
[ad_1]
The values you choose in your mannequin’s hyperparameters could make all of the distinction. When you’re solely making an attempt to tune a handful of hyperparameters, you may have the ability to run experiments manually. Nevertheless, with deep studying fashions the place you’re usually juggling hyperparameters for the structure, the optimizer, and discovering one of the best batch measurement and studying price, automating these experiments at scale shortly turns into a necessity.
On this article, we’ll stroll by an instance of the best way to run a hyperparameter tuning job with Vertex Coaching to find optimum hyperparameter values for an ML mannequin. To hurry up the coaching course of, we’ll additionally leverage the tf.distribute Python module to distribute code throughout a number of GPUs on a single machine. The entire code for this tutorial could be discovered on this pocket book.
To make use of the hyperparameter tuning service, you’ll must outline the hyperparameters you wish to tune in your coaching software code in addition to your customized coaching job request. In your coaching software code, you’ll outline a command-line argument for every hyperparameter, and use the worth handed in these arguments to set the corresponding hyperparameter in your code. You’ll additionally must report the metric you wish to optimize to Vertex AI utilizing thecloudml-hypertune Python package deal.
The instance supplied makes use of TensorFlow, however you should utilize Vertex Coaching with a mannequin written in PyTorch, XGBoost, or every other framework of your selection.
Utilizing the tf.distribute.Technique API
If in case you have a single GPU, TensorFlow will use this accelerator to hurry up mannequin coaching with no further work in your half. Nevertheless, if you wish to get an extra enhance from utilizing a number of GPUs on a single machine or a number of machines (every with probably a number of GPUs), then you definately’ll want to make use of tf.distribute, which is TensorFlow’s module for operating a computation throughout a number of gadgets. The best method to get began with distributed coaching is a single machine with a number of GPU gadgets. A TensorFlow distribution technique from the tf.distribute.Technique API will handle the coordination of knowledge distribution and gradient updates throughout all GPUs.
tf.distribute.MirroredStrategy is a synchronous knowledge parallelism technique that you should utilize with just a few code adjustments. This technique creates a replica of the mannequin on every GPU in your machine. The following gradient updates will occur in a synchronous method. Which means every employee gadget computes the ahead and backward passes by the mannequin on a special slice of the enter knowledge. The computed gradients from every of those slices are then aggregated throughout all the GPUs and decreased in a course of referred to as all-reduce. The optimizer then performs the parameter updates with these decreased gradients, thereby preserving the gadgets in sync.
Step one in utilizing the tf.distribute.Technique API is to create the technique object.
technique = tf.distribute.MirroredStrategy()
Subsequent, it’s worthwhile to wrap the creation of your mannequin variables inside the scope of the technique. This step is essential as a result of it tells MirroredStrategy which variables to reflect throughout your GPU gadgets.
Lastly, you’ll scale your batch measurement by the variety of GPUs. Whenever you do distributed coaching with thetf.distribute.Technique API and tf.knowledge, the batch measurement now refers back to the international batch measurement. In different phrases, when you go a batch measurement of 16, and you’ve got two GPUs, then every machine will course of eight examples per step. On this case, 16 is called the worldwide batch measurement, and eight because the per duplicate batch measurement. To take advantage of out of your GPUs, you’ll wish to scale the batch measurement by the variety of replicas.
GLOBAL_BATCH_SIZE = PER_REPLICA_BATCH_SIZE * technique.num_replicas_in_sync
Notice that distributing the code is optionally available. You’ll be able to nonetheless use the hyperparameter tuning service by following the steps within the subsequent part even when you don’t want to make use of a number of GPUs.
Replace coaching code for hyperparameter tuning
To make use of hyperparameter tuning with Vertex Coaching, there are two adjustments you’ll must make to your coaching code.
First, you’ll must outline a command-line argument in your predominant coaching module for every hyperparameter you wish to tune. You’ll then use the worth handed in these arguments to set the corresponding hyperparameter in your software’s code.
Let’s say we wished to tune the educational price, the optimizer momentum worth, and the variety of neurons within the mannequin’s closing hidden layer. You should use argparse to parse the command line arguments as proven within the operate under.
You’ll be able to choose no matter names you want for these arguments, however it’s worthwhile to use the worth handed in these arguments to set the corresponding hyperparameter in your software’s code. For instance, your optimizer may appear like:
Now that we all know what hyperparameters we wish to tune, we have to decide the metric to optimize. After the hyperparameter tuning service runs a number of trials, the hyperparameter values we’ll choose for our mannequin would be the mixture that maximizes (or minimizes) the chosen metric.
We will report this metric with the assistance of the cloudml-hypertune library, which you should utilize with any framework.
import hypertune
In TensorFlow, the keras mannequin.match methodology returns a Historical past object.
The Historical past.historical past attribute is a file of coaching loss values and metrics values at successive epochs. When you go validation knowledge to mannequin.match the Historical past.historical past attribute will embody validation loss and metrics values as properly.
For instance, when you educated a mannequin for 3 epochs with validation knowledge and supplied accuracy as a metric, the Historical past.historical past attribute would look just like the next dictionary.
