
[ad_1]

|
AWS provides you the elements that it is advisable to construct methods which are extremely dependable: a number of Areas (every with a number of Availability Zones), Amazon CloudWatch (metrics, monitoring, and alarms), Auto Scaling, Load Balancing, a number of types of cross-region replication, and much extra. While you put them collectively according to the steerage offered within the Nicely-Architected Framework, your methods ought to be capable to maintain going even when particular person elements fail.
Nonetheless, you gained’t know that that is certainly the case till you carry out the best sorts of checks. The comparatively new subject of Chaos Engineering (primarily based on pioneering work performed by “Grasp of Catastrophe” Jesse Robbins within the early days of Amazon.com, after which taken into excessive gear by the Netflix Chaos Monkey) focuses on including stress to an software by creating disruptive occasions, observing how the system responds, and implementing enhancements. Along with declaring the areas for enhancements, Chaos Engineering helps to find blind spots that deserve extra monitoring & alarming, uncovers once-hidden implementation points, and offers you a chance to enhance your operational expertise with an eye fixed towards bettering restoration time. To be taught much more about this matter, begin with Chaos Engineering – Half 1 by my colleague Adrian Hornsby.
Introducing AWS Fault Injection Simulator (FIS)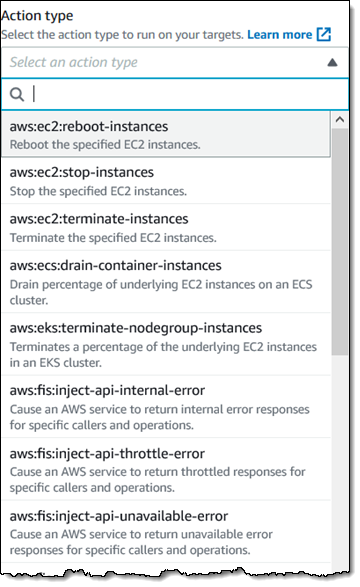 In the present day we’re introducing AWS Fault Injection Simulator (FIS). This new service will assist you to to carry out managed experiments in your AWS workloads by injecting faults and letting you see what occurs. You’ll learn the way your system reacts to numerous varieties of faults and you should have a greater understanding of failure modes. You can begin by operating experiments in pre-production environments after which step as much as operating them as a part of your CI/CD workflow and in the end in your manufacturing setting.
In the present day we’re introducing AWS Fault Injection Simulator (FIS). This new service will assist you to to carry out managed experiments in your AWS workloads by injecting faults and letting you see what occurs. You’ll learn the way your system reacts to numerous varieties of faults and you should have a greater understanding of failure modes. You can begin by operating experiments in pre-production environments after which step as much as operating them as a part of your CI/CD workflow and in the end in your manufacturing setting.
Every AWS Fault Injection Simulator (FIS) experiment targets a selected set of AWS sources and performs a set of actions on them. We’re launching with help for Amazon Elastic Compute Cloud (EC2), Amazon Elastic Container Service (ECS), Amazon Elastic Kubernetes Service (EKS), and Amazon Relational Database Service (RDS), with extra sources and actions on the roadmap for 2021. You may choose the goal sources by kind, tag, ARN, or by querying for particular attributes. You even have the flexibility to cease the experiment if a number of cease situations (as outlined by CloudWatch Alarms) are met. This lets you shortly terminate the experiment if it has an sudden affect on a vital enterprise or operational metric.
