[ad_1]
This can be a visitor publish from ZS. In their very own phrases, “ZS is an expert companies agency that works carefully with firms to assist develop and ship merchandise and options that drive buyer worth and firm outcomes. ZS engagements contain a mix of expertise, consulting, analytics, and operations, and are focused towards bettering the industrial expertise for shoppers.”
This weblog is in regards to the approaches evaluated and ultimately chosen for ZS’s cloud transformation journey particularly for adoption of Amazon Redshift from prior Teradata based mostly knowledge warehousing resolution.
ZS, an expert companies agency that works aspect by aspect with firms to assist develop and ship merchandise that drive buyer worth and firm outcomes. We leverage our in depth trade experience, modern analytics, expertise and techniques to create options that work in the true world. With greater than 35 years of expertise and over 7,500 ZS workers in 24 workplaces worldwide, we’re passionately dedicated to serving to firms and their clients thrive.
ZS used Teradata as the first knowledge warehouse resolution for a number of years. Half attributable to excessive possession and working value, we began on the lookout for an optimum resolution which might present scaling flexibility, decrease upkeep legal responsibility and entry accelerated innovation within the trade. This was achievable via options hosted on a cloud platform like AWS which ZS has already been utilizing for quite a few enterprise workloads over time.
Issues for migration
Following have been the three key areas which have been essential for our Teradata to Amazon Redshift migration planning.
Desk buildings
The method included migrating the database schema first after which migrating the precise knowledge from the databases. The schema on Amazon Redshift wanted to be prepared earlier than loading the info from Amazon Easy Storage Service (Amazon S3).
AWS Schema Conversion Instrument (SCT) helped in migrating desk buildings to Amazon Redshift, which transformed the info varieties used for columns in Teradata tables into the corresponding Amazon Redshift knowledge varieties. The AWS SCT device additionally helped convert the desk definition from Teradata to Amazon Redshift to incorporate the suitable keys, such because the Distribution Key/Type Key. The best way to use the AWS SCT has been defined within the later sections of this weblog
Database objects and knowledge varieties
Teradata databases can maintain quite a lot of database objects other than tables like views, saved procedures, macros, Person Outlined Capabilities (UDF) and so forth. The information kinds of the columns utilized in Teradata tables wanted to be transformed into the suitable knowledge varieties on Amazon Redshift. For different objects like views, saved procedures, the definitions from Teradata have been exported and contemporary objects have been created in Amazon Redshift with applicable modifications within the new definitions. The AWS SCT can assist in figuring out the objects that want rework whereas migrating to Amazon Redshift.
Transferring knowledge to AWS
Third and one of many main concerns was migrating the precise knowledge to AWS. ZS’s use instances and isolation necessities have been such that neither was Direct join used normally nor have been all AWS VPCs related to company / on-premises community by way of VPN Tunnels. Knowledge as soon as exported out of Teradata will get uncompressed and expands roughly 4x leading to requirement for knowledge storage on native staging servers. Every ZS shopper workload had its respective warehouse on supply and vacation spot which additionally different in dimension and had respective isolate change administration timelines. Given these concerns we designed two use case particular approaches for transferring the exported knowledge from the Teradata database to Amazon S3:
- AWS Snowball – For databases bigger than 4TB, we selected to switch the info utilizing AWS Snowball. As soon as the info was exported out of Teradata it was pushed to AWS Snowball periodically in batches. Leading to optimum use of the space for storing on the staging servers.
- AWS CLI add – For databases smaller than 4TB, knowledge units have been exported from Teradata to staging servers and uploaded to Amazon S3 over the web utilizing AWS Command Line Interface (AWS CLI). These knowledge units have been uploaded throughout non-business hours to reduce the impression on the ZS on-premises knowledge heart community bandwidth
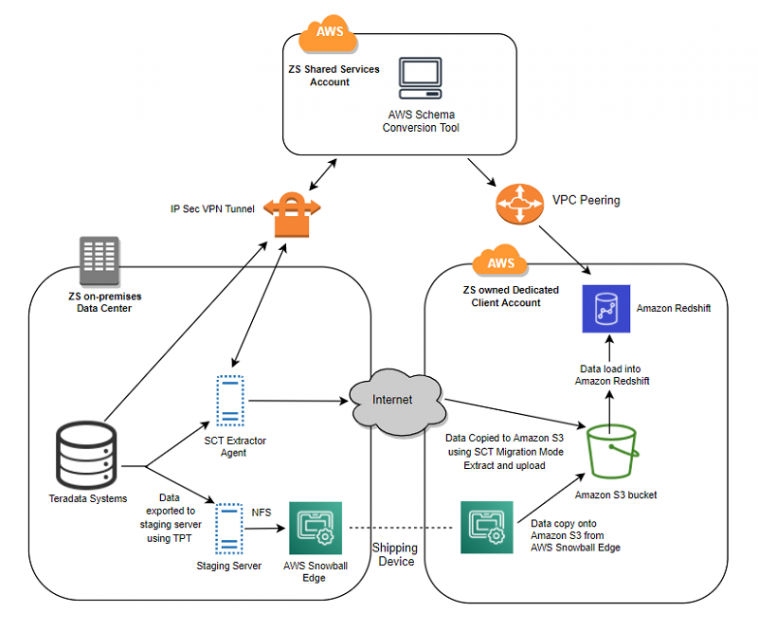
The next diagram illustrates this structure

