
[ad_1]

|
Final 12 months earlier than re:Invent, we launched the general public preview of AWS Distro for OpenTelemetry, a safe distribution of the OpenTelemetry undertaking supported by AWS. OpenTelemetry gives instruments, APIs, and SDKs to instrument, generate, accumulate, and export telemetry information to higher perceive the conduct and the efficiency of your purposes. Yesterday, upstream OpenTelemetry introduced tracing stability milestone for its parts. Immediately, I’m pleased to share that assist for traces is now typically accessible in AWS Distro for OpenTelemetry.
Utilizing OpenTelemetry, you possibly can instrument your purposes simply as soon as after which ship traces to a number of monitoring options.
You should utilize AWS Distro for OpenTelemetry to instrument your purposes operating on Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (EKS), and AWS Lambda, in addition to on premises. Containers operating on AWS Fargate and orchestrated through both ECS or EKS are additionally supported.
You’ll be able to ship tracing information collected by AWS Distro for OpenTelemetry to AWS X-Ray, in addition to associate locations akin to:
You should utilize auto-instrumentation brokers to gather traces with out altering your code. Auto-instrumentation is offered at this time for Java and Python purposes. Auto-instrumentation assist for Python presently solely covers the AWS SDK. You’ll be able to instrument your purposes utilizing different programming languages (akin to Go, Node.js, and .NET) with the OpenTelemetry SDKs.
Let’s see how this works in follow for a Java software.
Visualizing Traces for a Java Software Utilizing Auto-Instrumentation
I create a easy Java software that exhibits the record of my Amazon Easy Storage Service (Amazon S3) buckets and my Amazon DynamoDB tables:
package deal com.instance.myapp;
import software program.amazon.awssdk.areas.Area;
import software program.amazon.awssdk.companies.s3.S3Client;
import software program.amazon.awssdk.companies.s3.mannequin.*;
import software program.amazon.awssdk.companies.dynamodb.mannequin.DynamoDbException;
import software program.amazon.awssdk.companies.dynamodb.mannequin.ListTablesResponse;
import software program.amazon.awssdk.companies.dynamodb.mannequin.ListTablesRequest;
import software program.amazon.awssdk.companies.dynamodb.DynamoDbClient;
import java.util.Checklist;
/**
* Whats up world!
*
*/
public class App {
public static void listAllTables(DynamoDbClient ddb) {
System.out.println("DynamoDB Tables:");
boolean moreTables = true;
String lastName = null;
whereas (moreTables)
attempt catch (DynamoDbException e)
System.err.println(e.getMessage());
System.exit(1);
System.out.println("Finished!n");
}
public static void listAllBuckets(S3Client s3)
public static void listAllBucketsAndTables(S3Client s3, DynamoDbClient ddb)
public static void principal(String[] args)
Area area = Area.EU_WEST_1;
S3Client s3 = S3Client.builder().area(area).construct();
DynamoDbClient ddb = DynamoDbClient.builder().area(area).construct();
listAllBucketsAndTables(s3, ddb);
s3.shut();
ddb.shut();
}I package deal the appliance utilizing Apache Maven. Right here’s the Mission Object Mannequin (POM) file managing dependencies such because the AWS SDK for Java 2.x that I take advantage of to work together with S3 and DynamoDB:
<undertaking xmlns="http://maven.apache.org/POM/four.Zero.Zero" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/four.Zero.Zero http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>four.Zero.Zero</modelVersion>
<properties>
<undertaking.construct.sourceEncoding>UTF-Eight</undertaking.construct.sourceEncoding>
</properties>
<groupId>com.instance.myapp</groupId>
<artifactId>myapp</artifactId>
<packaging>jar</packaging>
<model>1.Zero-SNAPSHOT</model>
<identify>myapp</identify>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>software program.amazon.awssdk</groupId>
<artifactId>bom</artifactId>
<model>2.17.38</model>
<kind>pom</kind>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<model>three.Eight.1</model>
<scope>check</scope>
</dependency>
<dependency>
<groupId>software program.amazon.awssdk</groupId>
<artifactId>s3</artifactId>
</dependency>
<dependency>
<groupId>software program.amazon.awssdk</groupId>
<artifactId>dynamodb</artifactId>
</dependency>
</dependencies>
<construct>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<model>three.Eight.1</model>
<configuration>
<supply>Eight</supply>
<goal>Eight</goal>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.instance.myapp.App</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</construct>
</undertaking>I take advantage of Maven to create an executable Java Archive (JAR) file that features all dependencies:
To run the appliance and get tracing information, I would like two parts:
In a single terminal, I run the AWS Distro for OpenTelemetry Collector utilizing Docker:
The collector is now able to obtain traces and ahead them to a monitoring platform. By default, the AWS Distro for OpenTelemetry Collector sends traces to AWS X-Ray. I can change the exporter or add extra exporters by modifying the collector configuration. For instance, I can observe the documentation to configure OLTP exporters to ship telemetry information utilizing the OLTP protocol. Within the documentation, I additionally discover learn how to configure different associate locations.
