[ad_1]
As Googlers transitioned to working from house through the pandemic, increasingly turned to chat-based help to assist them repair technical issues. Google’s IT help staff checked out many choices to assist us meet the elevated demand for tech help rapidly and effectively.
Extra workers? Not straightforward throughout a pandemic.
Let service ranges drop? Undoubtedly not.
Outsource? Not doable with our IT necessities.
Automation? Perhaps, simply perhaps…
How may we use AI to scale up our help operations, making our staff extra environment friendly?
The reply: Sensible Reply, a know-how developed by a Google Analysis staff with experience in machine studying, pure language understanding, and dialog modeling. This product supplied us with a chance to enhance our brokers’ skill to reply to queries from Googlers through the use of our corpus of chat knowledge. Sensible Reply trains a mannequin that gives strategies to techs in actual time. This reduces the cognitive load when multi-chatting and helps a tech drive classes in direction of decision.
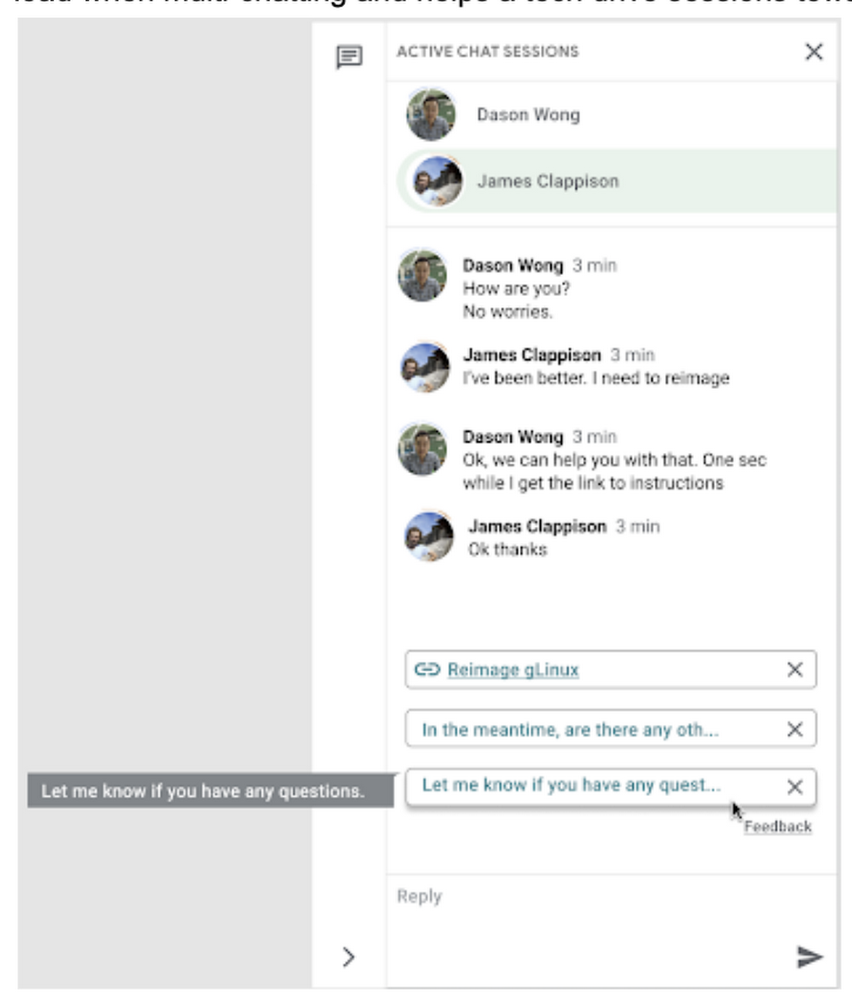
Within the answer detailed beneath, our hope is that IT groups in the same state of affairs can discover finest practices and some shortcuts to implementing the identical form of time saving options. Let’s get into it!
