
[ad_1]
BigQuery is Google’s flagship knowledge analytics providing, enabling corporations of all sizes to execute analytical workloads. To get probably the most out of BigQuery, it’s essential to grasp and monitor your workloads to maintain your purposes operating reliably. Fortunately, with Google’s INFORMATION_SCHEMA views, monitoring your group’s use at scale has by no means been simpler. As we speak, we’ll stroll by tips on how to monitor your BigQuery reservation and optimize efficiency.
Understanding Workloads and Reservations
Our first step is to research your organization-wide historic slot utilization. With reservations, you’ll be able to allocate capability, or slots, to designated teams of GCP tasks in your group. When organizing tasks, think about grouping them in keeping with workloads, groups, or departments. We encourage you to isolate these teams of tasks, or particular workloads, in separate reservations. This may assist with monitoring and general useful resource planning to trace traits in development.
In apply, this may seem like the next: escape enterprise models, like advertising and marketing or finance, and separate recognized, persistent workloads like ETL pipelines from extra ad-hoc workloads like dashboarding. Isolating workloads like because of this any burst in useful resource utilization from one reservation can be unable to adversely affect one other reservation; a sudden surge from a dashboarding activity received’t intervene with ETL schedules. This may decrease any disruptions attributable to unanticipated spikes, in addition to enable reservations to satisfy their SLOs in order that jobs can full on time.
How Scheduling Works
To raised perceive why isolation issues, it’s essential to grasp BigQuery’s Scheduler. BigQuery makes use of a notion of equity for allocating slots. First, BigQuery assigns slots on the reservation stage. From inside a reservation, slots are then assigned equally amongst all lively tasks, the place lively signifies a mission that’s at the moment executing a question. From inside every lively mission, slots are then allotted to all operating jobs to make sure that every job is ready to make ahead progress.
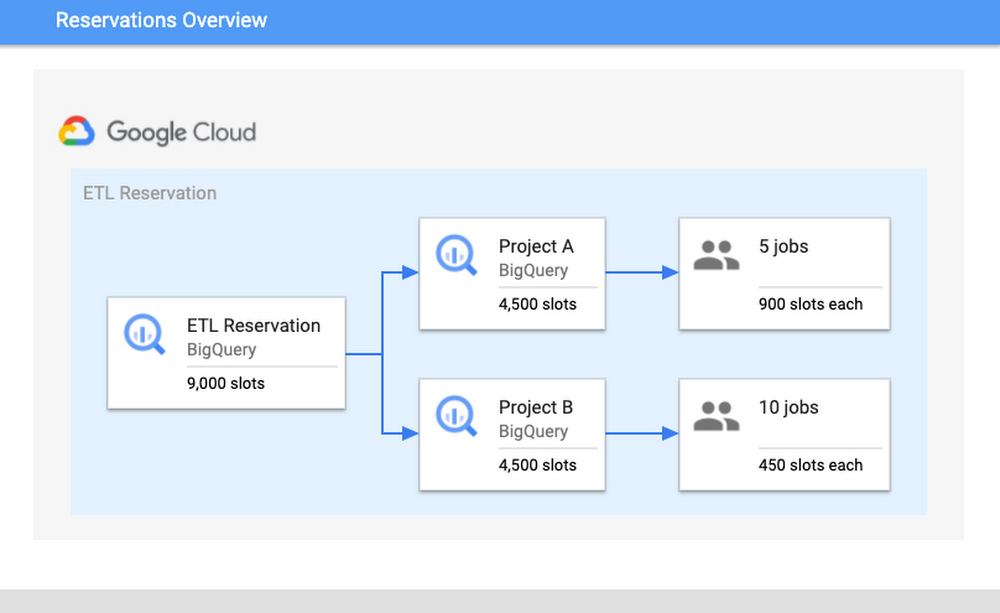
Think about the next situation: there’s a reservation “ETL” that has 9,000 slots, which comprises Undertaking A and Undertaking B. Undertaking A is at the moment operating 5 jobs and Undertaking B is operating ten jobs. Assuming that each one jobs require most slots to finish their jobs, then every mission would get four,500 slots every. The 5 jobs in Undertaking A would obtain 900 slots every and the ten jobs in Undertaking B would obtain 450 slots. These per-job slot allocations are recomputed consistently, relying on every job’s want and present state as a way to make progress.