I obtain the newest model of the AWS Distro for OpenTelemetry Auto-Instrumentation Java Agent. Now, I run my software and use the agent to seize telemetry information with out having so as to add any particular instrumentation the code. Within the OTEL_RESOURCE_ATTRIBUTES setting variable I set a reputation and a namespace for the service:
As anticipated, I get the record of my S3 buckets globally and of the DynamoDB tables within the Area.
To generate extra tracing information, I run the earlier command a couple of instances. Every time I run the appliance, telemetry information is collected by the agent and despatched to the collector. The collector buffers the info after which sends it to the configured exporters. By default, it’s sending traces to X-Ray.
Now, I take a look at the service map within the AWS X-Ray console to see my software’s interactions with different companies:

And there they’re! With none change within the code, I see my software’s calls to the S3 and DynamoDB APIs. There have been no errors, and all of the circles are inexperienced. Contained in the circles, I discover the typical latency of the invocations and the variety of transactions per minute.
Including Spans to a Java Software
The knowledge mechanically collected will be improved by offering extra data with the traces. For instance, I may need interactions with the identical service in several components of my software, and it will be helpful to separate these interactions within the service map. On this method, if there’s an error or excessive latency, I might know which a part of my software is affected.
A technique to take action is to make use of spans or segments. A span represents a gaggle of logically associated actions. For instance, the listAllBucketsAndTables technique is performing two operations, one with S3 and one with DynamoDB. I’d wish to group them collectively in a span. The quickest method with OpenTelemetry is so as to add the @WithSpan annotation to the tactic. As a result of the results of a technique normally is determined by its arguments, I additionally use the @SpanAttribute annotation to explain which arguments within the technique invocation must be mechanically added as attributes to the span.
@WithSpan
public static void listAllBucketsAndTables(@SpanAttribute("title") String title, S3Client s3, DynamoDbClient ddb)
System.out.println(title);
listAllBuckets(s3);
listAllTables(ddb);
To have the ability to use the @WithSpan and @SpanAttribute annotations, I have to import them into the code and add the required OpenTelemetry dependencies to the POM. All these adjustments are primarily based on the OpenTelemetry specs and don’t rely on the precise implementation that I’m utilizing, or on the device that I’ll use to visualise or analyze the telemetry information. I’ve solely to make these adjustments as soon as to instrument my software. Isn’t that nice?
To higher see how spans work, I create one other technique that’s operating the identical operations in reverse order, first itemizing the DynamoDB tables, then the S3 buckets:
@WithSpan
public static void listTablesFirstAndThenBuckets(@SpanAttribute("title") String title, S3Client s3, DynamoDbClient ddb)
System.out.println(title);
listAllTables(ddb);
listAllBuckets(s3);
The applying is now operating the 2 strategies (listAllBucketsAndTables and listTablesFirstAndThenBuckets) one after the opposite. For simplicity, right here’s the complete code of the instrumented software:
package deal com.instance.myapp;
import software program.amazon.awssdk.areas.Area;
import software program.amazon.awssdk.companies.s3.S3Client;
import software program.amazon.awssdk.companies.s3.mannequin.*;
import software program.amazon.awssdk.companies.dynamodb.mannequin.DynamoDbException;
import software program.amazon.awssdk.companies.dynamodb.mannequin.ListTablesResponse;
import software program.amazon.awssdk.companies.dynamodb.mannequin.ListTablesRequest;
import software program.amazon.awssdk.companies.dynamodb.DynamoDbClient;
import java.util.Checklist;
import io.opentelemetry.extension.annotations.SpanAttribute;
import io.opentelemetry.extension.annotations.WithSpan;
/**
* Whats up world!
