
[ad_1]

|
Final AWS re:Invent, we introduced the overall availability of Amazon EMR on Amazon Elastic Kubernetes Service (Amazon EKS), a brand new deployment possibility for Amazon EMR that enables clients to automate the provisioning and administration of Apache Spark on Amazon EKS.
With Amazon EMR on EKS, clients can deploy EMR functions on the identical Amazon EKS cluster as different sorts of functions, which permits them to share sources and standardize on a single resolution for working and managing all their functions. Clients operating Apache Spark on Kubernetes can migrate to EMR on EKS and reap the benefits of the performance-optimized runtime, integration with Amazon EMR Studio for interactive jobs, integration with Apache Airflow and AWS Step Capabilities for operating pipelines, and Spark UI for debugging.
When clients submit jobs, EMR mechanically packages the appliance right into a container with the massive information framework and offers prebuilt connectors for integrating with different AWS companies. EMR then deploys the appliance on the EKS cluster and manages operating the roles, logging, and monitoring. When you at the moment run Apache Spark workloads and use Amazon EKS for different Kubernetes-based functions, you should use EMR on EKS to consolidate these on the identical Amazon EKS cluster to enhance useful resource utilization and simplify infrastructure administration.
Builders who run containerized, massive information analytical workloads instructed us they simply wish to level to a picture and run it. At the moment, EMR on EKS dynamically provides externally saved utility dependencies throughout job submission.
At the moment, I’m joyful to announce customizable picture help for Amazon EMR on EKS that enables clients to switch the Docker runtime picture that runs their analytics utility utilizing Apache Spark in your EKS cluster.
With customizable pictures, you’ll be able to create a container that accommodates each your utility and its dependencies, primarily based on the performance-optimized EMR Spark runtime, utilizing your individual steady integration (CI) pipeline. This reduces the time to construct the picture and helps predicting container launches for an area growth or take a look at.
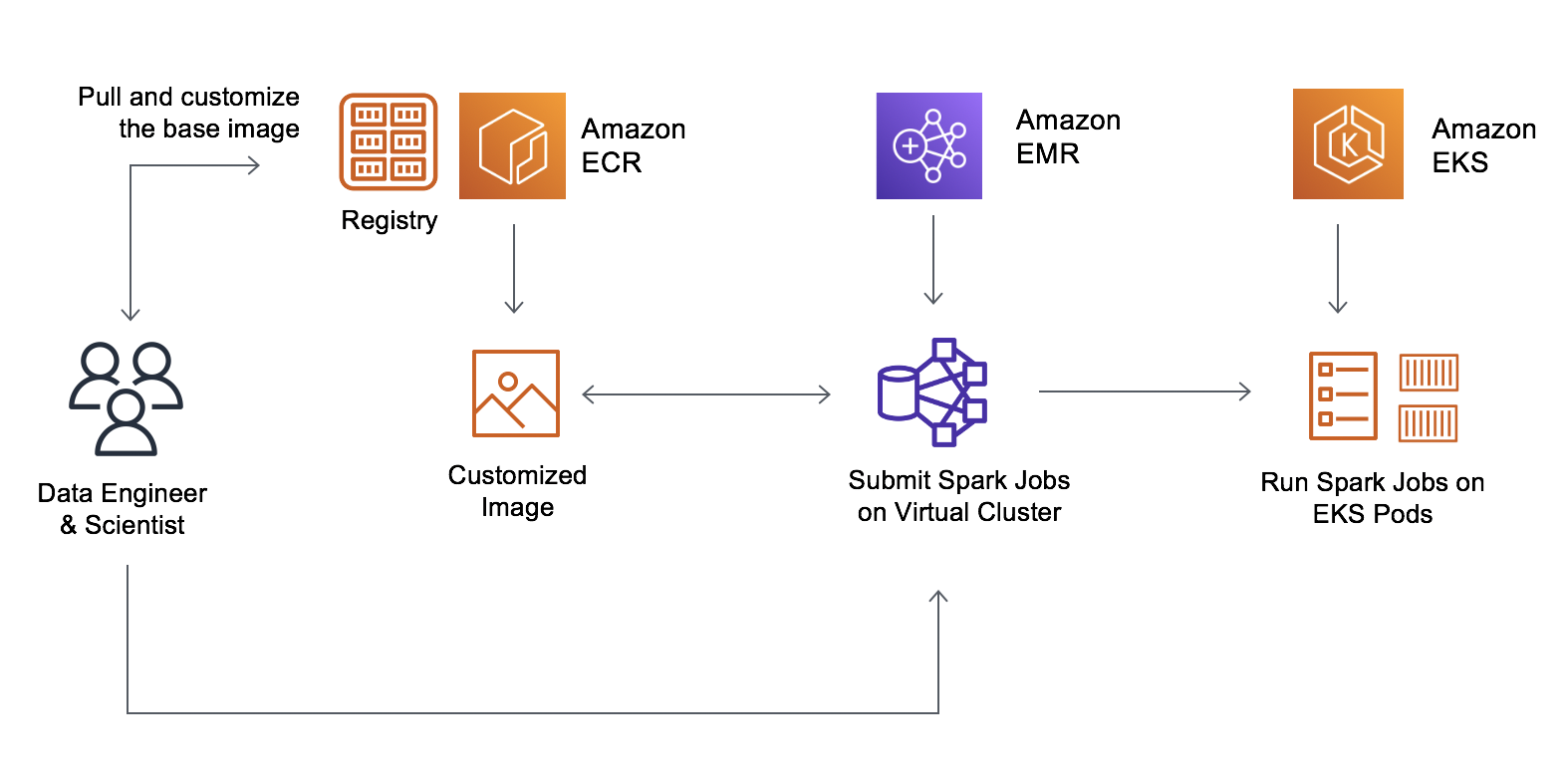
Now, information engineers and platform groups can create a base picture, add their company customary libraries, after which retailer it in Amazon Elastic Container Registry (Amazon ECR). Information scientists can customise the picture to incorporate their utility particular dependencies. The ensuing immutable picture will be vulnerability scanned, deployed to check and manufacturing environments. Builders can now merely level to the custom-made picture and run it on EMR on EKS.