Upon getting optimized your isolation configuration, the subsequent step is to look at your utilization and configure your slot allocation. A excessive slot utilization implies good cost-efficiency; because of this the sources that you simply’re paying for usually are not sitting idle. Nevertheless, you don’t wish to get too near 100% utilization. Working too near 100% leaves you with out a buffer for potential spikes in utilization. If a spike does happen and drive you over 100%, it may possibly trigger useful resource competitors and common slowness to your customers.
Bettering and monitoring question efficiency
To watch efficiency, we’ll stroll by widespread root causes, indicators to search for, as properly potential steps for mitigation. Our purpose for the sake of this instance can be elevated efficiency to your queries.
We’ll begin by evaluating the info from the INFORMATION_SCHEMA views. Particularly, to grasp variations in question efficiency, we are going to take two related queries and evaluate their INFORMATION_SCHEMA job knowledge. Observe: it’s essential that these jobs are related and are anticipated to generate comparable output. This may imply evaluating the identical job executed at hour A vs. hour B or the identical job that learn in partitions from date A vs. date B.
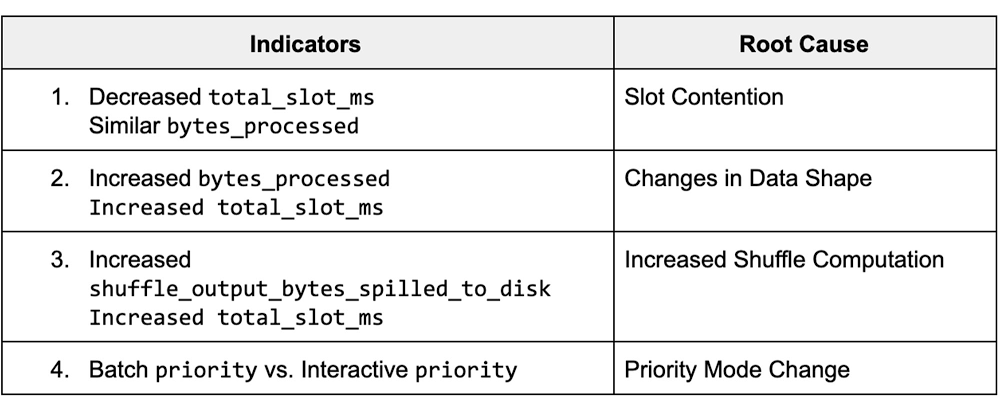
The info from these views shows varied job statistics that have an effect on question efficiency. By understanding how the statistics from these fields diverse between completely different runs, we are able to determine the potential root causes for slowness, and steps for mitigation. The desk under summarizes the highest key indicators and the corresponding root trigger.
Job Comparability Dashboard
We’ll start by navigating to our public dashboard, which exhibits Google’s take a look at INFORMATION_SCHEMA knowledge to match the efficiency of jobs.
Let’s stroll by every of those root causes and learn to diagnose them through the use of the Programs Tables dashboard. To start, we’ll enter each a sluggish and quick job ID to match job statistics.

1. Slot Competition
Background
Slot rivalry can happen when the demand for slots is larger than the allotted quantity for the reservation. Since tasks/jobs share slots equally inside a reservation, because of this if extra tasks/jobs are lively, then every mission/job will obtain much less slots. To diagnose slot rivalry, you should utilize the INFORMATION_SCHEMA timeline views to research concurrency at each the project-level and the job-level.
