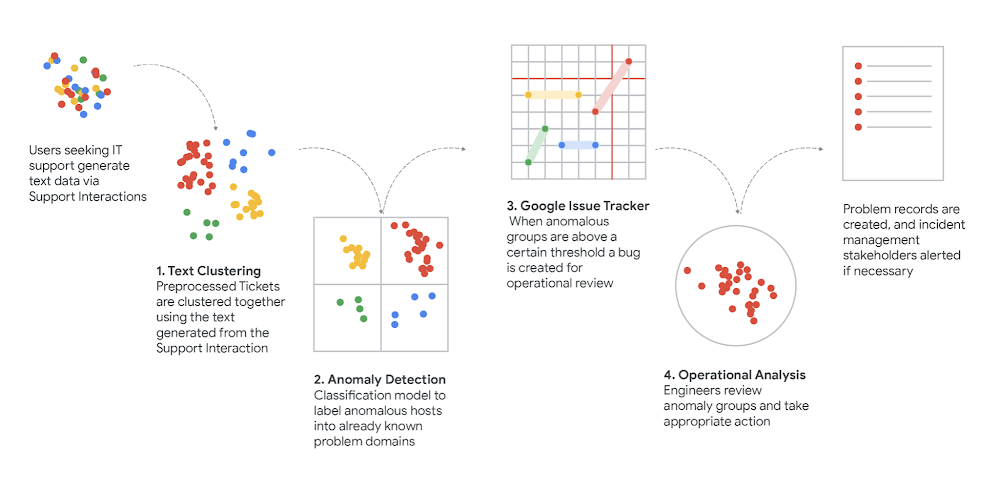
In our subsequent submit we’ll element what applied sciences and strategies we used for these seven steps, and stroll by how you can use an analogous pipeline your self. To get began begin by loading your knowledge into BigQuery and use BigQuery ML to cluster your assist knowledge.
[ad_2]
Source link




