
[ad_1]

|
Amazon Redshift already supplies as much as 3x higher price-performance at any scale than some other cloud knowledge warehouse. We do that by designing our personal and by utilizing Machine Studying (ML).
For instance, we launched the SSD-based RA3 nodes for Amazon Redshift on the finish of 2019 (Amazon Redshift Replace – Subsequent-Technology Compute Cases and Managed, Analytics-Optimized Storage) and added extra node sizes final April (Amazon Redshift replace – ra3.4xlarge Nodes), and final December (Amazon Redshift Launches RA3.xlplus Nodes With Managed Storage). Along with high-bandwidth networking, RA3 nodes incorporate a classy knowledge administration mannequin. As I mentioned once we launched the RA3 nodes:
There’s a cache of large-capacity, high-performance SSD-based storage on every occasion, backed by S3, for scale, efficiency, and sturdiness. The storage system makes use of a number of cues, together with knowledge block temperature, knowledge blockage, and workload patterns, to handle the cache for top efficiency. Information is mechanically positioned into the suitable tier, and you needn’t do something particular to profit from the caching or the opposite optimizations.
Our clients use RA3 nodes to take care of very massive knowledge units and are seeing nice outcomes. From digital interactive leisure to monitoring impressions and efficiency for media buys, Amazon Redshift and RA3 nodes assist our clients to retailer and question knowledge at world scale, with as much as 32 PB of information in a single knowledge warehouse.
On the draw back, it seems that advances in storage efficiency have outpaced these in CPU efficiency, whilst knowledge warehouses proceed to develop. The mixture of enormous quantities of information (usually accessed by queries that mandate a full scan), and limits on community site visitors, may end up in a scenario the place community and CPU bandwidth grow to be limiting elements.
We will do one thing about that…
Introducing AQUA Right now we’re making the ra3.4xl and ra3.16xl nodes much more highly effective with the addition of AQUA (Superior Question Accelerator). Constructing on the caches that I advised you about earlier, and making the most of the AWS Nitro System and FPGA-based acceleration, AQUA pushes the computation wanted to deal with discount and aggregation queries nearer to the information. This reduces community site visitors, offloads work from the CPUs within the RA3 nodes, and permits AQUA to enhance the efficiency of these queries by as much as 10x, at no further price and with none code modifications. AQUA additionally makes use of a quick, high-bandwidth connection to Amazon Easy Storage Service (S3).
Right now we’re making the ra3.4xl and ra3.16xl nodes much more highly effective with the addition of AQUA (Superior Question Accelerator). Constructing on the caches that I advised you about earlier, and making the most of the AWS Nitro System and FPGA-based acceleration, AQUA pushes the computation wanted to deal with discount and aggregation queries nearer to the information. This reduces community site visitors, offloads work from the CPUs within the RA3 nodes, and permits AQUA to enhance the efficiency of these queries by as much as 10x, at no further price and with none code modifications. AQUA additionally makes use of a quick, high-bandwidth connection to Amazon Easy Storage Service (S3).
You’ll be able to watch this video to be taught much more about how AQUA makes use of the custom-designed within the AQUA nodes to speed up queries. The profit comes about in a number of other ways. Every node performs the discount and aggregation operations in parallel with the others. Along with getting the n-fold speedup as a result of parallelism, the quantity of information that have to be despatched to and processed on the compute nodes is usually far smaller (usually simply 5% of the unique). Right here’s a diagram that exhibits how all the parts come collectively to speed up queries:
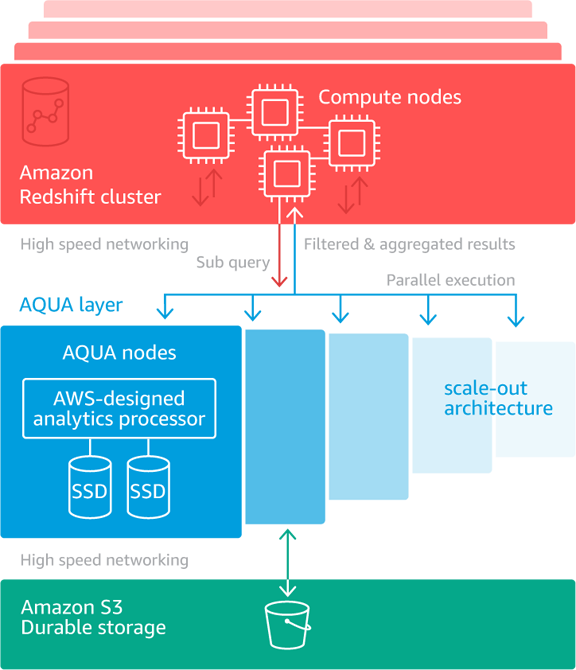
If you’re already utilizing ra3.4xl or ra3.16xl nodes to host your knowledge warehouse, you can begin utilizing AQUA in minutes. You merely allow AQUA on your clusters, restart them, and profit from vastly improved efficiency on your discount and aggregation queries. If you’re prepared to maneuver into the longer term with RA3 and AQUA, you may create a brand new RA3-based cluster from a snapshot of your present one, or you should use Basic resize to do an in-place improve.