Monitoring
We’ll take a look at a couple of completely different eventualities for this use case: first, we’ll confirm that the “total_slot_ms” diverse between the queries. If one job ran slower and used considerably much less slots than the opposite, then this often means it had entry to much less sources as a result of it was competing towards different lively jobs. To confirm this assumption, we’ll have to dive into concurrency:
1. Concurrent Tasks: If the job is inside a reservation, we’ll use the JOBS_BY_ORGANIZATION timeline view to compute the lively variety of tasks throughout each the sluggish and quick queries. Question jobs will decelerate because the variety of lively tasks throughout the reservation will increase. Represented as an equation, if there are Y tasks in a reservation, every mission receives 1/Y of the reservation’s complete slots. That is because of the BigQuery honest scheduling algorithm described above.
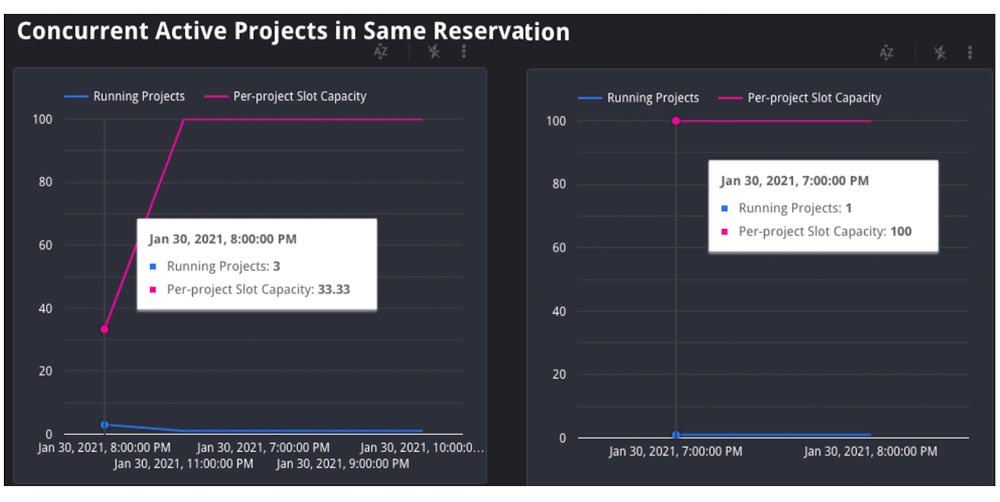
Within the graph above, we are able to see that when the job on the left started, there have been three complete lively tasks on the identical time, competing for the reservation’s 35 slots. On this situation, every mission acquired 1/three of the reservation’s 35 slots, or about 12 slots. Nevertheless, within the graph on the suitable, we are able to see that there was just one lively mission, which means that particular job acquired all 35 slots.
2. Concurrent Jobs: Equally, we are able to additionally use the JOBS_BY_PROJECT timeline view to grasp the conduct inside the mission itself. If the variety of concurrent jobs is excessive, this implies all the jobs are competing for sources on the identical time. For the reason that demand is excessive, there are much less obtainable slot sources for every job, which means that the question could take slower than ordinary to finish.
