
[ad_1]

|
As we speak, we’re saying two further capabilities of Amazon FSx for Lustre. First, a full bi-directional synchronization of your file programs with Amazon Easy Storage Service (Amazon S3), together with deleted recordsdata and objects. Second, the power to synchronize your file programs with a number of S3 buckets or prefixes.
Lustre is a big scale, distributed parallel file system powering the workloads of a lot of the largest supercomputers. It’s in style amongst AWS prospects for high-performance computing workloads, reminiscent of meteorology, life-science, and engineering simulations. It’s also utilized in media and leisure, in addition to the monetary providers business.
I had my first hands-on Lustre file programs once I was working for Solar Microsystems. I used to be a pre-sales engineer and labored on some offers to promote multimillion-dollar compute and storage infrastructure to monetary providers corporations. Again then, gaining access to a Lustre file system was a luxurious. It required costly compute, storage, and community . We needed to wait weeks for supply. Moreover, it required days to put in and configure a cluster.
Quick ahead to 2021, I’ll create a petabyte-scale Lustre cluster and connect the file system to compute sources operating within the AWS cloud, on-demand, and solely pay for what I take advantage of. There is no such thing as a have to learn about Storage Space Networks (SAN), Fiber Channel (FC) material, and different underlying applied sciences.
Trendy purposes use completely different storage choices for various workloads. It’s common to make use of S3 object storage for knowledge transformation, preparation, or import/export duties. Different workloads could require POSIX file-systems to entry the info. FSx for Lustre allows you to synchronize objects saved on S3 with the Lustre file system to satisfy these necessities.
Whenever you hyperlink your S3 bucket to your file system, FSx for Lustre transparently presents S3 objects as recordsdata and allows you to to write down outcomes again to S3.
Full Bi-Directional Synchronization with A number of S3 Buckets
In case your workloads require a quick, POSIX-compliant file system entry to your S3 buckets, then you should use FSx for Lustre to hyperlink your S3 buckets to a file system and hold knowledge synchronized between the file system and S3 in each instructions. Nevertheless, till in the present day, there have been a pair limitations. First, you needed to manually configure a job to export knowledge again from FSx for Lustre to S3. Second, deleted recordsdata on S3 weren’t robotically deleted from the file system. And third, an FSx for Lustre file system was synchronized with one S3 bucket solely. We’re addressing these three challenges with this launch.
Beginning in the present day, if you configure an computerized export coverage on your knowledge repository affiliation, recordsdata in your FSx for Lustre file system are robotically exported to your knowledge repository on S3. Subsequent, deleted objects on S3 at the moment are deleted from the FSx for Lustre file system. The alternative can also be obtainable: deleting recordsdata on FSx for Lustre triggers the deletion of corresponding objects on S3. Lastly, chances are you’ll now synchronize your FSx for Lustre file system with a number of S3 buckets. Every bucket has a distinct path on the root of your Lustre file system. For instance your S3 bucket logs could also be mapped to /fsx/logs and your different financial_data bucket could also be mapped to /fsx/finance.
These new capabilities are helpful when you will need to concurrently course of knowledge in S3 buckets utilizing each a file-based and an object-based workflow, in addition to share ends in close to actual time between these workflows. For instance, an utility that accesses file knowledge can achieve this by utilizing an FSx for Lustre file system linked to your S3 bucket, whereas one other utility operating on Amazon EMR could course of the identical recordsdata from S3.
Furthermore, chances are you’ll hyperlink a number of S3 buckets or prefixes to a single FSx for Lustre file system, thereby enabling a unified view throughout a number of datasets. Now you may create a single FSx for Lustre file system and simply hyperlink a number of S3 knowledge repositories (S3 buckets or prefixes). That is handy if you use a number of S3 buckets or prefixes to arrange and handle entry to your knowledge lake, entry recordsdata from a public S3 bucket (reminiscent of these a whole lot of public datasets) and write job outputs to a distinct S3 bucket, or if you wish to use a bigger FSx for Lustre file system linked to a number of S3 datasets to realize higher scale-out efficiency.
How It Works
Let’s create an FSx for Lustre file system and connect it to an Amazon Elastic Compute Cloud (Amazon EC2) occasion. I be sure that the file system and occasion are in the identical VPC subnet to reduce knowledge switch prices. The file system safety group should authorize entry from the occasion.
I open the AWS Administration Console, navigate to FSx, and choose Create file system. Then, I choose Amazon FSx for Lustre. I’m not going by all the choices to create a file system right here, you may check with the documentation to discover ways to create a file system. I be sure that Import knowledge from and export knowledge to S3 is chosen.