Challenges and constraints
Exporting the info
The quantity of knowledge that needed to be exported from the Teradata programs was 100+ TB (compressed). When exported, this could doubtlessly develop to 500+TB. We would have liked an answer that would export this scale effectively. Staging such giant knowledge volumes earlier than migrating to AWS was a problem attributable to restricted on-premises SAN storage capability. The mitigation chosen was to export in batches such that the exported knowledge may very well be moved away from the staging server in a rolling trend thus holding house obtainable all through the migration. For sure datasets, attributable to volumes we additional re-compressed the exported knowledge earlier than migration to Amazon S3.
Transferring the info
ZS had 150+ databases inside our Teradata programs used throughout quite a few ZS shopper initiatives. For sure tasks, the info even needed to be transferred to the shopper’s AWS account requiring respective distinctive processes whereas expertise basis was reusable. As alluded to earlier, attributable to various dataset sizes per shopper workload, respective nuanced approaches have been designed.
Preliminary method for the answer
A cross practical staff comprising of experience throughout knowledge warehousing, storage, community, cloud native applied sciences, enterprise was fashioned at ZS which was additionally supported by AWS specialists introduced in by way of ZS’s AWS Partnership.
Main focus at starting was positioned on finalizing knowledge migration approaches. One such technique that we tried was to make use of the AWS SCT to repeat the schema onto Amazon Redshift and switch the info to Amazon S3 utilizing SCT Migration mode extract and add. We additionally checked out file interface of AWS Snowball Edge to eradicate the necessity of getting native storage for migration and straight exporting the Teradata exports on AWS Snowball Edge.

Method constraints
Whereas selecting a last method, we got here throughout the next challenges:
- Knowledge export speeds have been a significant component, contemplating the massive quantity of knowledge emigrate. We adopted the Teradata Parallel Transporter (TPT) method as a result of it confirmed higher runtimes.
- Teradata holds as much as 4X compressed knowledge, which will get uncompressed publish export. Holding such giant datasets on a staging server was not possible attributable to storage constraints.
- AWS Snowball Edge was evaluated as a substitute of AWS Snowball to check the benefits of attaching it as a direct NFS to staging servers. Nonetheless, since most file dimension supported by snowball edge NFS interface is 150 GB, we determined to proceed with AWS Snowball.
TPT scripts technique
Teradata Parallel Transporter (TPT) scripts have been leveraged to export the info because it offered sooner export speeds from Teradata servers in comparison with alternate options. We ready the Teradata Parallel Transporter (TPT) scripts and launched these via Linux servers. Earlier than beginning the export, we had to make sure that sufficient free house was obtainable on the server(s) to accommodate the export dumps.
Some great benefits of utilizing TPT scripts to export knowledge from Teradata tables have been as follows:
- Parallel processing to export knowledge, which offered sooner runtimes
- Exporting different knowledge varieties into textual content format, which may very well be loaded into Amazon Redshift
Then the info was exported on the identical servers the place the TPT scripts have been run. From right here the info was copied both to the Amazon S3 bucket via the AWS CLI that was put in on the identical server or to the Snowball machine.
Ultimate structure
The hybrid cloud structure we zeroed in on is depicted in image beneath comprising of ZS’s on-premises knowledge heart internet hosting Teradata equipment, AWS vacation spot environments and middleman staging in addition to delivery and knowledge switch networks. AWS SCT was leveraged for Schema migration and TPT exports for the info migration. The TPT export scripts have been executed on the staging servers and the info was exported onto shared storage which was connected to staging servers. After the exports have been accomplished the info was copied to AWS S3 utilizing both AWS CLI for S3 or was pushed to AWS Snowball relying on the info dimension. The Snowball machine was configured inside the similar community because the staging servers to make sure optimum switch latency. As soon as knowledge was copied utterly onto AWS Snowball, it was shipped to AWS the place knowledge was transferred into the corresponding Amazon S3 bucket. On the AWS aspect, we had the S3 bucket for the corresponding Amazon Redshift cluster that held the info earlier than loading into it.