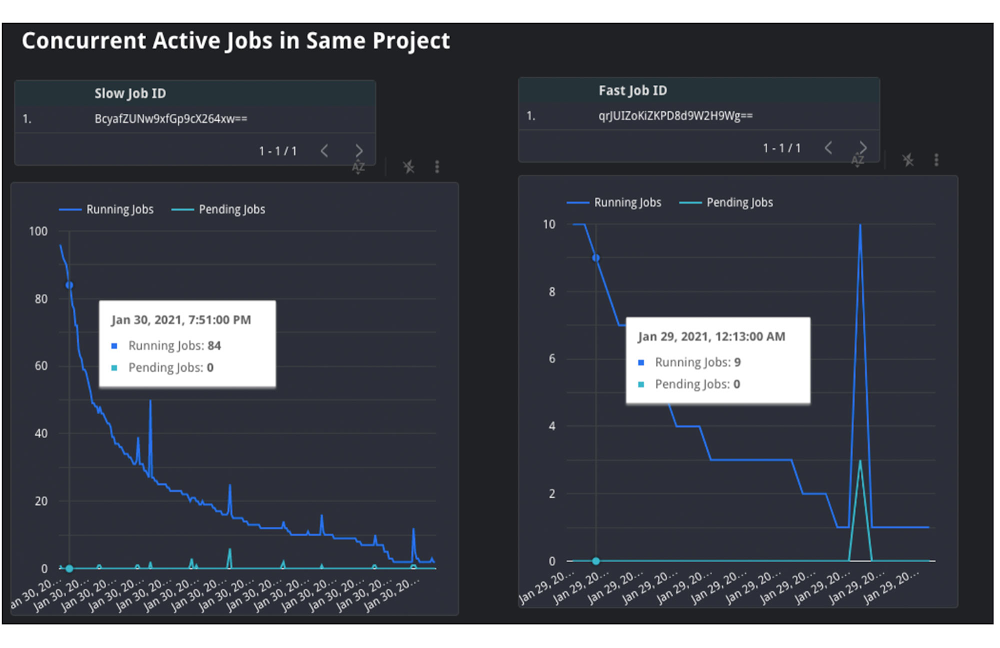
Within the graph above, you’ll be able to see that the sluggish question, on the left, was competing with between 20 and 100 different jobs over the course execution. Nevertheless, the quick job, on the suitable, was solely competing with between 4 and 26 different jobs over its execution. This exhibits that the quantity of lively jobs similtaneously the job on the left was possible the explanation for the sluggish velocity and lengthy period.
three. Lastly, we are able to additionally attempt to perceive if idle slots have been used. Idle slots are an non-compulsory configuration for reservations. In case you allow them, you enable any obtainable slots to be shared between reservations, in order that unused slots usually are not wasted by non-active reservations. If a job had entry to idle slots when it first ran, it possible would have executed sooner than with out them, as the additional idle slots, coupled with the reservation’s regular allocation, gave it extra sources to execute. Sadly, we are able to’t view this in the present day in INFORMATION_SCHEMA. Nevertheless, we are able to make a finest guess about if idle slots have been obtainable by take a look at the reservation’s utilization share throughout execution; if utilization for the reservation was larger than 100%, because of this it should have borrowed slots from one other reservation.
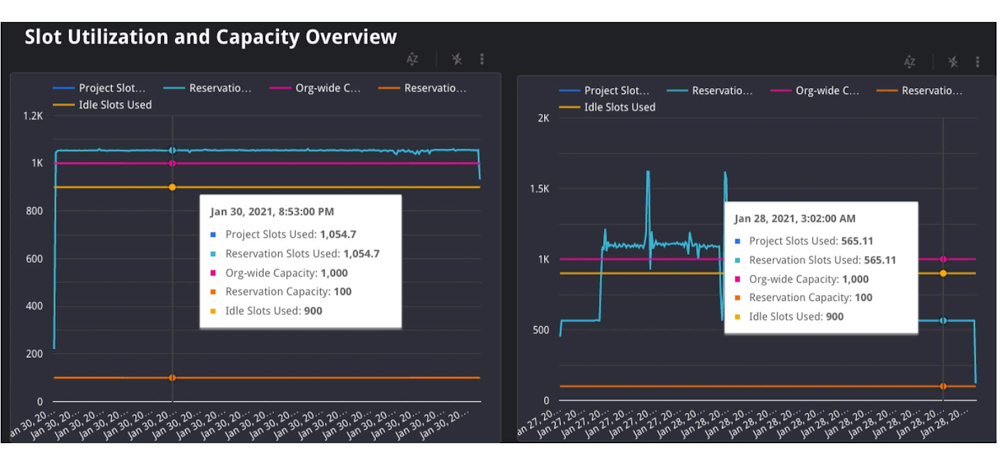
Within the graph above, you’ll be able to see each the group and reservation’s capability, in addition to the quantity of slots utilized by the reservation. On this case, the roles in the identical reservation on the left used 1,055 slots, which is greater than its capability of 100.As a result of the group has a capability of 1,000, and the reservation solely has 100, it should have used 900 remaining idle slots from one other reservation within the group. Observe: in uncommon circumstances, a company could use greater than its bought capability within the occasion of migrations inside the knowledge heart or additional on-demand slots being utilized by tasks inside the group.