Customizable Runtime Photographs – Getting Began
To get began with customizable pictures, use the AWS Command Line Interface (AWS CLI) to carry out these steps:
- Register your EKS cluster with Amazon EMR.
- Obtain the EMR-provided base pictures from Amazon ECR and modify the picture along with your utility and libraries.
- Publish your custom-made picture to a Docker registry equivalent to Amazon ECR after which submit your job whereas referencing your picture.
You’ll be able to obtain one of many following base pictures. These pictures include the Spark runtime that can be utilized to run batch workloads utilizing the EMR Jobs API. Right here is the most recent full picture checklist accessible.
| Launch Label | Spark Hadoop Variations | Base Picture Tag |
| emr-5.32.Zero-latest | Spark 2.four.7 + Hadoop 2.10.1 | emr-5.32.Zero-20210129 |
| emr-5.33-latest | Spark 2.four.7-amzn-1 + Hadoop 2.10.1-amzn-1 | emr-5.33.Zero-20210323 |
| emr-6.2.Zero-latest | Spark Three.Zero.1 + Hadoop Three.2.1 | emr-6.2.Zero-20210129 |
| emr-6.Three-latest | Spark Three.1.1-amzn-Zero + Hadoop Three.2.1-amzn-Three | emr-6.Three.Zero:newest |
These base pictures are positioned in an Amazon ECR repository in every AWS Area with a picture URI that mixes the ECR registry account, AWS Area code, and base picture tag within the case of US East (N. Virginia) Area.
755674844232.dkr.ecr.us-east-1.amazonaws.com/spark/emr-5.32.Zero-20210129
Now, check in to the Amazon ECR repository and pull the picture into your native workspace. If you wish to pull a picture from a distinct AWS Area to cut back community latency, select the totally different ECR repository that corresponds most intently to the place you’re pulling the picture from US West (Oregon) Area.
$ aws ecr get-login-password --region us-west-2 | docker login --username AWS --password-stdin 895885662937.dkr.ecr.us-west-2.amazonaws.com
$ docker pull 895885662937.dkr.ecr.us-west-2.amazonaws.com/spark/emr-5.32.Zero-20210129Create a Dockerfile in your native workspace with the EMR-provided base picture and add instructions to customise the picture. If the appliance requires customized Java SDK, Python, or R libraries, you’ll be able to add them to the picture immediately, simply as with different containerized functions.
The next instance Docker instructions are for a use case during which you wish to set up helpful Python libraries equivalent to Pure Language Processing (NLP) utilizing Spark and Pandas.