 It takes a couple of minutes to create the file system. As soon as the standing is ✅ Obtainable, I navigate to the Knowledge repository tab, after which choose Create knowledge repository affiliation.
It takes a couple of minutes to create the file system. As soon as the standing is ✅ Obtainable, I navigate to the Knowledge repository tab, after which choose Create knowledge repository affiliation.
I select a Knowledge Repository path (my supply S3 bucket) and a file system path (the place within the file system that bucket will likely be imported).
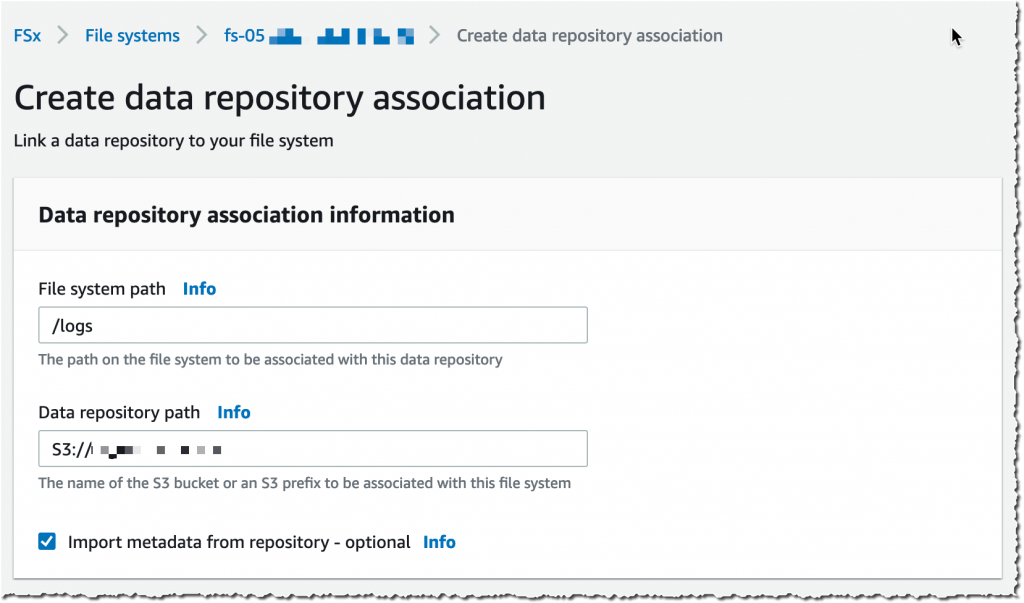
Then, I select the Import coverage and Export coverage. I’ll synchronize the creation of file/objects, their updates, and when they’re deleted. I choose Create.
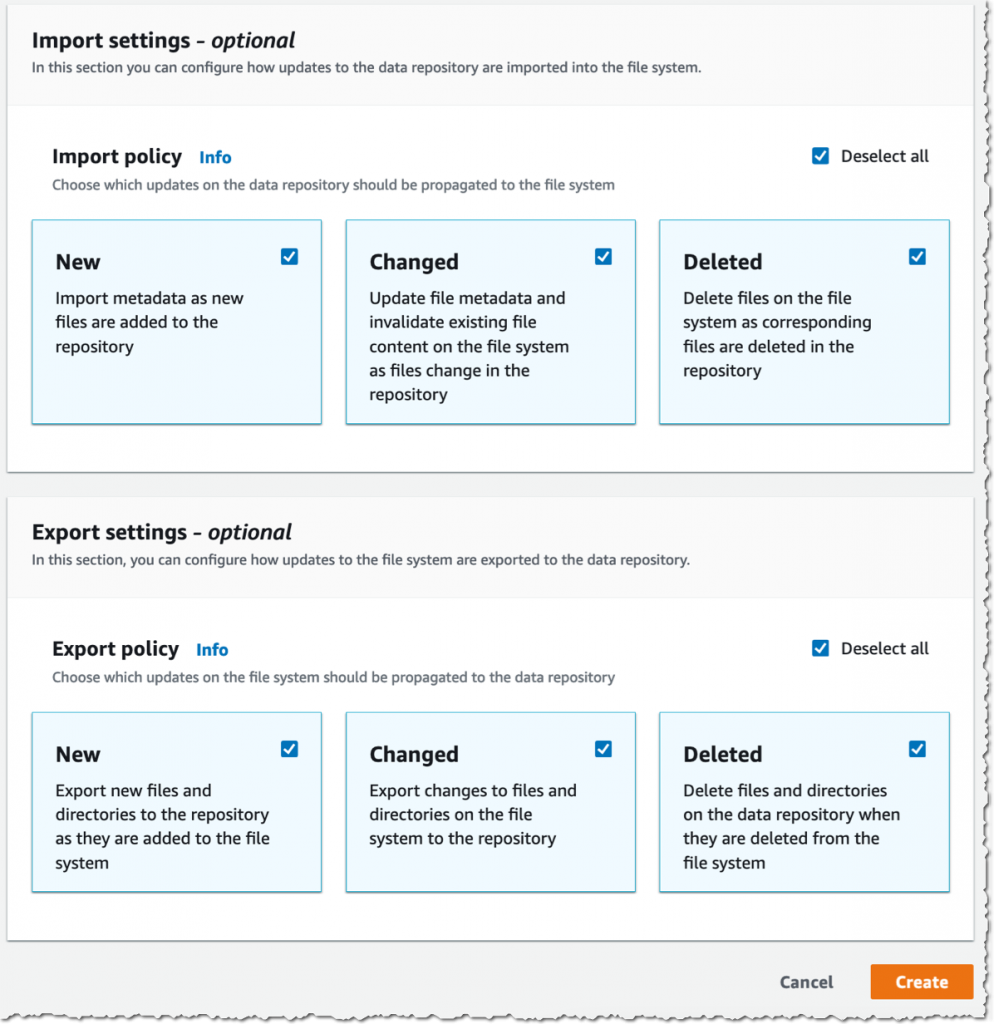
After I use computerized import, I additionally be certain to offer an S3 bucket in the identical AWS Area because the FSx for Lustre cluster. FSx for Lustre helps linking to an S3 bucket in a distinct AWS Area for computerized export and all different capabilities.
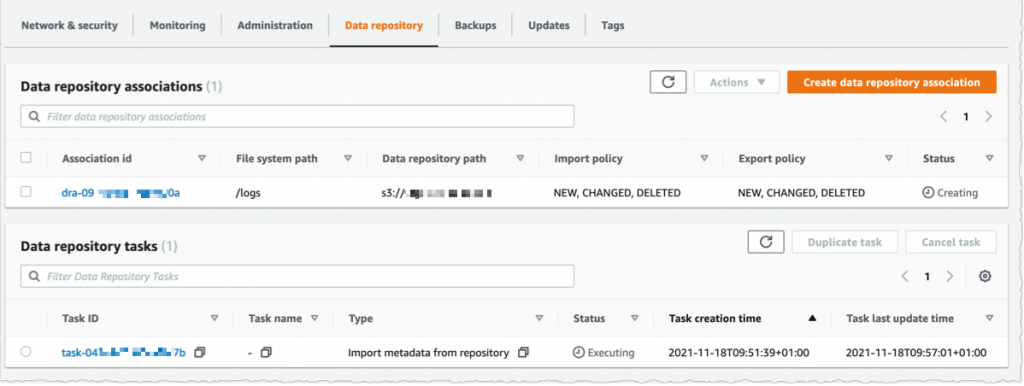