Mitigation Choices
If the foundation trigger is slot rivalry, then this implies you want a option to give your job entry to extra slots. You could have a couple of choices to take action:
1. Buy extra slots: That is the best choice. You should purchase a brand new dedication for slots within the reservation, which is able to assure that there are extra sources. You should purchase this in annual, month-to-month, or flex increments relying in your forecasting wants.
2. Reallocate slot proportions per reservation: If shopping for extra complete slots just isn’t an choice to your group, you’ll be able to reallocate your present slots between reservations based mostly on precedence. This may imply reassigning a specific amount of slots from reservation A to reservation B. Allocating these slots to reservation B’s task will assist jobs in reservation B full sooner than earlier than because it now has elevated capability, and reservation A’s will possible full slower.
three. Reschedule jobs to reduce concurrent jobs: In case you can’t transfer the sources between reservations, you then could possibly alter the timing of jobs to maximise the utilization of your reservation over time. Transfer non-urgent jobs to off-peak hours, reminiscent of weekends or in a single day. In case you can unfold the load over completely different instances of day, this can cut back the competitors for slots at peak hours. You’ll be able to look at the Hourly Utilization report to higher perceive traits.
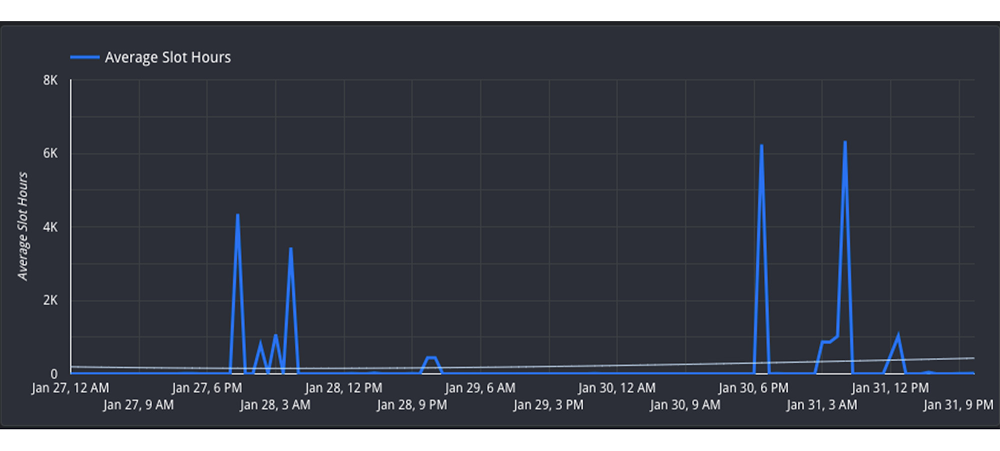
On this view, you’ll be able to see that the reservation is lively between 4PM-8AM UTC on each January 27 and January 30. Nevertheless, the hours between 8AM-4PM UTC are much less utilized and subsequently will be thought-about “off peak”. It might be useful to attempt to reschedule the roles to be between 8AM-4PM to permit for extra distributed useful resource utilization.
2. Modifications in Information Form
Background
One other potential motive for sudden modifications in period could possibly be the underlying knowledge itself. This will occur in two methods: both the underlying supply tables include extra knowledge than prior runs, or intermediate subqueries could lead to extra knowledge being processed because the question executes.