Utilizing AWS Fault Injection Simulator (FIS)
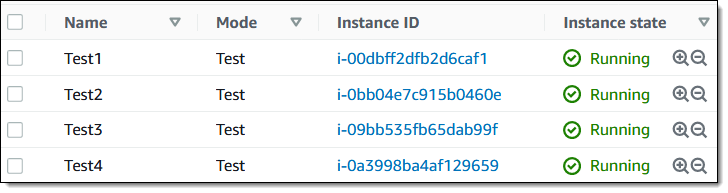
Let’s create an experiment template and run an experiment! I’ll use 4 EC2 cases, all tagged with a Mode of Check:
I open the FIS Console and click on Create experiment template to get began:

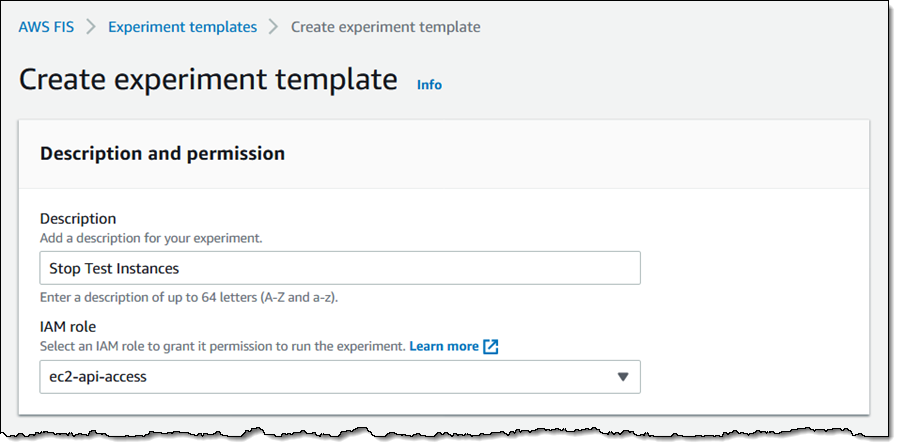
I enter a Description and select an IAM Position. The position grants permission which are wanted for FIS to carry out actions on the chosen sources in order that it may well carry out the experiment:
Subsequent, I outline the motion(s) that comprise the experiment. I click on on Add motion to get began:
Then I outline my first motion — I need to cease a few of my EC2 cases (tagged with a Mode of Check for this instance) for 5 minutes, and guarantee that my system stays operating. I make my selections and click on Save:
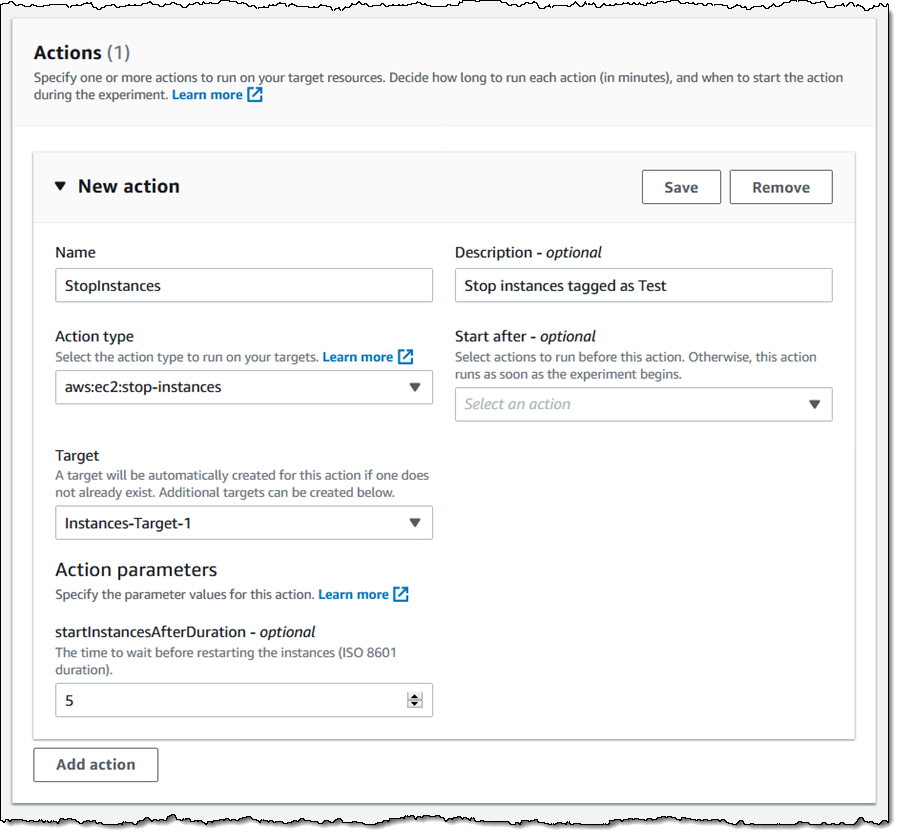
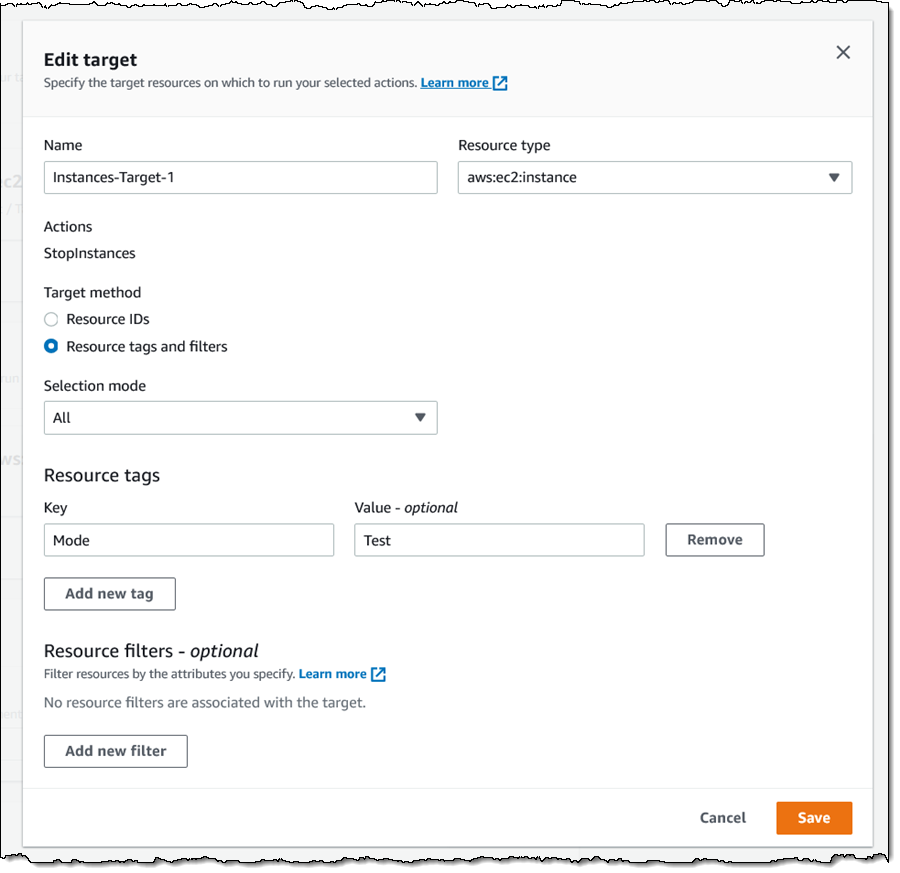
Subsequent, I select the goal sources (EC2 cases on this case) for the experiment. I click on Add goal, give my goal a reputation, and point out that it consists of all of my EC2 cases (within the present area) which have tag Mode with worth Check. I may select a random occasion or a proportion of all of cases that match the tag or the Useful resource filter. Once more, I make my selections and click on Save:
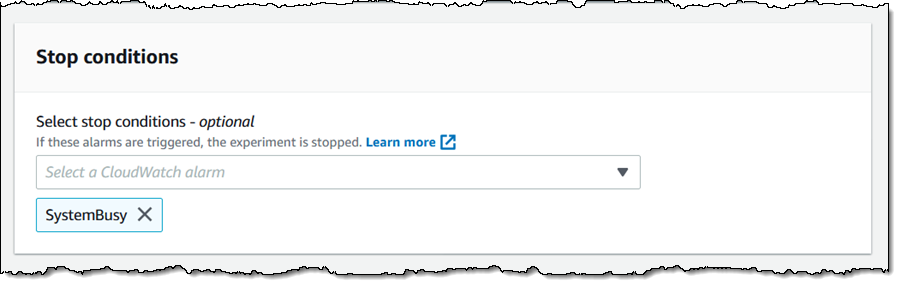
I can select a number of cease situations (CloudWatch Alarms) for the experiment. If an alarm is triggered, the experiment stops. This can be a security mechanism that enables me to guarantee that an area failure doesn’t cascade right into a full-scale outage.