Utilizing the console, I see the record of Knowledge repository associations. I await the import job standing to develop into ✅ Succeeded. If I hyperlink the file system to an S3 bucket with a lot of objects, then I’ll select to skip Importing metadata from repository whereas creating the info repository affiliation, after which load metadata from chosen prefixes in my S3 buckets which might be required for my workload utilizing an Import job.
I create an EC2 occasion in the identical VPC subnet. Moreover, I be sure that the FSx for Lustre cluster safety group authorizes ingress visitors from the EC2 occasion. I take advantage of SSH to connect with the occasion, after which sort the next instructions (instructions are prefixed with the $ signal that’s a part of my shell immediate).
# examine kernel model, minimal model four.14.104-95.84 is required
$ uname -r
four.14.252-195.483.amzn2.aarch64
# set up lustre consumer
$ sudo amazon-linux-extras set up -y lustre2.10
Putting in lustre-client
...
Put in:
lustre-client.aarch64 zero:2.10.Eight-5.amzn2
Full!
# create a mount level
$ sudo mkdir /fsx
# mount the file system
$ sudo mount -t lustre -o noatime,flock fs-00...9d.fsx.us-east-1.amazonaws.com@tcp:/ny345bmv /fsx
# confirm mount succeeded
$ mount
...
172.zero.zero.zero@tcp:/ny345bmv on /fsx sort lustre (rw,noatime,flock,lazystatfs)
Then, I confirm that the file system incorporates the S3 objects, and I create a brand new file utilizing the contact command.