Monitoring
First, you’ll be able to verify if the “complete bytes processed” discipline elevated from modifications within the question. If this elevated from the quick job to the sluggish job, then this implies the job needed to course of greater than ordinary. We will verify the foundation trigger in two methods:
1. If it elevated, then this implies general the question had extra knowledge to research. Confirm that the question textual content itself didn’t change; if a JOIN moved, or if a WHERE clause up to date its filtering, this could imply extra knowledge to learn.
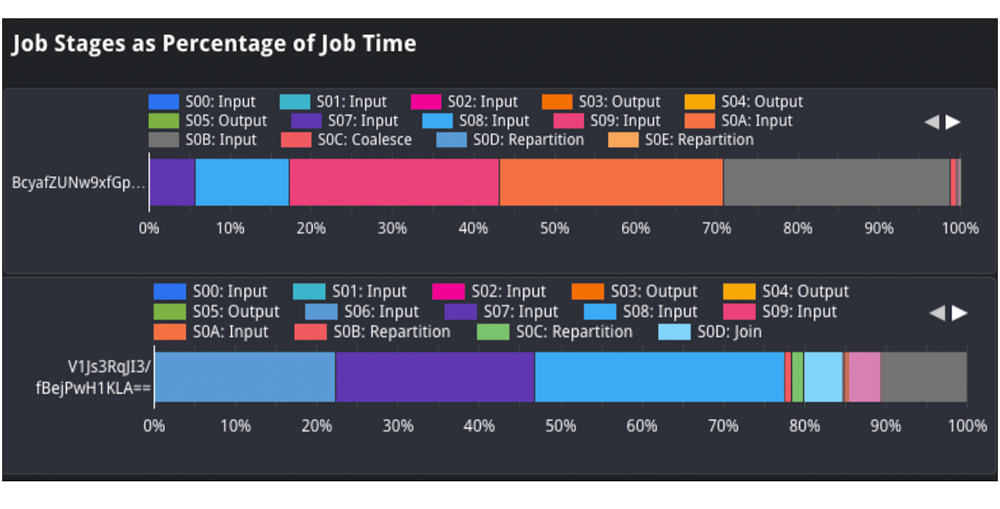
Within the job phases as a share of job time view, we are able to analyze the form of the enter knowledge and evaluate it between queries. For instance, we are able to evaluate the “enter” share between the sluggish and quick job, which signifies how a lot knowledge was ingested. If we look at stage 2 enter, we see it took about 25% of processing time within the job on high. Nevertheless, within the job on the underside, it took about 1-2% of processing time. This means that the supply desk ingested at stage 2 possible grew, and will clarify why the job was slower.
2. We also needs to analyze the scale of the supply tables for the question. We’ll view the referenced_tables discipline as this can present all supply tables utilized by the question. We’ll evaluate the scale of every supply knowledge on the time of the question. If the scale elevated considerably, then that is possible a motive for slowness.
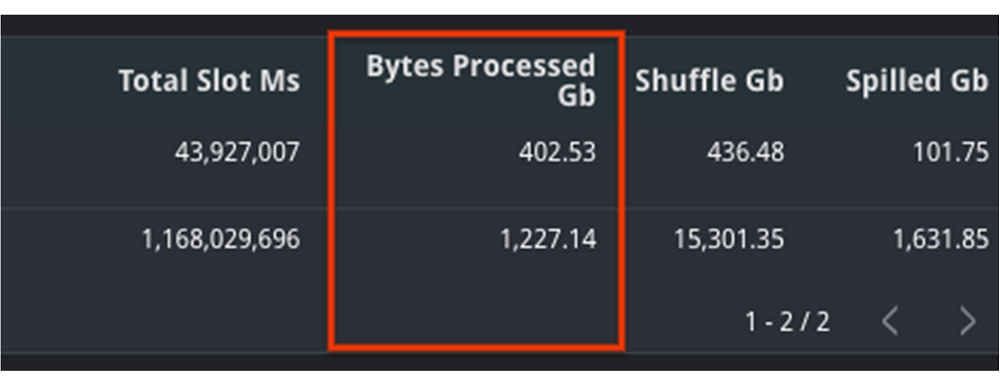
On this instance, we are able to see that the quantity of bytes processed elevated considerably between jobs. That is possible the explanation for slowness. We will moreover confirm this with the truth that total_slot_ms elevated, which means that it had extra slots obtainable and nonetheless took longer.