Exporting the info
The TPT script may be very efficient when exporting enormous quantities of knowledge from the proprietary Teradata programs. You may put together and deploy export scripts on a server inside the similar community because the Teradata equipment, which allows excessive export speeds.
The TPT export script is a mix of 1) Declaration part 2) Loop with built-in instructions. Export dump with logs are generated as outputs.
Declaration part
The declaration part is the place we initialize all of the parameters, just like the system identifier often called the tdpid, login person title, and delimiter which are used within the output recordsdata. See the next code that units up shell variables:
Loop with built-in instructions:
The values for the required variables have been handed from three enter recordsdata:
- <databasename>.<tablename>
- Definition of the TPT export operator
- Job variables file (this file will get eliminated on the finish of export)
See the next shell script that makes use of shell and TPT utility instructions:
Export dump and logs
The information exported from the Teradata system via the TPT scripts was positioned on the staging server. To make sure the standard of the exported knowledge, we verified that the file counts within the log file, created through the TPT export, matched with the desk row counts.

Desk row depend in Teradata

TPT exported dataset row depend
The TPT scripts generated one file for each Teradata desk. The file format of those recordsdata was textual content with the .dat extension. See the next screenshot.

You may optimize knowledge loading into Amazon Redshift tables by splitting the corresponding file (dataset) into subsets of equal sizes. The variety of such subsets ought to ideally be equal to or a a number of of the variety of slices for the Amazon Redshift node kind configured within the cluster. We selected to separate the TPT output recordsdata utilizing the Linux break up command on the TPT server:
‘break up -C 20m --numeric-suffixes input_filename output_prefix’
For extra info effectively loading the Amazon Redshift tables, see Prime eight Finest Practices for Excessive-Efficiency ETL Processing Utilizing Amazon Redshift and Finest Practices for Micro-Batch Loading on Amazon Redshift.
Transferring knowledge to S3 buckets
ZS leveraged AWS account degree isolation for a lot of of our shopper options to align with respective compliance controls. AWS Snowball is related to a single AWS account, and to realize full shopper knowledge isolation, separate units have been shipped for every giant use case. As indicated above, we adopted two strategies to switch the info based mostly on the export dimension for every shopper workload:
- AWS CLI – Use when databases are smaller than 4TB.
- Snowball – Use when databases are larger than 4TB or when knowledge wanted to be loaded to a ZS owned Shopper Devoted account.
Transferring knowledge via the AWS CLI
Transferring the info by way of the AWS CLI contains the next steps:
- Set up and configure the AWS CLI utility on ZS on-premises Linux (staging) server
- Export datasets out from Teradata on the staging server.
- Copy the exported datasets to Amazon S3 utilizing the AWS CLI:
aws s3 cp filename.txt s3://aws-s3-bucket-name/foldername/
Transferring knowledge via Snowball
To switch the info with Snowball, full the next steps:
- Create a Snowball job on the AWS Administration Console and order the Snowball machine.
- Configure the Snowball on ZS’s on-premises knowledge heart community and set up the Snowball shopper on the staging server.
- Unlock the Snowball machine by downloading the manifest file and an unlock code from the console, as proven within the following code:
snowball begin -i XX.XX.XX.XX -m /residence/abcd/XXXXXXXXX_manifest.bin -u XXXXXXXXXXX
- Use the Snowball CLI to record the S3 Bucket related to Snowball.
snowball s3 ls
- Copy the recordsdata to Snowball:
snowball cp /location/of/the/exported/recordsdata s3://Bucket_name/Goal/
Transferring the desk construction to Amazon Redshift
There are a couple of variations within the desk definition format between Amazon Redshift and Teradata. The AWS SCT device helps convert the Teradata desk construction into an applicable Amazon Redshift desk construction.
To switch the Teradata desk construction to Amazon Redshift, full the next steps:
- Hook up with the on-premises Teradata programs and the Amazon Redshift cluster endpoint.