FROM 895885662937.dkr.ecr.us-west-2.amazonaws.com/spark/emr-5.32.Zero-20210129
USER root
### Add customizations right here ####
RUN pip3 set up pyspark pandas spark-nlp // Set up Python NLP Libraries
USER hadoop:hadoopIn one other use case, as I discussed, you’ll be able to set up a distinct model of Java (for instance, Java 11):
FROM 895885662937.dkr.ecr.us-west-2.amazonaws.com/spark/emr-5.32.Zero-20210129
USER root
### Add customizations right here ####
RUN yum set up -y java-11-amazon-corretto // Set up Java 11 and set house
ENV JAVA_HOME /usr/lib/jvm/java-11-amazon-corretto.x86_64
USER hadoop:hadoopWhen you’re altering Java model to 11, you then additionally want to vary Java Digital Machine (JVM) choices for Spark. Present the next choices in applicationConfiguration once you submit jobs. You want these choices as a result of Java 11 doesn’t help some Java eight JVM parameters.
"applicationConfiguration": [
"classification": "spark-defaults",
"properties":
"spark.driver.defaultJavaOptions" : "
-XX:OnOutOfMemoryError="kill -9 %p" -XX:MaxHeapFreeRatio=70",
"spark.executor.defaultJavaOptions" : "
-verbose:gc -Xlog:gc*::time -XX:+PrintGCDetails -XX:+PrintGCDateStamps
-XX:OnOutOfMemoryError="kill -9 %p" -XX:MaxHeapFreeRatio=70
-XX:+IgnoreUnrecognizedVMOptions"
]To make use of customized pictures with EMR on EKS, publish your custom-made picture and submit a Spark workload in Amazon EMR on EKS utilizing the accessible Spark parameters.
You’ll be able to submit batch workloads utilizing your custom-made Spark picture. To submit batch workloads utilizing the StartJobRun API or CLI, use the spark.kubernetes.container.picture parameter.
$ aws emr-containers start-job-run
--virtual-cluster-id <enter-virtual-cluster-id>
--name sample-job-name
--execution-role-arn <enter-execution-role-arn>
--release-label <base-release-label> # Base EMR Launch Label for the customized picture
--job-driver '
"sparkSubmitJobDriver":
"entryPoint": "native:///usr/lib/spark/examples/jars/spark-examples.jar",
"entryPointArguments": ["1000"],
"sparkSubmitParameters": [ "--class org.apache.spark.examples.SparkPi --conf spark.kubernetes.container.picture=123456789012.dkr.ecr.us-west-2.amazonaws.com/emr5.32_custom"
]
'Use the kubectl command to substantiate the job is operating your customized picture.
$ kubectl get pod -n <namespace> | grep "driver" | awk ''
Instance output: k8dfb78cb-a2cc-4101-8837-f28befbadc92-1618856977200-driverGet the picture for the primary container within the Driver pod (Makes use of jq).
$ kubectl get pod/<driver-pod-name> -n <namespace> -o json | jq '.spec.containers
| .[] | choose(.title=="spark-kubernetes-driver") | .picture '
Instance output: 123456789012.dkr.ecr.us-west-2.amazonaws.com/emr5.32_customTo view jobs within the Amazon EMR console, beneath EMR on EKS, select Digital clusters. From the checklist of digital clusters, choose the digital cluster for which you wish to view logs. On the Job runs desk, choose View logs to view the small print of a job run.

Automating Your CI Course of and Workflows
Now you can customise an EMR-provided base picture to incorporate an utility to simplify utility growth and administration. With customized pictures, you’ll be able to add the dependencies utilizing your current CI course of, which lets you create a single immutable picture that accommodates the Spark utility and all of its dependencies.
You’ll be able to apply your current growth processes, equivalent to vulnerability scans towards your Amazon EMR picture. You too can validate for proper file construction and runtime variations utilizing the EMR validation instrument, which will be run domestically or built-in into your CI workflow.
The APIs for Amazon EMR on EKS are built-in with orchestration companies like AWS Step Capabilities and AWS Managed Workflows for Apache Airflow (MWAA), permitting you to incorporate EMR customized pictures in your automated workflows.
Now Accessible
Now you can arrange customizable pictures in all AWS Areas the place Amazon EMR on EKS is accessible. There isn’t a extra cost for customized pictures. To study extra, see the Amazon EMR on EKS Improvement Information and a demo video construct your individual pictures for operating Spark jobs on Amazon EMR on EKS.
You’ll be able to ship suggestions to the AWS discussion board for Amazon EMR or by means of your traditional AWS help contacts.
— Channy
[ad_2]
Source link