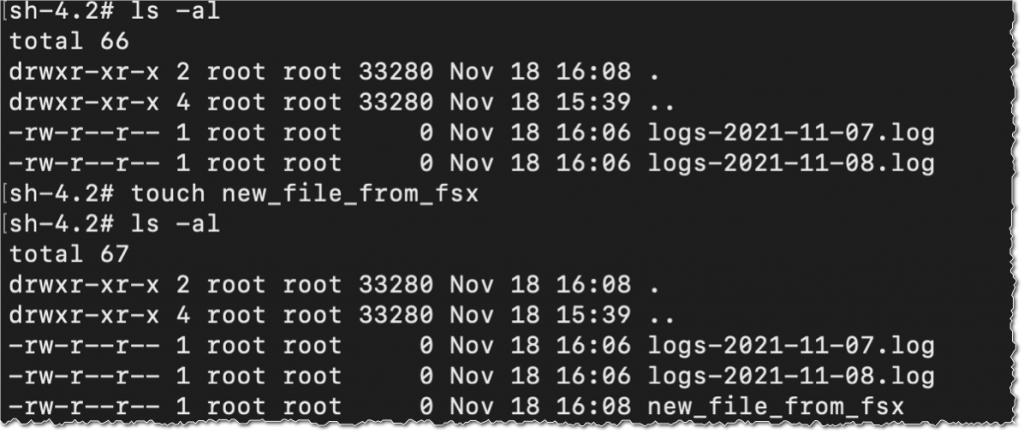
I change to the AWS Console, below S3 after which my bucket identify, and I confirm that the file has been synchronized.
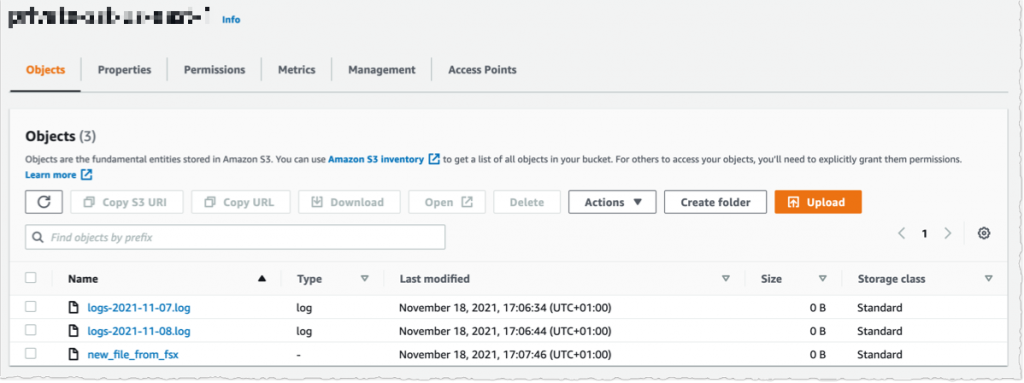
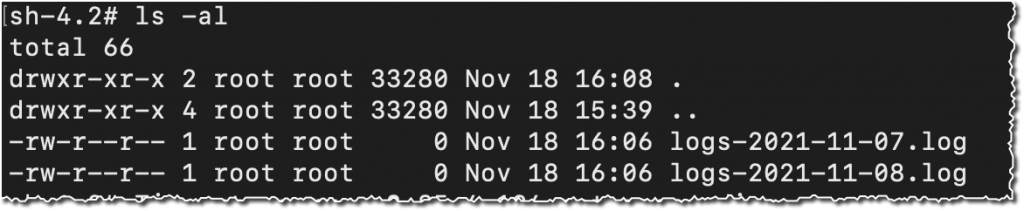
Utilizing the console, I delete the file from S3. And, unsurprisingly, after a couple of seconds, the file can also be deleted from the FSx file system.
Pricing and Availability
These new capabilities can be found at no further price on Amazon FSx for Lustre file programs. Automated export and a number of repositories are solely obtainable on Persistent 2 file programs in US East (N. Virginia), US East (Ohio), US West (Oregon), Canada (Central), Asia Pacific (Tokyo), Europe (Frankfurt), and Europe (Eire). Automated import with help for deleted and moved objects in S3 is out there on file programs created after July 23, 2020 in all areas the place FSx for Lustre is out there.
You’ll be able to configure your file system to robotically import S3 updates by utilizing the AWS Administration Console, the AWS Command Line Interface (CLI), and AWS SDKs.
Be taught extra about utilizing S3 knowledge repositories with Amazon FSx for Lustre file programs.
One Extra Factor
Yet another factor while you’re studying. As we speak, we additionally launched the following technology of FSx for Lustre file programs. FSx for Lustre next-gen file programs are constructed on AWS Graviton processors. They’re designed to give you as much as 5x increased throughput per terabyte (as much as 1 GB/s per terabyte) and scale back your price of throughput by as much as 60% as in comparison with earlier technology file programs. Give it a strive in the present day!
PS : my colleague Michael recorded a demo video to indicate you the improved S3 integration for FSx for Lustre in motion. Test it out in the present day.
[ad_2]
Source link