Utilizing AQUA
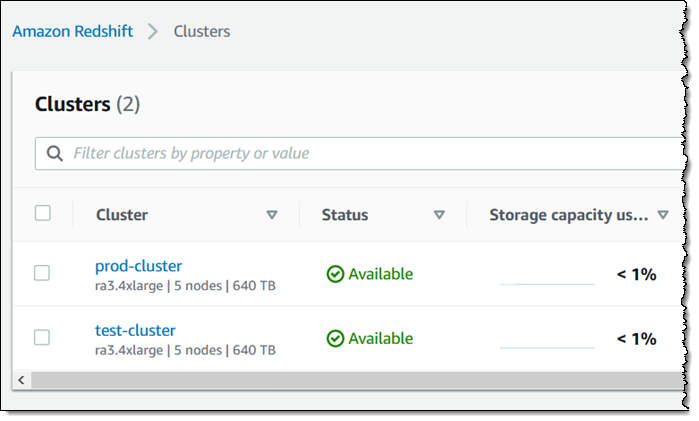
I don’t occur to have an information warehouse! I used a snapshot supplied by the Redshift crew to create a pair of clusters. The primary one (prod-cluster) doesn’t have AQUA enabled, and the second (test-cluster) does:
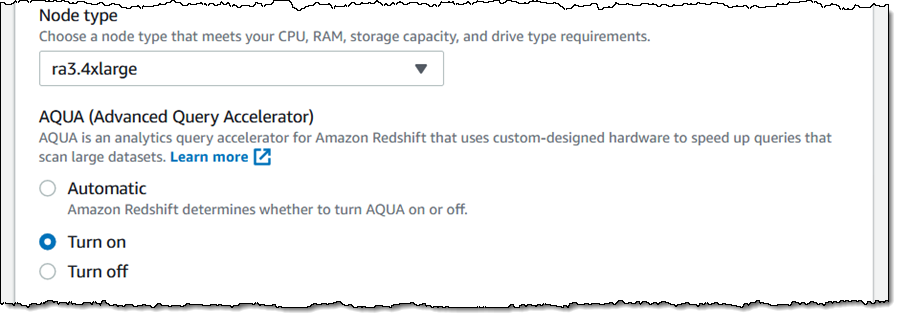
To create the AQUA-enabled cluster, I merely select Activate on the Cluster configuration web page:
My queries will use the lineitem desk, which has over 18 billion rows:
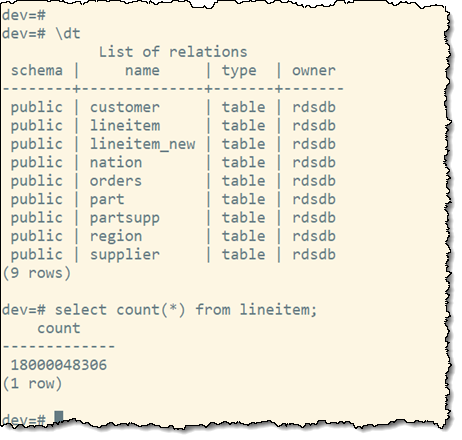
I create a session on every cluster and disable the Redshift outcome cache:
After which I run the identical question on each clusters:
For those who check out the diagram above (and maybe watch the video), you may see why AQUA can deal with queries of this kind very effectively. As a substitute of sequentially scanning all 18 billion or so rows on the compute nodes, AQUA distributes the gathering of much like expressions to a number of AQUA nodes the place they’re run in parallel.