Challenges in getting ready our knowledge
Our tech help service for Google workers—Techstop—supplies a fancy service, providing help for a variety of merchandise and know-how stacks by chat, e-mail, and different channels.
Techstop has loads of knowledge. We obtain tons of of 1000’s of requests for assist per yr. As Google has advanced we’ve used a single database for all inner help knowledge, storing it as textual content, fairly than as protocol buffers. Not so good for mannequin coaching. To guard consumer privateness, we need to guarantee no PII (private identifiable info – e.g. usernames, actual names, addresses, or cellphone numbers) makes it into the mannequin.
To deal with these challenges we constructed a FlumeJava pipeline that takes our textual content and splits every message despatched by agent and requester into particular person traces, saved as repeated fields in a protocol buffer. As our pipe is executing this activity, it additionally sends textual content to the Google Cloud DLP API, eradicating private info from the session textual content, changing it with a redaction that we are able to later use on our frontend.
With the information ready within the appropriate format, we’re in a position to start our mannequin coaching. The mannequin supplies subsequent message strategies for techs based mostly on the general context of the dialog. To coach the mannequin we carried out tokenization, encoding, and dialogue attributes.
Splitting it up
The messages between the agent and buyer are tokenized: damaged up into discrete chunks for simpler use. This splitting of textual content into tokens have to be fastidiously thought of for a number of causes:
- Tokenization determines the scale of the vocabulary wanted to cowl the textual content.
- Tokens ought to try to separate alongside logical boundaries, aiming to extract the which means of the textual content.
- Tradeoffs might be made between the scale of every token, with smaller tokens growing processing necessities however enabling simpler correlation between completely different spans of textual content.
There are various methods to tokenize textual content (SAFT, splitting on white areas, and so on.), right here we selected sentence piece tokenization, with every token referring to a phrase section.
Prediction with encoders
Coaching the neural community with tokenized values has gone by a number of iterations. The staff used an Encoder-Decoder structure that took a given vector together with a token and used a softmax perform to foretell the chance that the token was prone to be the following token within the sentence/dialog. Beneath, a diagram represents this methodology utilizing LSTM-based recurrent networks. The facility of any such encoding comes from the power of the encoder to successfully predict not simply the following token, however the subsequent collection of tokens.
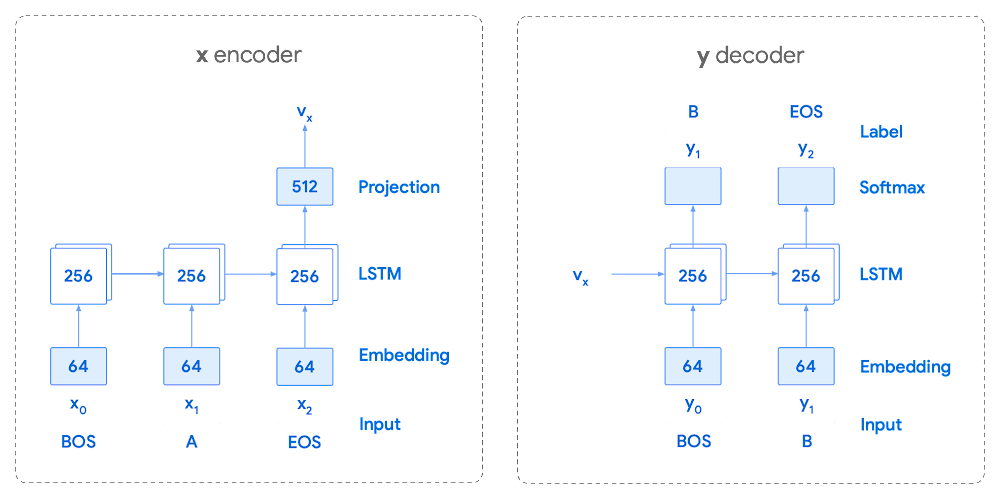
This has confirmed very helpful for Sensible Reply. To be able to discover the optimum sequence, an exponential search over every tree of doable future tokens is required. For this we opted to make use of beam search over a fixed-size checklist of finest candidates, aiming to keep away from growing the general reminiscence use and run time for returning a listing of strategies. To do that we organized tokens in a trie, and used a lot of put up processing methods, in addition to calculating a heuristic max rating for a given candidate, to scale back the time it takes to iterate by the whole token checklist. Whereas this improves the run time, the mannequin tends to favor shorter sequences.