- Choose the precise desk from Teradata and right-click the choice Convert schema. This converts the desk definition into the Amazon Redshift equal.

- Within the Amazon Redshift part of the AWS SCT console, select Apply to database when the desk conversion is full to create the desk construction on Amazon Redshift.

Pushing the info to the tables
After you migrate the required knowledge to the suitable S3 bucket, convert the tables as per usability, and apply the tables to Amazon Redshift, you possibly can push the info to those tables by way of the COPY command:
The naming conference we used for the exported datasets was <databasename>.<tablename>. The desk buildings (DDLs) have been migrated via AWS SCT and the desk names matched the dataset names. Due to this fact, after we created the COPY instructions, we merely needed to match the goal desk title in Amazon Redshift with that of the datasets on Amazon S3. For extra details about this course of, see Utilizing the COPY command to load from Amazon S3.
Conclusion
On this weblog, we meant to convey our journey and choices evaluated earlier than zeroing on one to remodel on-premise Teradata knowledge warehouse workloads onto Amazon Redshift at scale. Course of constructed round a number of instruments together with AWS SCT, Teradata Parallel Transporter, and AWS Snowball facilitated our transformation
For extra details about AWS SCT, see Introducing AWS Schema Conversion Instrument Model 1.zero.502. For extra details about Snowball, see AWS Import/Export Snowball – Switch 1 Petabyte Per Week Utilizing Amazon-Owned Storage Home equipment.
Disclaimer: The content material and opinions on this publish are these of the third-party creator and AWS shouldn’t be accountable for the content material or accuracy of this publish.
In regards to the Authors
 Ajinkya Puranik is a Cloud Database Lead inside Cloud Centre of Excellence at ZS Associates. He has years of expertise managing, administrating, optimizing and adopting evolving knowledge warehousing options. He performed an instrumental function in ZS’s Teradata to Redshift transformation journey. His private pursuits contain cricket and touring.
Ajinkya Puranik is a Cloud Database Lead inside Cloud Centre of Excellence at ZS Associates. He has years of expertise managing, administrating, optimizing and adopting evolving knowledge warehousing options. He performed an instrumental function in ZS’s Teradata to Redshift transformation journey. His private pursuits contain cricket and touring.
 Sushant Jadhav is a Senior Cloud Administrator inside Cloud Middle of Excellence at ZS Associates. He’s a results-oriented skilled with expertise expertise predominantly within the storage and backup trade. He has labored on many migration tasks the place he helped clients migrate from on-premises to AWS. Sushant enjoys engaged on all of the AWS companies and tries to bridge the hole between expertise and enterprise. He’s all the time eager on studying new applied sciences and is all the time evolving in his function. Other than work, he enjoys taking part in soccer.
Sushant Jadhav is a Senior Cloud Administrator inside Cloud Middle of Excellence at ZS Associates. He’s a results-oriented skilled with expertise expertise predominantly within the storage and backup trade. He has labored on many migration tasks the place he helped clients migrate from on-premises to AWS. Sushant enjoys engaged on all of the AWS companies and tries to bridge the hole between expertise and enterprise. He’s all the time eager on studying new applied sciences and is all the time evolving in his function. Other than work, he enjoys taking part in soccer.
[ad_2]
Source link