*
*/
public class App {
public static void listAllTables(DynamoDbClient ddb) {
System.out.println("DynamoDB Tables:");
boolean moreTables = true;
String lastName = null;
whereas (moreTables)
attempt catch (DynamoDbException e)
System.err.println(e.getMessage());
System.exit(1);
System.out.println("Finished!n");
}
public static void listAllBuckets(S3Client s3)
@WithSpan
public static void listAllBucketsAndTables(@SpanAttribute("title") String title, S3Client s3, DynamoDbClient ddb)
System.out.println(title);
listAllBuckets(s3);
listAllTables(ddb);
@WithSpan
public static void listTablesFirstAndThenBuckets(@SpanAttribute("title") String title, S3Client s3, DynamoDbClient ddb)
public static void principal(String[] args)
Area area = Area.EU_WEST_1;
S3Client s3 = S3Client.builder().area(area).construct();
DynamoDbClient ddb = DynamoDbClient.builder().area(area).construct();
listAllBucketsAndTables("My S3 buckets and DynamoDB tables", s3, ddb);
listTablesFirstAndThenBuckets("My DynamoDB tables first after which S3 bucket", s3, ddb);
s3.shut();
ddb.shut();
}And right here’s the up to date POM that features the extra OpenTelemetry dependencies:
<undertaking xmlns="http://maven.apache.org/POM/four.Zero.Zero" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/four.Zero.Zero http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>four.Zero.Zero</modelVersion>
<properties>
<undertaking.construct.sourceEncoding>UTF-Eight</undertaking.construct.sourceEncoding>
</properties>
<groupId>com.instance.myapp</groupId>
<artifactId>myapp</artifactId>
<packaging>jar</packaging>
<model>1.Zero-SNAPSHOT</model>
<identify>myapp</identify>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>software program.amazon.awssdk</groupId>
<artifactId>bom</artifactId>
<model>2.16.60</model>
<kind>pom</kind>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<model>three.Eight.1</model>
<scope>check</scope>
</dependency>
<dependency>
<groupId>software program.amazon.awssdk</groupId>
<artifactId>s3</artifactId>
</dependency>
<dependency>
<groupId>software program.amazon.awssdk</groupId>
<artifactId>dynamodb</artifactId>
</dependency>
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-extension-annotations</artifactId>
<model>1.5.Zero</model>
</dependency>
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-api</artifactId>
<model>1.5.Zero</model>
</dependency>
</dependencies>
<construct>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<model>three.Eight.1</model>
<configuration>
<supply>Eight</supply>
<goal>Eight</goal>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.instance.myapp.App</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</construct>
</undertaking>I compile my software with these adjustments and run it once more a couple of instances:
Now, let’s take a look at the X-Ray service map, computed utilizing the extra data supplied by these annotations.
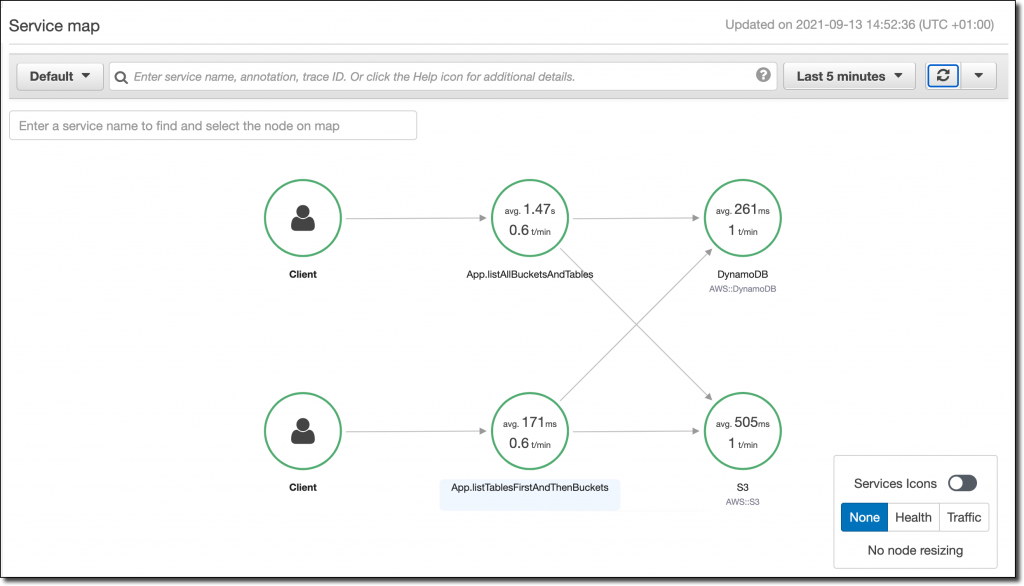
Now I see the 2 strategies and the opposite companies they invoke. If there are errors or excessive latency, I can simply perceive how the 2 strategies are affected.
Within the Traces part of the X-Ray console, I take a look at the Uncooked information for among the traces. As a result of the title argument was annotated with @SpanAttribute, every hint has the worth of that argument within the metadata part.

Amassing Traces from Lambda Capabilities
The earlier steps work on premises, on EC2, and with purposes operating in containers. To gather traces and use auto-instrumentation with Lambda capabilities, you should utilize the AWS managed OpenTelemetry Lambda Layers (a couple of examples are included within the repository).
After you add the Lambda layer to your perform, you should utilize the setting variable OPENTELEMETRY_COLLECTOR_CONFIG_FILE to go your individual configuration to the collector. Extra data on utilizing AWS Distro for OpenTelemetry with AWS Lambda is offered within the documentation.
Availability and Pricing
You should utilize AWS Distro for OpenTelemetry to get telemetry information out of your software operating on premises and on AWS. There aren’t any further prices for utilizing AWS Distro for OpenTelemetry. Relying in your configuration, you may pay for the AWS companies which might be locations for OpenTelemetry information, akin to AWS X-Ray, Amazon CloudWatch, and Amazon Managed Service for Prometheus (AMP).
To study extra, you might be invited to this webinar on Thursday, October 7 at 10:00 am PT / 1:00 pm EDT / 7:00 pm CEST.
Simplify the instrumentation of your purposes and enhance their observability utilizing AWS Distro for OpenTelemetry at this time.
— Danilo
[ad_2]
Source link





