
[ad_1]
Organizations at this time construct information lakes to course of, handle and retailer giant quantities of knowledge that originate from totally different sources each on-premise and on cloud. As a part of their information lake technique, organizations wish to leverage a number of the main OSS frameworks akin to Apache Spark for information processing, Presto as a question engine and Open Codecs for storing information akin to Delta Lake for the pliability to run wherever and avoiding lock-ins.
Historically, a number of the main challenges with constructing and deploying such an structure have been:
- Object Storage was not effectively fitted to dealing with mutating information and engineering groups spent lots of time in constructing workarounds for this
- Google Cloud supplied the advantage of working Spark, Presto and different styles of clusters with the Dataproc service, however one of many challenges with such deployments was the shortage of a central Hive Metastore service which allowed for sharing of metadata throughout a number of clusters.
- Lack of integration and interoperability throughout totally different Open Supply initiatives
To resolve for these issues, Google Cloud and the Open Supply neighborhood now gives:
- Native Delta Lake help in Dataproc, a managed OSS Large Knowledge stack for constructing an information lake with Google Cloud Storage, an object storage that may deal with mutations
- A managed Hive Metastore service known as Dataproc Metastore which is natively built-in with Dataproc for frequent metadata administration and discovery throughout several types of Dataproc clusters
- Spark three.zero and Delta zero.7.zero now permits for registering Delta tables with the Hive Metastore which permits for a standard metastore repository that may be accessed by totally different clusters.
Structure
Right here’s what an ordinary Open Cloud Datalake deployment on GCP would possibly include:
- Apache Spark working on Dataproc with native Delta Lake Assist
- Google Cloud Storage because the central information lake repository which shops information in Delta format
- Dataproc Metastore service performing because the central catalog that may be built-in with totally different Dataproc clusters
- Presto working on Dataproc for interactive queries
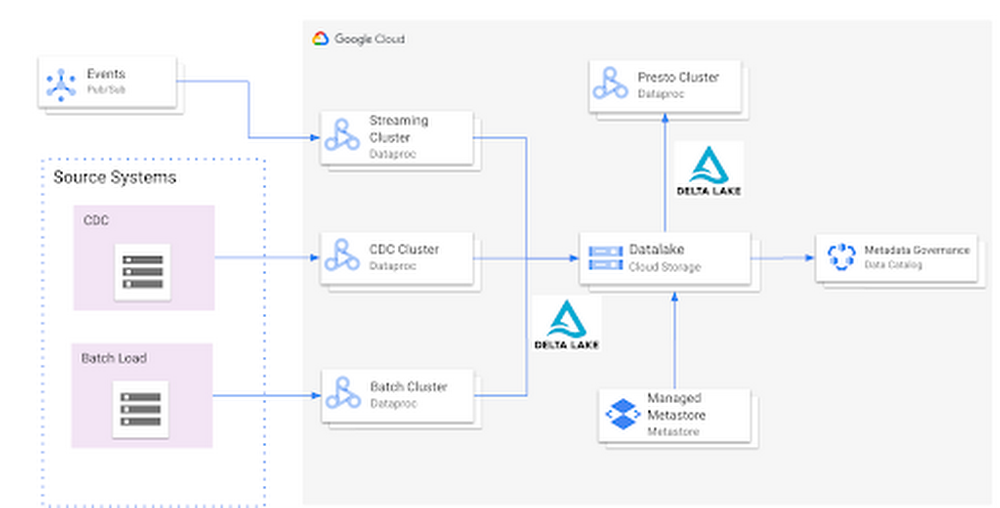
Such an integration supplies a number of advantages:
- Managed Hive Metastore service
- Integration with Knowledge Catalog for information governance
- A number of ephemeral clusters with shared metadata
- Out of the field integration with open file codecs and requirements
Reference implementation
Under is a step-by-step information for a reference implementation of establishing the infrastructure and working a pattern software
Setup
The very first thing we would want to do is ready up four issues:
- Google Cloud Storage bucket for storing our information
- Dataproc Metastore Service
- Delta Cluster to run a Spark Utility that shops information in Delta format
- Presto Cluster which can be leveraged for interactive queries
Create a Google Cloud Storage bucket
Create a Google Cloud Storage bucket with the next command utilizing a novel title.