To be able to assist cut back latency and enhance management we determined to maneuver to an Encoder-Encoder structure. As an alternative of predicting a single subsequent token and decoding a sequence of following predictions with a number of calls to the mannequin, it as an alternative encodes a candidate sequence with the neural community.
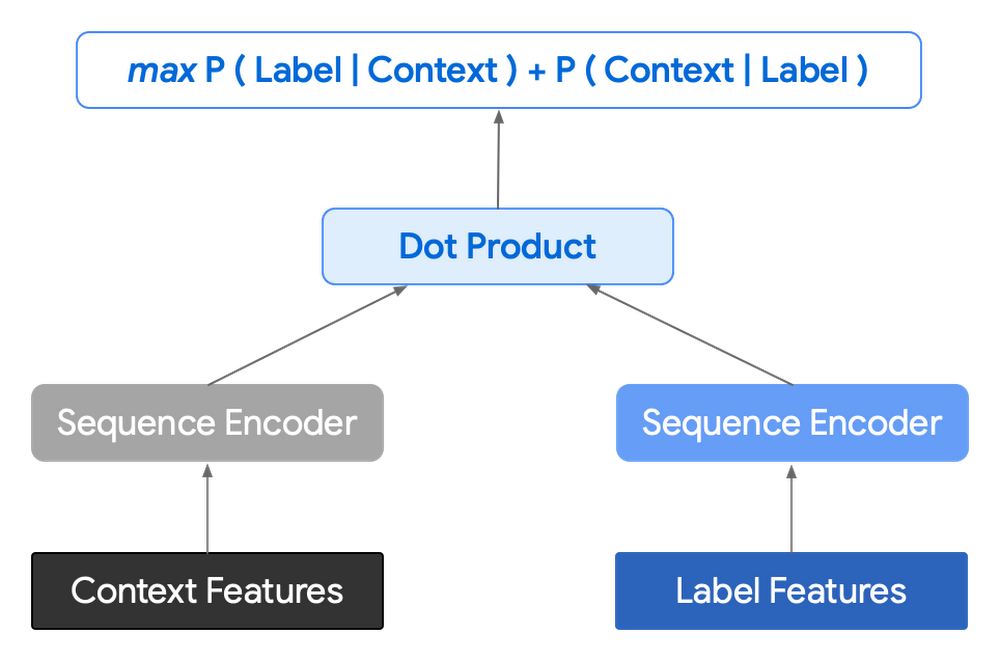
In follow, the 2 vectors – the context encoding and the encoding of a single candidate output – are mixed with dot product to reach at a rating for the given candidate. The purpose of this community is to maximise the rating for true candidates – e.g. candidates that did seem within the coaching set – and reduce false candidates.
Selecting the right way to pattern negatives impacts the mannequin coaching drastically. Beneath are some methods that may be employed:
- Utilizing constructive labels from different coaching examples within the batch.
- Drawing randomly from a set of frequent messages. This assumes that the empirical chance of every message is sampled accurately.
- Utilizing messages from context.
- Producing negatives from one other mannequin.
As this encoding generates a hard and fast checklist of candidates that may be precomputed and saved, every time a prediction is required, solely the context encoding must be computed, then multiplied by the matrix of candidate embeddings. This reduces each the time from the beam search methodology and the inherent bias in direction of shorter responses.
Dialogue Attributes
Conversations are greater than easy textual content modeling. The general circulate of the dialog between members supplies necessary info, altering the attributes of every message. The context, corresponding to who stated what to whom and when, provides helpful bits of enter for the mannequin when making a prediction. To that finish the mannequin makes use of the next attributes throughout its prediction:
- Native Person ID’s – we set a finite variety of members for a given dialog to signify the flip taking between messages, assigning values to these members. Generally for help classes there are 2 members, requiring ID zero, and 1.
