
[ad_1]

|
Immediately we’re asserting a brand new Amazon Comprehend characteristic for clever doc processing (IDP). This characteristic means that you can classify and extract entities from PDF paperwork, Microsoft Phrase information, and pictures straight from Amazon Comprehend with out you needing to extract the textual content first.
Many purchasers must course of paperwork which have a semi-structured format, like photographs of receipts that have been scanned or tax statements in PDF format. Till immediately, these prospects first wanted to preprocess these paperwork to flatten them into machine-readable textual content, which may cut back the standard of the doc context. Then they might use Amazon Comprehend to categorise and extract entities from these preprocessed information.
Now with Amazon Comprehend for IDP, prospects can course of their semi-structured paperwork, reminiscent of PDFs, docx, PNG, JPG, or TIFF photographs, in addition to plain-text paperwork, with a single API name. This new characteristic combines OCR and Amazon Comprehend’s current pure language processing (NLP) capabilities to categorise and extract entities from the paperwork. The doc classification API means that you can set up paperwork into classes or lessons, and the custom-named entity recognition API means that you can extract entities from paperwork like product codes or business-specific entities. For instance, an insurance coverage firm can now course of scanned prospects’ claims with fewer API calls. Utilizing the Amazon Comprehend entity recognition API, they will extract the shopper quantity from the claims and use the classifier API to type the declare into the totally different insurance coverage classes—dwelling, automotive, or private.
Beginning immediately, Amazon Comprehend for IDP APIs can be found for real-time inferencing of information, in addition to for asynchronous batch processing on massive doc units. This characteristic simplifies the doc processing pipeline and reduces improvement effort.
Getting Began
You should utilize Amazon Comprehend for IDP from the AWS Administration Console, AWS SDKs, or AWS Command Line Interface (CLI).
On this demo, you will note learn how to asynchronously course of a semi-structured file with a classifier. For extracting entities, the steps are totally different, and you may discover ways to do it by checking the documentation.
As a way to course of a file with a classifier, you’ll first want to coach a classifier. You may observe the steps within the Amazon Comprehend Developer Information. You must practice this classifier with plain textual content knowledge.
After you practice your classifier, you possibly can classify paperwork utilizing both asynchronous or synchronous operations. For utilizing the synchronous operation to research a single doc, that you must create an endpoint to run real-time evaluation utilizing a mannequin. You could find extra details about real-time evaluation within the documentation. For this demo, you will use the asynchronous operation, putting the paperwork to categorise in an Amazon Easy Storage Service (Amazon S3) bucket and working an evaluation batch job.
To get began classifying paperwork in batch from the console, on the Amazon Comprehend web page, go to Evaluation jobs after which Create job.

Then you possibly can configure the brand new evaluation job. First, enter a reputation and decide Customized classification and the classifier you created earlier.
Then you possibly can configure the enter knowledge. First, choose the S3 location for that knowledge. In that location, you possibly can place your PDFs, photographs, and Phrase Paperwork. Since you are processing semi-structured paperwork, that you must select One doc per file. If you wish to override Amazon Comprehend settings for extracting and parsing the doc, you possibly can configure the Superior doc enter choices.
After configuring the enter knowledge, you possibly can choose the place the output of this evaluation needs to be saved. Additionally, that you must give entry permissions for this evaluation job to learn and write on the desired Amazon S3 places, after which you’re able to create the job.

The job takes a couple of minutes to run, relying on the dimensions of the enter. When the job is prepared, you possibly can verify the output outcomes. You could find the ends in the Amazon S3 location you specified whenever you created the job.
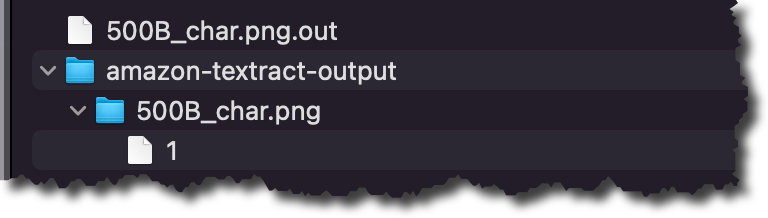
Within the outcomes folder, you will see that a .out file for every of the semi-structured information Amazon Comprehend categorised. The .out file is a JSON, during which every line represents a web page of the doc. Within the amazon-textract-output listing, you will see that a folder for every categorised file, and inside that folder, there may be one file per web page from the unique file. These web page information comprise the classification outcomes. To be taught extra in regards to the outputs of the classifications, verify the documentation web page.
Obtainable Now
You will get began classifying and extracting entities from semi-structured information like PDFs, photographs, and Phrase Paperwork asynchronously and synchronously immediately from Amazon Comprehend in all of the Areas the place Amazon Comprehend is accessible. Study extra about this new launch within the Amazon Comprehend Developer Information.
— Marcia
[ad_2]
Source link