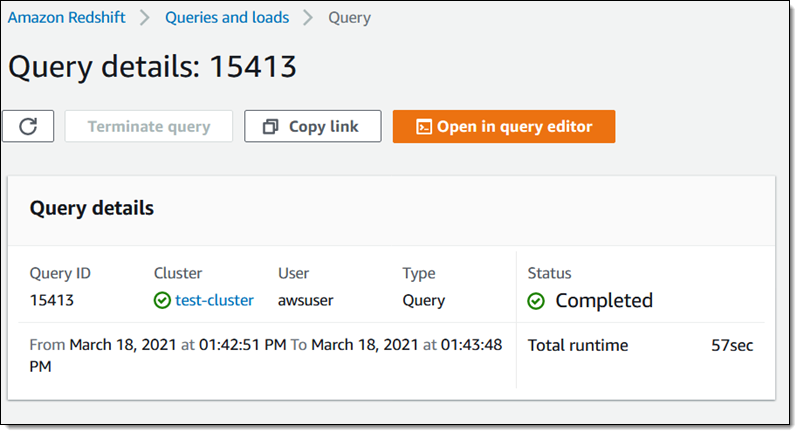
The question on the cluster that has AQUA enabled finishes in lower than a minute:
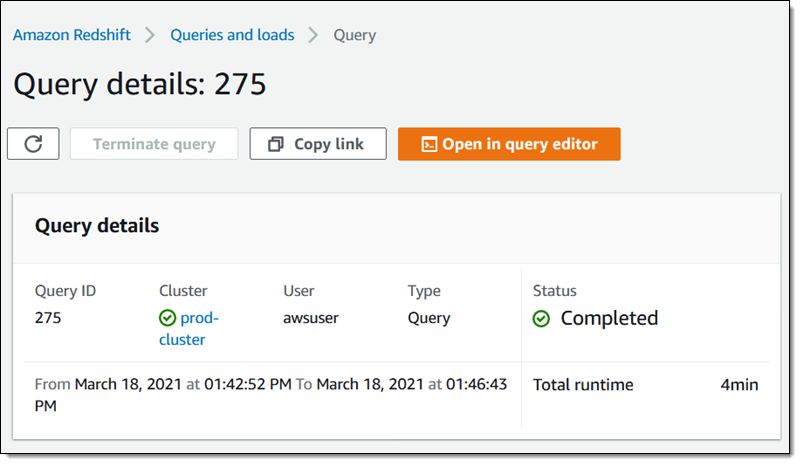
The question on the cluster that doesn’t have AQUA enabled finishes in just a little underneath four minutes:
As is at all times the case with databases, advanced knowledge, and equally advanced queries, your mileage will fluctuate. For instance, you could possibly think about a question that did a fancy JOIN of rows SELECTed from a number of tables, the place every SELECT would profit from AQUA, and the general speedup might be even larger. As you may see from the straightforward question that I used for this put up, AQUA can dramatically scale back question time and even perhaps allow some new forms of considerably real-time queries that have been merely not potential or sensible prior to now.
Issues to Know
Listed here are a few attention-grabbing details about AQUA:
Cluster Model – Your clusters have to be operating Redshift model 1.zero.24421 or later so as to have the ability to make use of AQUA. To be taught extra about the best way to allow and disable AQUA, learn Managing an AQUA Cluster.
Related Queries – AQUA is designed to ship as much as 10X efficiency on queries that carry out massive scans, aggregates, and filtering with LIKE and SIMILAR_TO predicates. Over time we anticipate so as to add help for extra queries.
Safety – All knowledge cached by AQUA is encrypted utilizing your keys. After performing a filtering or aggregation operation, AQUA compresses the outcomes, encrypts them, and returns them to Redshift.
Areas – AQUA is offered as we speak within the US East (N. Virginia), US West (Oregon), US East (Ohio), Europe (Eire), and Asia Pacific (Tokyo) Areas, and might be coming to Europe (Frankfurt), Asia Pacific (Sydney), and Asia Pacific (Singapore) within the first half of 2021.
Pricing – As I discussed earlier, there’s no extra cost for AQUA.
Strive AQUA Right now
If you’re utilizing ra3.4xl or ra3.16xl nodes to energy your Redshift cluster, you may allow AQUA, restart the cluster, and run some check queries inside minutes. Take AQUA for a spin and let me know what you assume!
— Jeff;
[ad_2]
Source link