To pick the values for studying price, momentum, and variety of models that maximize the validation accuracy, we’ll outline our metric because the final entry (or NUM_EPOCS - 1) of the 'val_accuracy' listing.
Then, we go this metric to an occasion of HyperTune, which is able to report the worth to Vertex AI on the finish of every coaching run.
And that’s it! With these two simple steps, your coaching software is prepared.
Launch hyperparameter tuning Job
When you’ve modified your coaching software code, you possibly can launch the hyperparameter tuning job. This instance demonstrates the best way to launch the job with the Python SDK, however you may as well use the Cloud console UI.
You’ll must make it possible for your coaching software code is packaged up as a customized container. When you’re unfamiliar with how to try this, confer with this tutorial for detailed directions.
In a pocket book, create a brand new Python three pocket book from the launcher.

In your pocket book, run the next in a cell to put in the Vertex AI SDK. As soon as the cell finishes, restart the kernel.
!pip3 set up google-cloud-aiplatform --upgrade --user
After restarting the kernel, import the SDK:
To launch the hyperparameter tuning job, it’s worthwhile to first outline the worker_pool_specs, which specifies the machine sort and Docker picture. The next spec defines one machine with two NVIDIA T4 Tensor Core GPUs.
Subsequent, outline the parameter_spec, which is a dictionary specifying the parameters you wish to optimize. The dictionary secret is the string you assigned to the command line argument for every hyperparameter, and the dictionary worth is the parameter specification.
For every hyperparameter, it’s worthwhile to outline the Sort in addition to the bounds for the values that the tuning service will strive. If you choose the sort Double or Integer, you’ll want to offer a minimal and most worth. And if you choose Categorical or Discrete you’ll want to offer the values. For the Double and Integer varieties, you’ll additionally want to offer the Scaling worth. You’ll be able to be taught extra about the best way to choose one of the best scale on this video.
The ultimate spec to outline is metric_spec, which is a dictionary representing the metric to optimize. The dictionary secret is the hyperparameter_metric_tag that you just set in your coaching software code, and the worth is the optimization purpose.
metric_spec='accuracy':'maximize'
As soon as the specs are outlined, you’ll create a CustomJob, which is the widespread spec that can be used to run your job on every of the hyperparameter tuning trials.
You may want to interchangewith a bucket in your mission for staging.
Lastly, create and run the HyperparameterTuningJob.
There are just a few arguments to notice:
max_trial_count: You’ll must put an higher sure on the variety of trials the service will run. Extra trials usually results in higher outcomes, however there can be a degree of diminishing returns, after which extra trials have little or no impact on the metric you’re making an attempt to optimize. It’s a greatest observe to begin with a smaller variety of trials and get a way of how impactful your chosen hyperparameters are earlier than scaling up.parallel_trial_count: When you use parallel trials, the service provisions a number of coaching processing clusters. The employee pool spec that you just specify when creating the job is used for every particular person coaching cluster. Growing the variety of parallel trials reduces the period of time the hyperparameter tuning job takes to run; nevertheless, it could possibly scale back the effectiveness of the job total. It’s because the default tuning technique makes use of outcomes of earlier trials to tell the project of values in subsequent trials.search_algorithm: You’ll be able to set the search algorithm to grid, random, or default (None). Grid search will exhaustively search by the hyperparameters, however just isn’t possible in high-dimensional house. Random search samples the search house randomly. The draw back of random search is that it doesn’t use data from prior experiments to pick out the subsequent setting. The default choice applies Bayesian optimization to go looking the house of potential hyperparameter values and is the really helpful algorithm. If you wish to be taught extra in regards to the particulars of how this Bayesian optimization works, take a look at this weblog.
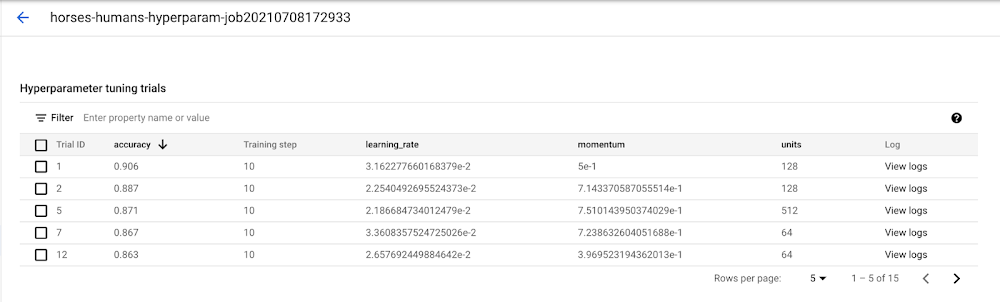
As soon as the job kicks off, you’ll have the ability to observe the standing within the UI beneath the HYPERPARAMETER TUNING JOBS tab.

When it is completed, you’ll click on on the job title and see the outcomes of the tuning trials.
What’s subsequent
You now know the fundamentals of the best way to use hyperparameter tuning with Vertex Coaching. If you wish to check out a working instance from begin to end, you possibly can check out this tutorial. Or when you’d wish to study multi-worker coaching on Vertex, see this tutorial. It’s time to run some experiments of your individual!
[ad_2]
Source link