- Replies vs continuations – initially modeling targeted solely on replies. Nevertheless, in follow conversations additionally embody cases the place members are following up on the beforehand despatched message. Given this, the mannequin is educated for each same-user strategies and “different” consumer strategies.
- Timestamps – gaps in dialog can point out a lot of various things. From a help perspective, gaps could point out that the consumer has disconnected. The mannequin takes this info and focuses on the time elapsed between messages, offering completely different predictions based mostly on the values.
Put up processing
Ideas can then be manipulated to get a extra fascinating ultimate rating. Such post-processing contains:
- Preferring longer strategies by including a token issue, generated by multiplying the variety of tokens within the present candidate.
- Demoting strategies with a excessive degree of overlap with beforehand despatched messages.
- Selling extra various strategies based mostly on embedding distance similarities.
To assist us tune and deal with one of the best responses the staff created a precedence checklist. This provides us the chance to affect the mannequin’s output, guaranteeing that responses which might be incorrect might be de-prioritized. Abstractly it may be regarded as a filter that may be calibrated to finest swimsuit the consumer’s wants.
Getting strategies to brokers
With our mannequin prepared we now wanted to get it within the palms of our techs. We wished our answer to be as agnostic to our chat platform as doable, permitting us to be agile when dealing with tooling adjustments and dashing up our skill to deploy different effectivity options. To this finish we wished an API that we may question both through gRPC or through HTTPs. We designed a Google Cloud API, chargeable for logging utilization in addition to appearing as a bridge between our mannequin and a Chrome Extension we’d be utilizing as a frontend.
The hidden step, measurement
As soon as we had our mannequin, infrastructure, and extension in place we have been left with the massive query for any IT challenge. What was our affect? One of many nice issues about working in IT at Google is that it’s by no means uninteresting. We’ve got fixed adjustments, be it deliberate or unplanned. Nevertheless, this does complicate measuring the success of a deployment like this. Did we enhance our service or was it only a quiet month?
To be able to be happy with our outcomes we performed an A/B experiment, with a few of our techs utilizing our extension, and the others not. The teams have been chosen at random with a distribution of techs throughout our world staff, together with a mixture of techs with various ranges of expertise starting from three to 26 months.
Our main purpose was to measure tech help effectivity when utilizing the instrument. We checked out two key metrics as proxies for tech effectivity:
- The general size of the chat.
- The variety of messages despatched by the tech.
Evaluating our experiment
To guage our knowledge we used a two-sample permutation take a look at. We had a null speculation that techs utilizing the extension wouldn’t have a decrease time-to-resolution, or be capable of ship extra messages, than these with out the extension. The choice speculation was that techs utilizing the extension would be capable of resolve classes faster or ship extra messages in roughly the identical time.
We took the mid imply of our knowledge, utilizing pandas to trim outliers higher than three customary deviations away. Because the distribution of our chat lengths shouldn’t be regular, with important proper skew attributable to a protracted tail of longer points, we opted to measure the distinction in means, counting on central restrict theorem (CLT) to offer us with our significance values. Any consequence with a p-value between 1.zero and 9.zero could be rejected.
Throughout the whole pool we noticed a lower in chat lengths of 36 seconds.