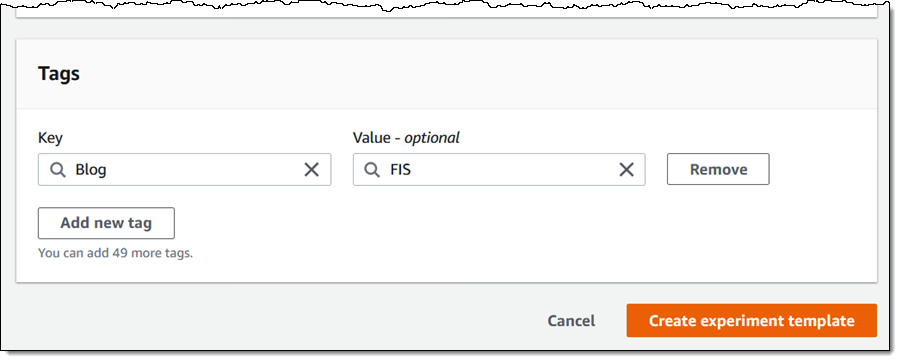
Lastly, I tag my experiment and click on Create experiment template:
My template is prepared for use as the idea for an experiment:
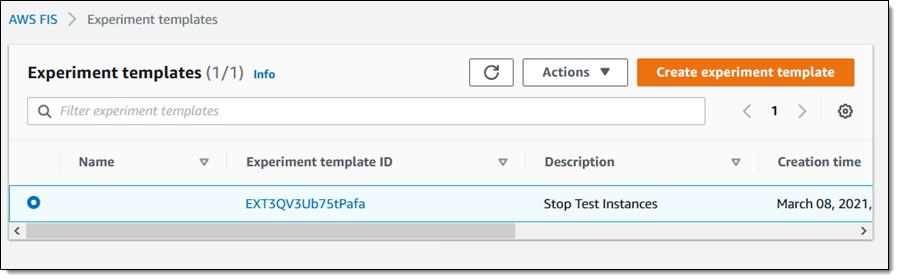
To run an experiment, I choose a template and select Begin experiment from the Actions menu:
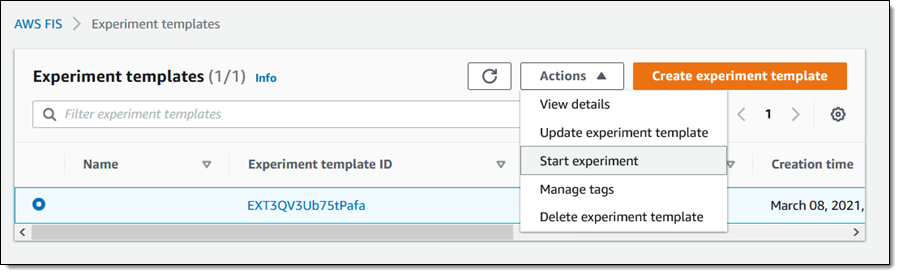
Then I click on Begin experiment (I additionally determined so as to add a tag):
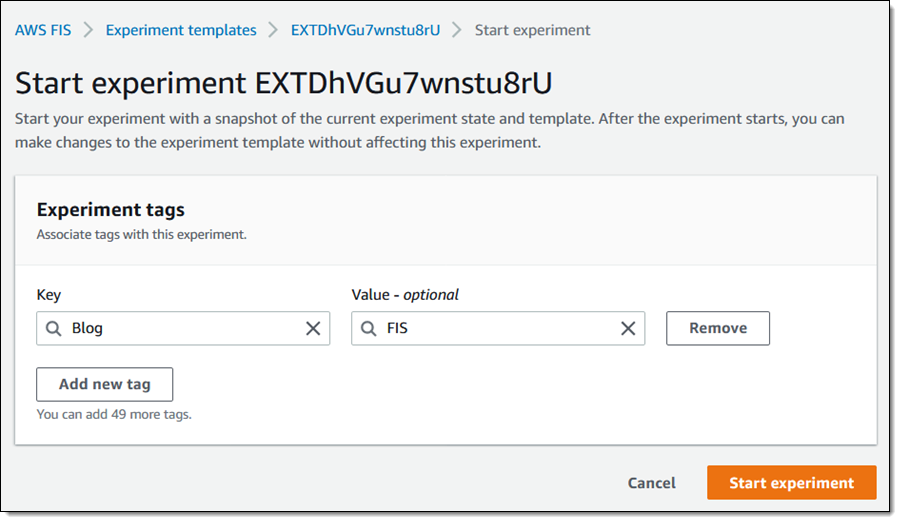
I verify my intent, since it may well have an effect on my AWS sources:
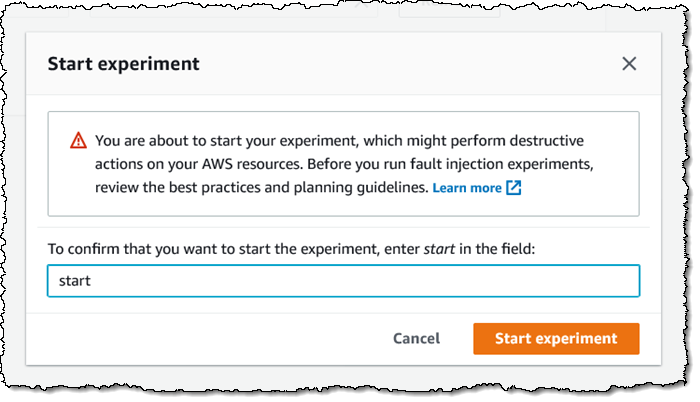