Create a Dataproc Metastore service
Create a Dataproc Metastore service with the title “demo-service” and with model three.1.2. Select a area akin to us-central1. Set this and your venture id as surroundings variables.
Create a Dataproc cluster with Delta Lake
Create a Dataproc cluster which is linked to the Dataproc Metastore service created within the earlier step and is in the identical area. This cluster can be used to populate the info lake. The jars wanted to make use of Delta Lake can be found by default on Dataproc picture model 1.5+
Create a Dataproc cluster with Presto
Create a Dataproc cluster in us-central1 area with the Presto Elective Element and linked to the Dataproc Metastore service.
Spark Utility
As soon as the clusters are created we are able to log into the Spark Shell by SSHing into the grasp node of our Dataproc cluster “delta-cluster”.. As soon as logged into the grasp node the subsequent step is to start out the Spark Shell with the delta jar information that are already obtainable within the Dataproc cluster. The under command must be executed to start out the Spark Shell. Then, generate some information.
# Write Preliminary Delta format to GCS
Write the info to GCS with the next command, changing the venture ID.
# Be sure that information is learn correctly from Spark
Affirm the info is written to GCS with the next command, changing the venture ID.
As soon as the info has been written we have to generate the manifest information in order that Presto can learn the info as soon as the desk is created by way of the metastore service.
# Generate manifest information
With Spark three.zero and Delta zero.7.zero we now have the power to create a Delta desk in Hive metastore. To create the desk under command can be utilized. Extra particulars may be discovered right here
# Create Desk in Hive metastore
As soon as the desk is created in Spark, log into the Presto cluster in a brand new window and confirm the info. The steps to log into the Presto cluster and begin the Presto shell may be discovered right here.
#Confirm Knowledge in Presto
As soon as we confirm that the info may be learn by way of Presto the subsequent step is to take a look at schema evolution. To check this characteristic out we create a brand new dataframe with an additional column known as “z” as proven under:
# Schema Evolution in Spark
Swap again to your Delta cluster’s Spark shell and allow the automated schema evolution flag
As soon as this flag has been enabled create a brand new dataframe that has a brand new set of rows to be inserted together with a brand new column
As soon as the dataframe has been created we leverage the Delta Merge operate to UPDATE present information and INSERT new information
# Use Delta Merge Assertion to deal with computerized schema evolution and add new rows
As a subsequent step we would want to do two issues for the info to mirror in Presto:
- Generate up to date schema manifest information in order that Presto is conscious of the up to date information
- Modify the desk schema in order that Presto is conscious of the brand new column.
When the info in a Delta desk is up to date you should regenerate the manifests utilizing both of the next approaches:
- Replace explicitly: In spite of everything the info updates, you may run the generate operation to replace the manifests.
- Replace mechanically: You’ll be able to configure a Delta desk so that each one write operations on the desk mechanically replace the manifests. To allow this computerized mode, you may set the corresponding desk property utilizing the next SQL command.
Nevertheless, on this specific case we are going to use the specific methodology to generate the manifest information once more
As soon as the manifest file has been re-created the subsequent step is to replace the schema in Hive metastore for Presto to concentrate on the brand new column. This may be accomplished in a number of methods, one of many methods to do that is proven under:
# Promote Schema Adjustments by way of Delta to Presto
As soon as these adjustments are accomplished we are able to now confirm the brand new information and new column in Presto as proven under:
# Confirm adjustments in Presto
In abstract, this text demonstrated:
- Arrange the Hive metastore service utilizing Dataproc Metastore, spin up Spark with Delta lake and Presto clusters utilizing Dataproc
- Combine the Hive metastore service with the totally different Dataproc clusters
- Construct an finish to finish software that may run on an OSS Datalake platform powered by totally different GCP providers
Subsequent steps
In case you are inquisitive about constructing an Open Knowledge Platform on GCP please have a look at the Dataproc Metastore service for which the small print can be found right here and for particulars across the Dataproc service please check with the documentation obtainable right here. As well as, check with this weblog which explains intimately the totally different open storage codecs akin to Delta & Iceberg which might be natively supported throughout the Dataproc service.
[ad_2]
Source link
