
The Google BigQuery Write API affords high-performance batching and streaming in a single unified API. The earlier put up on this sequence launched the BigQuery Write API. On this put up, we’ll present easy methods to stream JSON knowledge to BigQuery by utilizing the Java shopper library.
The Write API expects binary knowledge in protocol buffer format. This makes the API very environment friendly for high-throughput streaming. Nevertheless, protocol buffers will also be considerably troublesome to work with. For a lot of functions, JSON knowledge is a extra handy knowledge format. The BigQuery shopper library for Java offers the very best of each worlds, by means of the JsonStreamWriter. The JsonStreamWriter accepts knowledge within the type of JSON information, and routinely converts the JSON objects into binary protocol buffers earlier than sending them over the wire.
Let’s examine the way it works.
The state of affairs
Let’s think about a state of affairs the place you might be streaming GitHub commit knowledge to BigQuery. You need to use this knowledge to get real-time insights in regards to the commit exercise.
For the aim of the instance, we’ll learn the info from a neighborhood file. Nevertheless, you possibly can think about an utility that receives this knowledge within the type of occasions or streamed from a log file. In reality, one benefit of the Write API is that it does not matter the place the info comes from, so long as you may get it right into a appropriate format.
Every line within the supply file has the next construction:
- code_block
- [StructValue([(u’code’, u’rn “commit”:”commit ID”,rn “parent”:[“parent commit ID”],rn “creator”:”creator”,rn “committer”:”committer”,rn “commit_date”:”YYYY-MM-DDTHH:MM:SS”rn “commit_msg”: rn “repo_name”:”Repo identify”rn’), (u’language’, u”)])]
Create the vacation spot desk
First, we have to create a desk in BigQuery to obtain the streamed knowledge. There are a number of methods to create a desk in BigQuery, however one of many best is by working a CREATE TABLE question:
- code_block
- [StructValue([(u’code’, u’CREATE TABLE `myproject.mydataset.github`rn(rn commit STRING,rn parent ARRAY<STRING>,rn author STRING,rn committer STRING,rn commit_date DATETIME,rn commit_msg STRUCT<subject STRING, message STRING>,rn repo_name STRINGrn);’), (u’language’, u”)])]
Stream knowledge to the desk
Now that we’ve got a desk, we are able to write knowledge to it.
The Write API helps a number of modes, together with dedicated mode for streaming functions that require exactly-once supply, and pending mode for batch writes with stream-level transactions. For this instance, we’ll use the Write API’s default stream. The default stream is appropriate for streaming functions that require at-least-once semantics however do not want the stronger exactly-one assure. Git commits have a singular commit ID, so you possibly can determine duplication within the vacation spot desk if wanted.
Begin by initializing the JsonStreamWriter, passing within the identify of the vacation spot desk and the desk schema:
- code_block
- [StructValue([(u’code’, u’BigQuery bigquery = BigQueryOptions.getDefaultInstance().getService();rnrn // Get the schema of the destination table and convert to the equivalent BigQueryStorage type.rn Table table = bigquery.getTable(datasetName, tableName);rn Schema schema = table.getDefinition().getSchema();rn TableSchema tableSchema = BqToBqStorageSchemaConverter.convertTableSchema(schema);rnrn // Use the JSON stream writer to send records in JSON format.rn TableName parentTable = TableName.of(projectId, datasetName, tableName);rn try (JsonStreamWriter writer =rn JsonStreamWriter.newBuilder(parentTable.toString(), tableSchema).build()) {‘), (u’language’, u”)])]
Now we’re able to learn the info file and ship the info to the Write API. As a finest apply, it is best to ship the info in batches reasonably than one row at a time. Learn every JSON report right into a JSONObject and accumulate a batch of them right into a JSONArray:
- code_block
- [StructValue([(u’code’, u’BufferedReader reader = new BufferedReader(new FileReader(dataFile));rn String line = reader.readLine();rn while (line != null) {rn JSONArray jsonArr = new JSONArray();rn for (int i = 0; i < 100; i++) rn JSONObject record = new JSONObject(line);rn jsonArr.put(record);rn line = reader.readLine();rn if (line == null) rn // batch’), (u’language’, u”)])]
To write down every batch of information, name the JsonStreamWriter.append technique. This technique is asynchronous and returns an ApiFuture. For finest efficiency, do not block ready for the long run to finish. As an alternative, proceed to name append and deal with the outcome asynchronously.