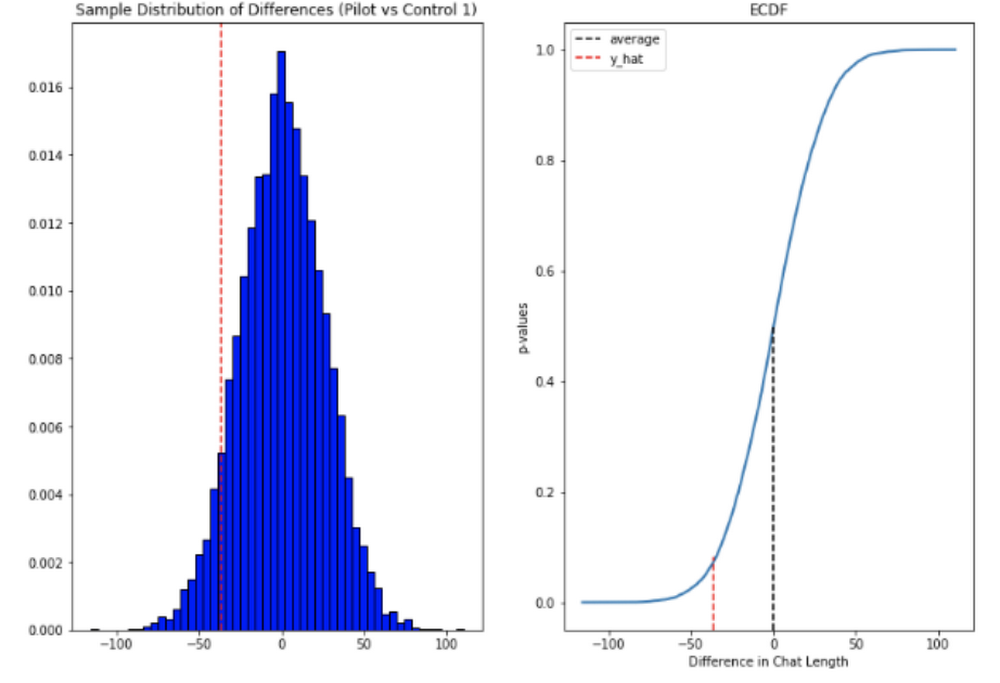
In reference to the variety of chat messages we noticed techs on common having the ability to ship 5-6 messages extra in much less time.
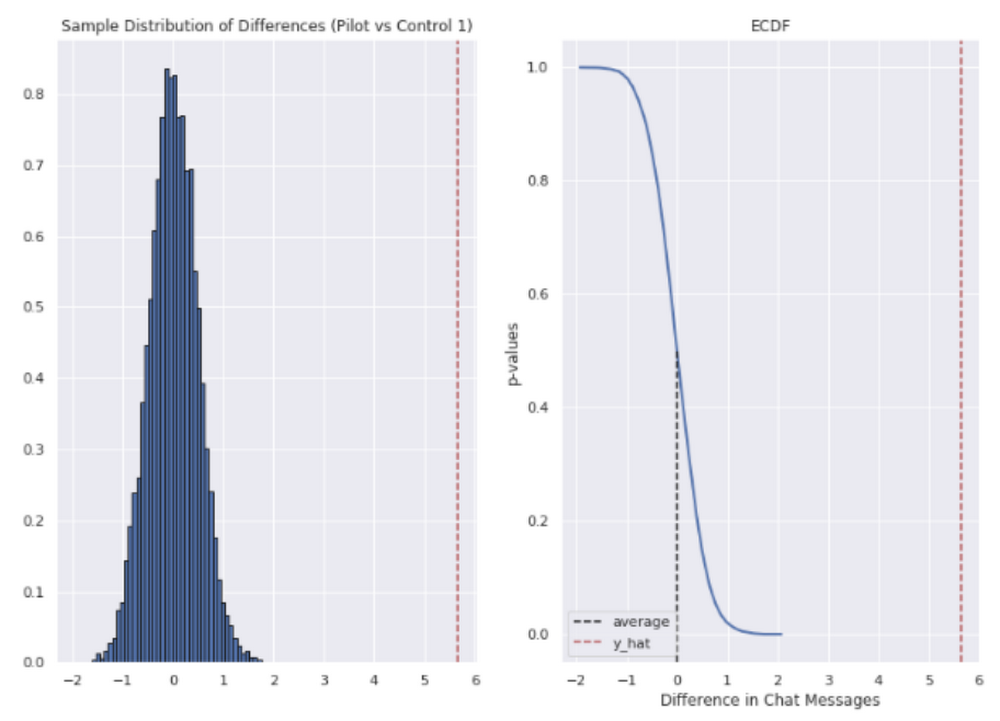
In brief, we noticed techs have been in a position to ship extra messages in a shorter time frame. Our outcomes additionally confirmed that these enhancements elevated with help agent tenure, and our extra senior techs have been in a position to save a mean of ~four minutes per help interplay.