Mitigation Choices
1. Clustering: Relying in your question, you could possibly use clustering to assist enhance the efficiency. Clustering will assist queries that use filtering and aggregation, as clustering types related columns collectively. This may cut back the quantity of knowledge scanned, however will solely present massive efficiency enhancements for tables larger than a gigabyte.
2. Decrease enter knowledge: To be able to mitigate this, attempt to discover out if there may be any option to optimize the question textual content to learn solely the required knowledge. Some choices to do that embody filtering early, reminiscent of including WHERE statements at first of the question to filter out pointless information or modify the SELECT assertion to solely embody the wanted columns, quite than a SELECT *.
three. Denormalize your knowledge: in case your knowledge includes parent-child or different hierarchical relationships, attempt to use nested and repeated fields in your schema. This permits BigQuery to parallelize execution and full sooner.
three. Elevated Shuffle Reminiscence
Background
Whereas jobs use slots for the compute sources, additionally they use shuffle reminiscence to maintain observe of the job’s state to transition knowledge between execution phases because the question progresses. This shared state in the end permits for parallel processing and optimizations of your question. Your shuffle reminiscence is correlated to the quantity of slots obtainable in a reservation.
As a result of shuffle is an in-memory operation, there may be solely a finite quantity of reminiscence obtainable for every stage of the question. If there may be an excessive amount of knowledge being processed at any cut-off date, reminiscent of a big be a part of, or if there’s a excessive knowledge skew between joins, it’s potential that a stage can develop into too intensive and exceed its shuffle reminiscence quota. At this level, shuffle bytes will spill to disk, which causes queries to decelerate.
Monitoring
To diagnose this, it’s best to take a look at two completely different metrics: each the shuffle reminiscence consumed by the job in addition to the slots used. Your shuffle reminiscence quota is tied to your slot capability, so a steady quantity of slots alongside a rise within the quantity of shuffle spilled to disk would point out that this could possibly be the foundation trigger.
Examine the mixture shuffle_output_bytes_spilled_to_disk from the TIMELINE view. A rise in bytes spilled to disk means that the roles are caught, quite than operating quick sufficient to finish on time.
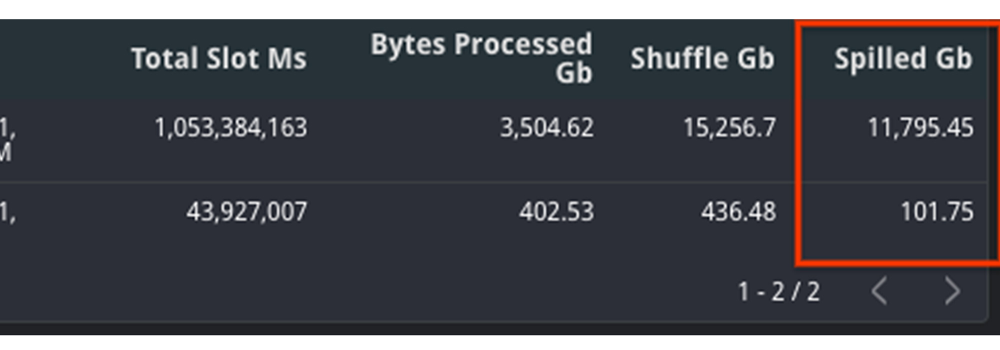
On this instance, you’ll be able to see that the quantity of knowledge spilled to disk is considerably larger for the sluggish question. Moreover, the whole slots have elevated as properly, which means that it had extra sources obtainable and nonetheless took longer to finish.