- code_block
- [StructValue([(u’code’, u’ApiFuture<AppendRowsResponse> future = writer.append(jsonArr);rn ApiFutures.addCallback(rn future, new AppendCompleteCallback(), MoreExecutors.directExecutor());’), (u’language’, u”)])]
This instance registers a completion callback. Contained in the callback, you possibly can test whether or not the append succeeded:
- code_block
- [StructValue([(u’code’, u’class AppendCompleteCallback implements ApiFutureCallback<AppendRowsResponse> rnrn private static int batchCount = 0;rn private static final Object lock = new Object();rnrn public void onSuccess(AppendRowsResponse response) rnrn public void onFailure(Throwable throwable) rn System.out.format(“Error: %sn”, throwable.toString());rn rn’), (u’language’, u”)])]
Dealing with desk schema updates
BigQuery allows you to modify the schema of an current desk in sure constrained methods. For instance, you may determine so as to add a area named e-mail that accommodates the commit creator’s e-mail. Knowledge within the unique schema may have a NULL worth for this area.
If the schema adjustments if you are streaming knowledge, the Java shopper library routinely reconnects with the up to date schema. In our instance state of affairs, the applying passes the info on to the Write API with none intermediate processing. So long as the schema change is backward appropriate, the applying can proceed streaming with out interruption. After the desk schema is up to date, you can begin sending knowledge with the brand new area.
Notice: Schema updates aren’t instantly seen to the shopper library, however are detected on the order of minutes.
To test for schema adjustments programmatically, name AppendRowsResponse.hasUpdatedSchema after the append technique completes. For extra data, see Working with Schemas within the Write API documentation.
Question the info
Our knowledge is accessible for evaluation as quickly because it’s ingested into BigQuery. For instance, we are able to now run a question to search out out which days of the week have essentially the most commits:
- code_block
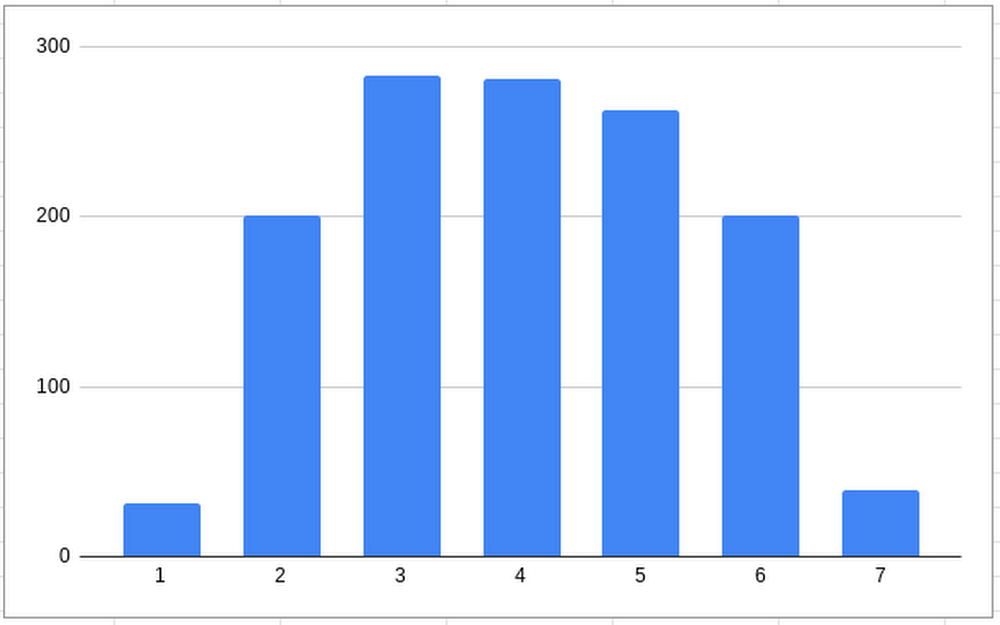
- [StructValue([(u’code’, u’SELECTrn EXTRACT(DAYOFWEEK FROM ts) AS day_of_week,rn FORMAT_DATETIME(“%A”,commit_date) AS day,rn COUNT(*) AS countrnFROM `mydataset.github`rnGROUP BY day_of_week, dayrnORDER BY count DESC;rnrn+————-+———–+——-+rn| day_of_week | day | count |rn+————-+———–+——-+rn| 3 | Tuesday | 283 |rn| 4 | Wednesday | 281 |rn| 5 | Thursday | 263 |rn| 2 | Monday | 201 |rn| 6 | Friday | 201 |rn| 7 | Saturday | 39 |rn| 1 | Sunday | 31 |rn+————-+———–+——-+’), (u’language’, u”)])]
It seems that the busiest day is Tuesday. Not surprisingly, Saturday and Sunday have the fewest commits.
Conclusion
On this article, you realized how the Java shopper library makes it simple to stream JSON knowledge into BigQuery. You’ll be able to view the entire supply code on GitHub. For extra details about the Write API, together with easy methods to use dedicated and pending modes, see the BigQuery Storage Write API documentation.








{kind=link}