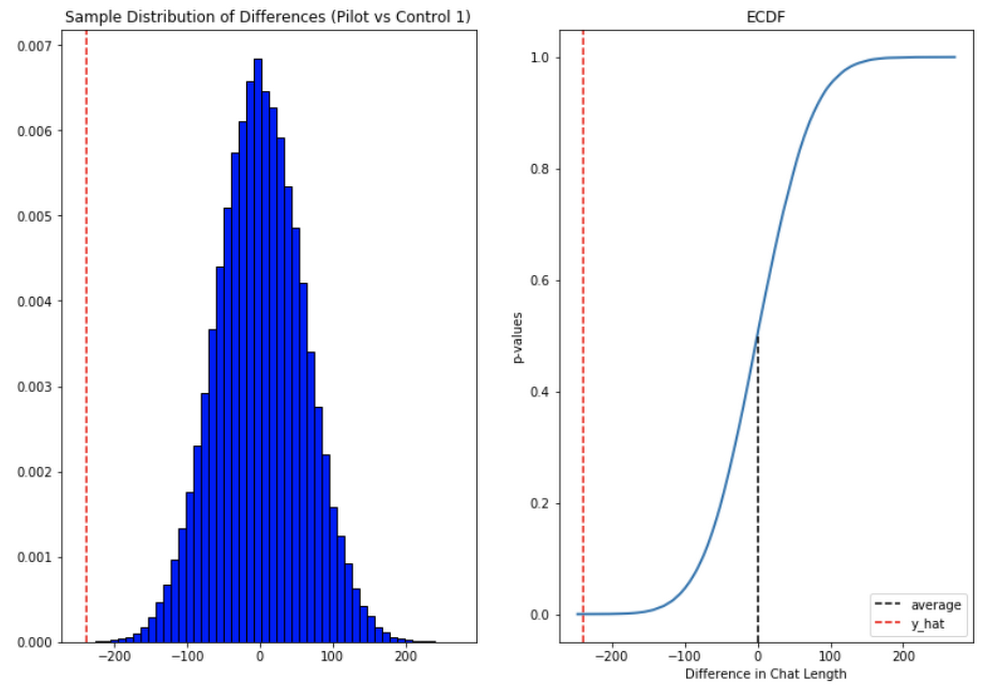
General we have been happy with the outcomes. Whereas issues weren’t excellent, it appeared like we have been onto a very good factor.
So what’s subsequent for us?
Like several ML challenge, the higher the information the higher the consequence. We’ll be spending time trying into the right way to present canonical strategies to our help brokers by clustering outcomes coming from our enable checklist. We additionally need to examine methods of bettering the help articles supplied by the mannequin, as something that helps our techs, notably the junior ones, with discoverability shall be an enormous win for us.
How will you do that?
A profitable utilized AI challenge at all times begins with knowledge. Start by gathering the data you’ve got, segmenting it up, after which beginning to course of it. The interplay knowledge you feed in will decide the standard of the strategies you get, so be sure to choose for the patterns you need to reinforce.
Our Contact Heart AI permits tokenization, encoding and reporting, with out you needing to design or prepare your individual mannequin, or create your individual measurements. It handles all of the coaching for you, as soon as your knowledge is formatted correctly.
You may nonetheless want to find out how finest to combine its strategies to your help system’s front-end. We additionally suggest doing statistical modeling to search out out if the strategies are making your help expertise higher.
As we gave our technicians ready-made replies to speak interactions, we saved time for our help staff. We hope you will attempt utilizing these strategies to assist your help staff scale.
[ad_2]
Source link