Mitigation Choices
A rise of bytes spilled to disk signifies that BigQuery is having hassle sustaining state between question execution phases. Due to this, it’s best to attempt to optimize the question plan itself in order that much less bytes are handed between phases.
1. Filter knowledge early: Scale back the quantity of knowledge ingested by the question by filtering early with WHERE clauses and earlier than becoming a member of tables. Moreover, guarantee that you’re not utilizing SELECT *, and are solely choosing the mandatory columns.
2. Use partitioned tables over sharded tables: In case you’re utilizing sharded tables, attempt to use partitioned tables as a substitute. Sharded tables require BigQuery to keep up a replica of the schema and metadata, along with sustaining state, which may lower efficiency.
three. Enhance slots: As a result of the quantity of shuffle reminiscence is correlated to the quantity of slots, rising the quantity of slots may also help alleviate the quantity of reminiscence spilled to disk. As talked about within the Slot Competition mitigation steps, you are able to do so by way of buying a brand new dedication or reallocating extra slots to this explicit reservation.
four. Rewrite the question: As a result of the job can’t keep the state of knowledge between phases, your different choice is to rewrite the question to enhance efficiency. This may imply making an attempt to optimize towards SQL anti-patterns by lowering the variety of subqueries or eliminating CROSS JOINs. Moreover, you’ll be able to think about breaking the question up into quite a few chained queries and storing the output knowledge between queries into non permanent tables.
four. Precedence Mode
Background
In BigQuery, queries can execute in both of two strategies of precedence: interactive or batch. By default, BigQuery executes jobs in interactive mode, which means that it executes as quickly as sources can be found.
Monitoring
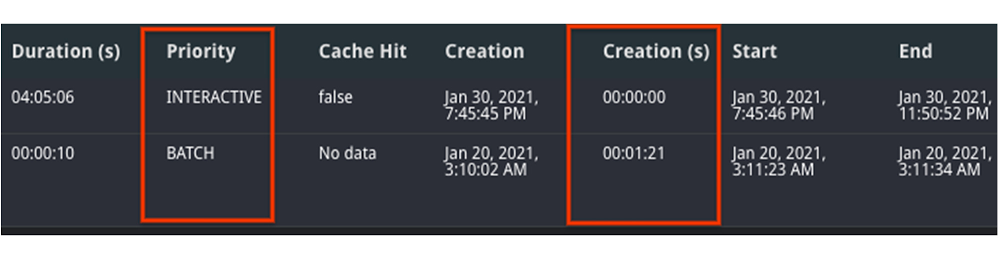
1. Yow will discover your mode by inspecting the precedence column of the job. A job could run slower as a batch job than as an interactive job.
2. If each jobs have been run in batch mode, evaluate the state over time. It’s potential that one job was queuing within the PENDING state for a very long time, which means that there weren’t sources obtainable to run at creation time. You’ll be able to confirm this by trying on the Creation (s) time within the desk, as this shows how lengthy it was queued earlier than beginning.
Mitigation
1. Perceive the relative priorities and SLOs for the roles. In case your group has much less vital jobs, attempt to run them in batch mode, with the intention to let extra vital jobs end first. The batch jobs could queue up and wait to run till interactive jobs end and/or idle slots can be found.
2. Determine the concurrency quota distinction between batch and interactive jobs. Batch and interactive jobs have completely different concurrency quotas. By default, tasks are restricted to 100 concurrent interactive queries. You’ll be able to contact your gross sales group or help to look into elevating this restrict, if vital. Batch jobs can even be queued, as vital, to make sure that interactive jobs end earlier than the 6-hour timeout window.
three. Much like the mitigations introduced in slot rivalry, you’ll be able to think about both buying extra slots for the reservation or rescheduling your job at off-peak hours when there may be much less demand for sources.
As you’ll be able to see, there are various methods to troubleshoot your question jobs based mostly on the info from INFORMATION_SCHEMA. Strive it out your self right here with any two job IDs.
[ad_2]
Source link