My experiment begins to run, and I can watch the actions:
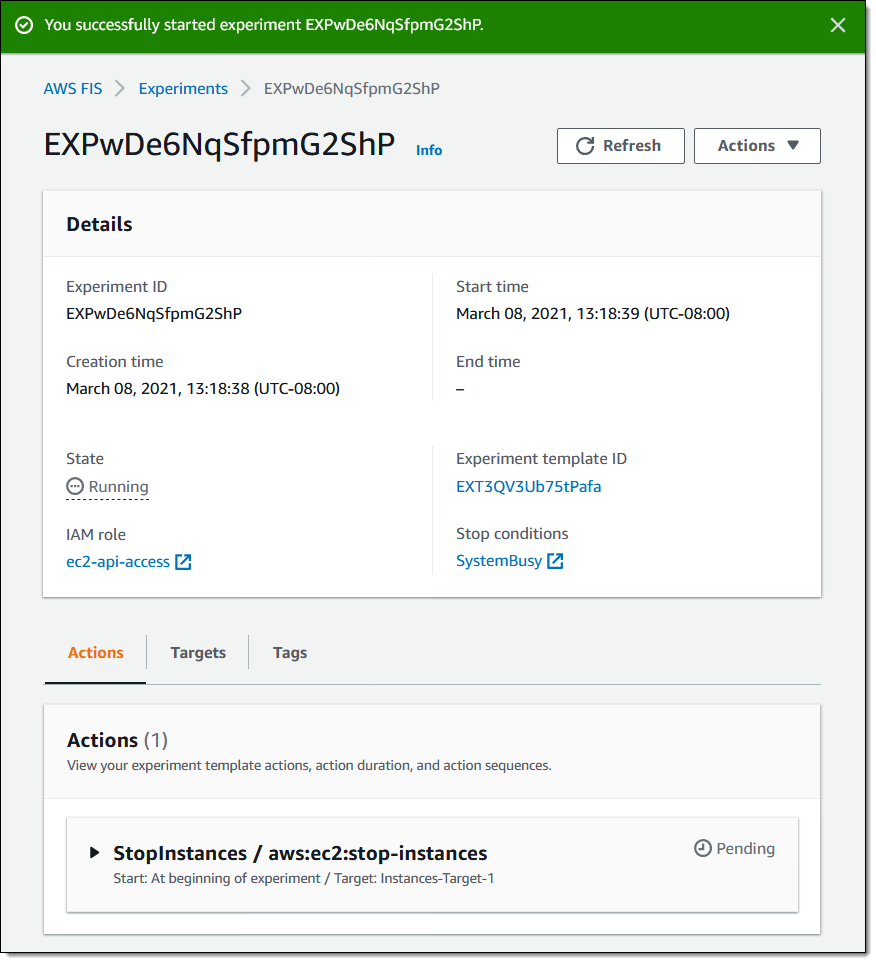
As anticipated, the goal cases are stopped:
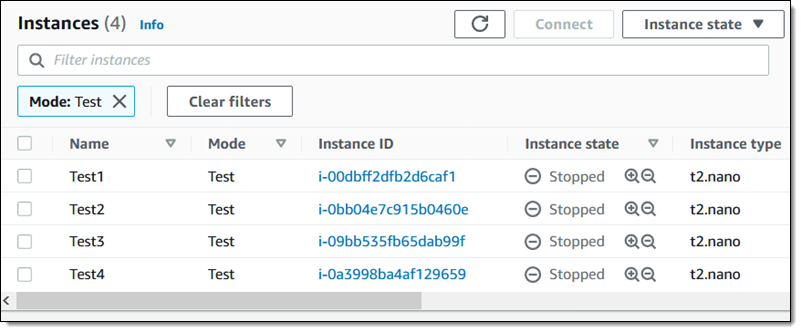
My experiment runs to conclusion, and I now know that my system can carry on going if these cases are stopped:
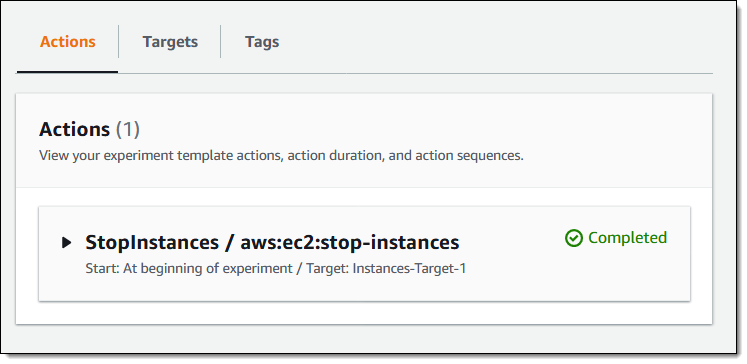
I may create, run, and evaluate experiments utilizing the FIS API and the FIS CLI. You could possibly, for instance, run totally different experiments in opposition to the identical goal, or run the identical experiment in opposition to totally different targets.
Obtainable Now
AWS Fault Injection Simulator (FIS) is out there now and you should use it to run managed experiments in the present day. It’s out there in the entire industrial AWS Areas in the present day besides Asia Pacific (Osaka) and the 2 Areas in China. The remaining three industrial areas are on the roadmap.
Pricing is predicated on the variety of minutes that your actions run; learn the FIS Pricing web page to be taught extra.
We’ll be including help for extra companies and extra actions all through 2021, so keep tuned!
— Jeff;
[ad_2]
Source link





